OpenAI o1 научилась решать задачи математической Олимпиады, но по-прежнему не всегда умеет считать буквы в слове и определять какая десятичная дробь больше

Полу-милорд, полу-купец,
Пушкин, «На Воронцова»
Полу-мудрец, полу-невежда,
Полу-подлец, но есть надежда,
Что будет полным наконец.
На днях состоялось возможно самое главное событие этого года в ИИ-индустрии — релиз очередной модели OpenAI — o1. До этого многие месяцы ходили упорные слухи, что в компании разрабатывают технологию, при помощи которой большие языковые модели будут рассуждать, прежде чем выдавать ответ. Сначала её именовали Q* (по названию вполне реальной теоретической разработки, Q-Star), потом Strawberry. Причем в недавних утечках будущая модель OpenAI фигурировала под именем Orion — от которой, вероятно, в нынешнем названии осталась только буква «o». Впрочем, это вовсе не исключает грядущего релиза Orion, но об этом позже. А вот GPT-5, похоже, уже никогда не выйдет — в анонсе OpenAI o1 сообщается, что для сложных задач, связанных с рассуждениями, новая модель — «значительное достижение и представляет собой новый уровень возможностей ИИ». В связи с чем счетчик сбрасывается до 1.
Как сообщает OpenAI, серия o1 — это новые большие языковые модели, которые с помощью обучения с подкреплением натренированы для выполнения сложных рассуждений. Прежде чем ответить пользователю, o1 создает внутреннюю цепочку рассуждений (chain of thought). Судя по предварительным обзорам, пройдя первую цепочку рассуждений (подзаголовки которой отображаются пока модель думает), o1 может прийти к выводу о её ошибочности и выстроить новую последовательность умозаключений. Цепочка рассуждений, как и обучение с подкреплением, применяются и в других больших языковых моделях — судя по всему, особенной o1 делает конкретная реализация этих двух техник.
Сразу начну с не самых лучших новостей, вынесенных в заголовок — новая модель продолжает допускать нелепые ошибки — например, в ставших уже классическими вопросах какое число больше, 9.11 или 9.9, или сколько тех или иных букв в слове strawberry. Не всегда, конечно — o1 отвечает на эти вопросы как правильно, так и неправильно, и последнее подтверждается не только многочисленными скриншотами обычных пользователей, но и известным блогером, который сделал предварительный обзор новой модели. В какой-то мере это признает и сама OpenAI — в заявленных ею результатах o1 не только не превосходит GPT-4o в некоторых бенчмарках, не связанных с точными и естественными науками, но даже немного уступает ей (например, в бенчмарке Personal Writing).
Что касается непосредственно математических вопросов, в которых o1 периодически допускает нелепые ошибки (отвечая, после нескольких секунд размышления, что 9.11 больше, чем 9.9), то возможно это связано с так называемой температурой модели — она установлена на 1. Значения меньше 1 делают ответы более логичными и точными, больше 1 — более разнообразными и творческими. Вероятно для o1 установленное значение «1» привносит в ответы разнообразие, проявляемое в ответах даже на такие простые вопросы.

В этом отношении LLM напоминают автопилот, который может часами безупречно ехать по сложному маршруту, но в какой-то момент въехать в столб на обочине. Как мы уже говорили, в этом смысле одинаково справедливо как сделанное главой Anthropic (Claude 3.5 Sonnet) сравнение LLM с новоиспеченным выпускником колледжа, так и утверждение главы Google DeepMind, что современный ИИ не дотягивает даже до кошки. И хотя от кошки мы не ожидаем решения даже простенькой математической задачи, неспособность решить её все же не позволяет сравнить ИИ с человеком — даже если этот ИИ решает гораздо более сложные задачи, непосильные для среднего человека.
Что касается улучшений в целом, то они действительно впечатляют. Новая модель фактически убила старые бенчмарки — они для неё слишком простые. Теперь OpenAI тестирует свою модель и на куда более сложных тестах: задачах школьной математической олимпиады США (AIME, включает элементарную алгебру, геометрию, тригонометрию, теорию чисел, теорию вероятности и комбинаторику) и сборнике задач по спортивному программированию (Codeforces). Также были выложены результаты по уже использовавшемуся бенчмарку, GPQA — сборнику тестов по физике, химии и биологии. Вот какие, согласно OpenAI, были получены результаты (в скобках — результаты вышедшей вчера тестовой версии o1):
| GPT-4o | o1 | человек экспертного уровня | |
| AIME | 13.4% | 83.3% (56.7%) | 83% 1 |
| Codeforces | 11% | 89% (62%) | 86% 2 |
| GPQA | 56% | 78% (78.3%) | 69.7% |
1 Мы рассчитали процент самостоятельно — как соотношение между 5% лучших результатов и 1% лучших результатов (источник)
2 Уровень «эксперта» (источник)
Согласитесь, что такие результаты можно признать выдающимися — сразу появилась модель, которая в несколько раз умнее своего предшественника в математике и программировании, а также значительно улучшилась в естественных науках, номинально превзойдя в них уровень людей со степенью PhD. С учетом упомянутых выше нелепых ошибок, неизбежных галлюцинаций и отсутствия агентности (способности действовать самостоятельно) это конечно ни в коей мере не означает способности o1 заменить программистов или специалистов в области точных и естественных наук. Но уже сейчас можно смело утверждать, что их производительность благодаря таким системам резко возрастет. Можно было бы предположить, что компании сократят набор начинающих специалистов, или даже вовсе от него откажутся, но скорее последствия будут другими. Более вероятно, что молодые специалисты смогут устроиться на работу только при условии, что они хорошо владеют инструментариями вроде o1. Условно, тот, кто раньше нанимался на позицию младшего специалиста теперь станет выполнять функции старшего специалиста, которому придан в помощь крайне исполнительный и трудоспособный младший — в лице o1 или его будущих аналогов.
При этом оценки и впечатления пользователей от o1 могут сильно различаться — от восторженных до разочарованных. В первом случае o1 успешно решила несколько довольно сложных задач из учебника Дж. Джексона «Классическая электродинамика», все четыре специально под неё придуманные новые задачи по физике, а также с шести подсказок и уточнений написала рабочий код программы моделирования астрофизических процессов, над которой автор YouTube-канала (по специальности физик, а не программист) работал в течение нескольких месяцев. Исходник ранней версии этой программы выкладывался в открытый доступ — и поэтому, вместе с вышеупомянутым учебником по физике, вполне мог попасть в обучающий дата-сет o1. Но с тем же успехом он мог попасть и в обучающие дата-сеты других моделей — которые, несмотря на это, с подобными задачами не справляются. И поскольку подобных примеров немало, а обучающий дата-сет у o1 такой же, что и у GPT-4o, цепочка рассуждений явно способствует решению задач.
А вот какие впечатления получил от общения с o1 выдающийся математик Теренс Тао:
Это, безусловно, более способный инструмент, чем предыдущие итерации, хотя он все еще испытывает затруднения с наиболее продвинутыми исследовательскими математическими задачами.
Я повторил эксперимент, в котором попросил модель ответить на нечетко сформулированный математический запрос, который можно было решить, найдя подходящую теорему (теорему Крамера) из литературы. Ранее GPT мог упомянуть некоторые соответствующие понятия, но детали были галлюцинаторным бредом. На этот раз теорема Крамера была найдена, и был дан вполне удовлетворительный ответ.
В другом эксперименте я задал новой модели сложную задачу комплексного анализа. Здесь результаты были лучше, чем у предыдущих моделей, но все равно слегка разочаровывали: новая модель могла прийти к правильному (и хорошо написанному) решению, если ей давали много подсказок и подталкивали, но она не генерировала ключевые концептуальные идеи самостоятельно и допускала некоторые нетривиальные ошибки. Ощущения были примерно такими же, как при попытке проконсультировать посредственного, но не совсем некомпетентного аспиранта. Однако это уже улучшение по сравнению с предыдущими моделями, возможности которых были ближе к действительно некомпетентному аспиранту. Возможно, потребуется еще одна или две итерации улучшения возможностей (и интеграции с другими инструментами, такими как пакеты компьютерной алгебры и ассистенты доказательств), пока не будет достигнут уровень «компетентного аспиранта», и тогда я смогу увидеть, что этот инструмент может быть полезен для решения задач исследовательского уровня.
В качестве третьего эксперимента я попросил новую модель приступить к задаче формализации результата в Lean (в частности, установить одну форму теоремы о простых числах как следствие другой), разбив её на подлеммы, для которых она формализует утверждение, но не доказательство. Здесь результаты были многообещающими: модель хорошо поняла задачу и провела разумное начальное разбиение проблемы, но в процессе обучения ей помешало отсутствие актуальной информации о Lean и математической библиотеке, а её код содержал несколько ошибок. Однако я могу представить, что модель такого уровня, специально настроенная на Lean и Mathlib и интегрированная в IDE, будет чрезвычайно полезна в проектах по формализации.
Учитывая интерес к этим сообщениям, я решил поделиться некоторыми другими небольшими экспериментами, которые я также проводил с моим предварительным вариантом модели. В 2010 году я искал правильную терминологию для «мультипликативного интеграла», но не смог найти ее в поисковых системах того времени. Поэтому я задал вопрос на MathOverflow и получил удовлетворительные ответы от экспертов-людей. Я задал идентичный вопрос o1, и она вернула идеальный ответ. Разумеется, приведенный выше пост MathOverflow мог быть включен в обучающие данные модели, так что это не всегда является точной оценкой её возможностей семантического поиска (в отличие от первого примера, о котором я уже упоминал ранее на Mastodon, но без полного раскрытия ответа). Тем не менее он демонстрирует, что этот инструмент находится на одном уровне с сайтами вопросов и ответов в отношении высокого качества ответов по крайней мере на некоторые семантические поисковые запросы.
В качестве еще одного небольшого эксперимента я дал o1 первую половину моей недавней записи в блоге, где я кратко изложил состояние прогресса в решении проблемы Эрдоса, которую мне удалось решить, и попросил модель найти недостающий ингредиент, необходимый для преобразования предыдущего частичного прогресса в полное решение проблемы. Здесь результат оказался мягко говоря неутешительным. По сути, модель предложила ту же стратегию, которая уже была выявлена в последних работах по этой проблеме (и которую я изложил в этой записи в блоге), но не предложила никаких творческих вариантов этой стратегии. В целом я считаю, что, несмотря на некоторую возможность случайной генерации креативных стратегий, этот аспект инструментов LLM все еще довольно слаб.
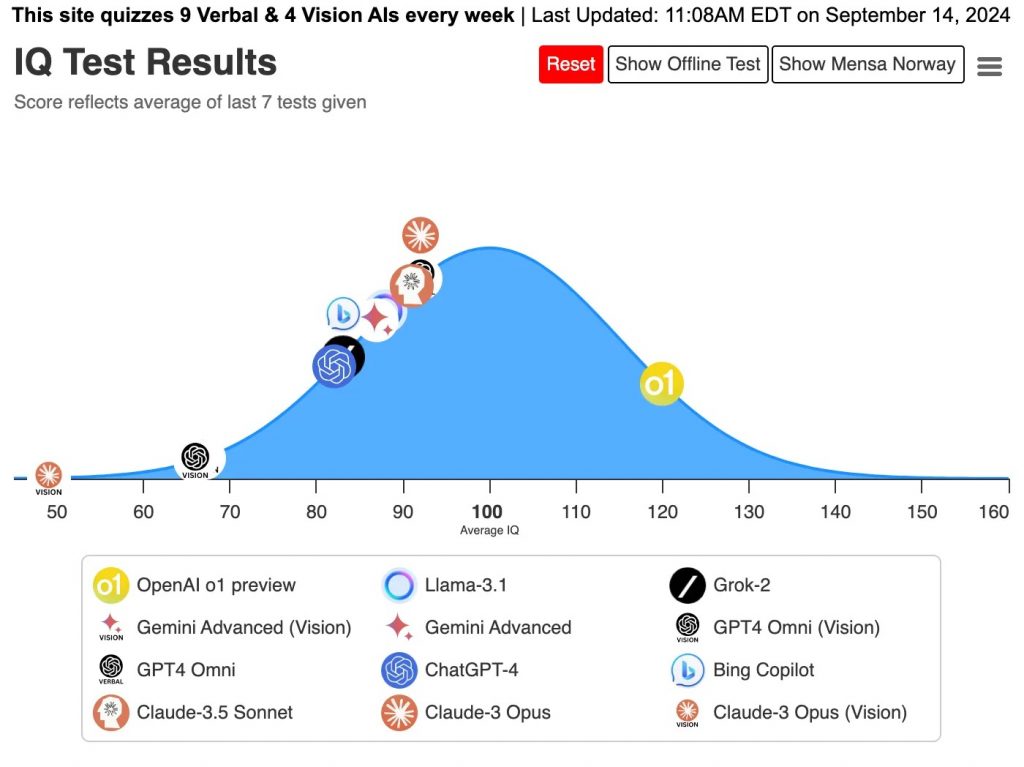
В классическом IQ-тесте o1 набирает 120 баллов — заметно больше, чем у остальных моделей и у человека в среднем (90-100 баллов). В модифицированной версии этого теста, состоящей из новых вопросов, которых не должно быть в обучающем дата-сете, результаты хуже, но все равно значительно лучше предшественника и конкурентов.
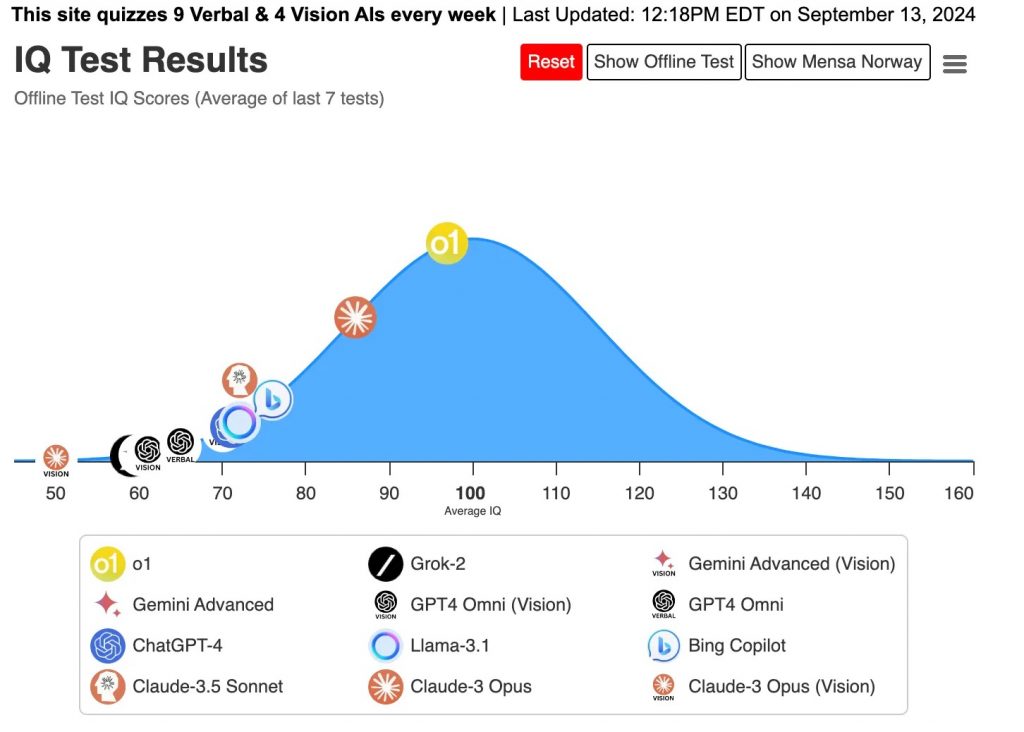
По мнению автора обновленного IQ-теста, «в 2026 году мы должны увидеть, как искусственный интеллект преодолеет отметку IQ в 140».
Автор популярного YouTube-канала AI Explained, разработавший собственный бенчмарк, Simple, протестировал на нем o1 и получил результат в 50% — при том, что лучший результат до этого принадлежал Claude 3.5 Sonnet (27%), а средний уровень человека — 92%. В более известном бенчмарке, ARC-AGI (который разработавший его Франсуа Шолле, создатель библиотеки глубокого обучения Keras, выпущенной в 2015, считает самым релевантным для оценки настоящего, способного решать новые задачи, интеллекта) результаты o1 куда скромнее — 21%. Это значительно больше, чем у GPT-4o (9%), но на одном уровне с Claude 3.5 Sonnet. При этом самый лучший на сегодня результат в ARC-AGI — 46% (MindsAI). Подобно Райану Гринблатту, о котором Gadgets News уже рассказывал (у него 42%), MindsAI не сам решает тестовые задачи, а на базе LLM пишет программу, которая решает задачи. Таким образом, с точки зрения результатов в ARC-AGI способность o1 рассуждать все еще сильно не дотягивает до уровня человека. Авторы бенчмарка объясняют это так:
[предположительно] o1 по-прежнему работает в основном в пределах распределения своих предварительных обучающих данных, но теперь включает все вновь созданные синтетические CoT (цепочки рассуждений).
Дополнительные синтетические данные CoT усиливают фокусировку на распределении CoT, а не только на распределении ответов (больше вычислений тратится на то, как получить ответ, а не на то, что является ответом). Мы ожидаем, что такие системы как o1 покажут лучшие результаты в тестах, включающих повторное использование известных эмулированных шаблонов рассуждений (программ), но им все равно будет трудно решать проблемы, требующие синтеза совершенно новых рассуждений на лету.
Тестовое уточнение на CoT пока может только исправить ошибки рассуждений. Это также объясняет, почему o1 так впечатляет в определенных областях. Тестовое уточнение на CoT получает дополнительный импульс, когда базовая модель предварительно обучена аналогичным образом.
Подводя итог, можно сказать, что o1 представляет собой смену парадигмы от «запоминания ответов» к «запоминанию рассуждений», но не является отходом от более широкой парадигмы подгонки кривой к распределению с целью повышения производительности за счет размещения всего внутри распределения.
Нам по-прежнему нужны новые идеи для AGI.
Является ли o1 правильным шагом в сторону создания AGI, интеллекта человеческого уровня? Очень вероятно, что да. Теперь уже не скажешь, что ответы выдает «стохастический попугай» — с функциональной точки зрения большая языковая модель рассуждает. Если она рассуждала и раньше (см. про применение цепочки рассуждений в других моделях), то в случае o1 налицо качественное улучшение этой способности. Понимает ли при этом o1 то, о чем рассуждает — вопрос скорее философский, упирающийся в вопрос о том, что есть понимание. С функциональной точки понимание, пусть далеко и не идеальное, безусловно присутствует. Налицо действительно успешное сочетание больших языковых моделей и обучения с подкреплением — подобно тому, как это было реализовано в AlphaProof для решения задач международной математической олимпиады. Для больших языковых моделей это означает новые перспективы развития ИИ, помимо масштабирования моделей и обучающего дата-сета.
Чего же ожидать в ближайшее время? Для начала, вероятно, релиза полноценной версии 01 — сейчас, напомню, подписчикам платного сервиса доступна preview-версия o1, которая, согласно OpenAI, в бенчмарках показывает себя заметно хуже полноценной версии. Бесплатным пользователям обещана 01-mini — по предварительным отзывам она заметно хуже, чем 01-preview, но согласно самой OpenAI mini-версия o1 лучше справляется со STEM-задачами и программированием (утверждается, что она может обрабатывать более длинные цепочки рассуждений). В будущих версиях o1 обещаны более длинное контекстное окно и управление временем, которое модель выделяет на обдумывание.
И напоследок о букве «о» в названии новой модели. Может показаться, что o1 — это и есть та самая Orion, о которой ходили слухи, но похоже релиз Orion также состоится. Вот что написал на днях Сэм Олтмен в Твиттере:
Мне нравится быть дома на Среднем Западе. Ночное небо такое красивое. Я рад, что скоро появятся зимние созвездия, они такие замечательные.
Поскольку Орион — это название созвездия, то вполне вероятно, что зимой 2024-2025 нас ожидает новый релиз — на этот раз гораздо более крупной модели, с более качественной реализацией рассуждений из o1 и голосового интерфейса из GPT-4o. Говоря о созвездиях во множественном числе, Олтмен скорее всего подразумевает традиционное дополнение базовой версии mini-версией, но нельзя также исключать и релиза каких-то новых моделей. Примечательно, что модель Google, Gemini (Близнецы), также названа в честь созвездия. Образно говоря, небо искусственного интеллекта на наших глазах покрывается новыми созвездиями.
Открылась бездна, звезд полна
Звездам числа нет, бездне дна…
Ломоносов, «Вечернее размышление о Божием величестве»