Хроники ИИ: релиз Gemini 2.5 Flash, Qwen 3, o3 и o4-mini, анонс Grok-3.5, TPU Ironwood и фотонного процессора Lightmatter

В апреле состоялся релиз еще нескольких интересных ИИ-моделей. Главные из них — это, пожалуй, полноценная o3 и уменьшенная версия reasoning-модели следующего поколения, o4-mini (OpenAI). В общем и математическом рейтинге Chatbot Arena, составленном по отзывам пользователей, o3 заняла 2-е место после Gemini 2.5 Pro. Результаты o4-mini в общем зачете значительно скромнее — 12-е место, зато в математике у неё 3-е место. В программировании o3 получила первенство, опередив Gemini 2.5 Pro (у o4-mini — 8-е место).
Что касается результатов, представленных непосредственно OpenAI, то практически во всех бенчмарках её новые модели значительно лучше своих предшественников, o1 и o3-mini. Особенно это касается программирования — в SWE-Bench Verified результаты o3 и o4-mini выросли с 49% до 68-69%.
В свою очередь в USAMO 2025 (математическая олимпиада) o3 и o4-mini приблизились к Gemini 2.5 Pro (22% и 19% против 24%), в Humanity’s Last Exam модель o3 даже заняла 1-е место (20.3%), немного опередив Gemini 2.5 Pro (18.4%) и o4-mini (18.1%). Аналогично в SimpleBench — o3 набирает 53.1% против 51.6% у Gemini 2.5 Pro (o4-mini — 38.7%, o3-mini — 22.8%).
В апреле список сложных бенчмарков пополнился еще одним — PHYBench. Он состоит из 500 тщательно подобранных задач по физике, основанных на реальных физических сценариях, разработанных для оценки способности моделей понимать и рассуждать о реалистичных физических процессах. Охватывая механику, электромагнетизм, термодинамику, оптику, современную физику и продвинутую физику, эталон охватывает уровни сложности от школьных заданий до задач для студентов и олимпиадных задач по физике. Как видим, все три топовые модели (Gemini 2.5 Pro, o3 и o4-mini) демонстрируют в этом бенчмарке достаточно скромные результаты: 37%, 35% и 30% соответственно против 62% в среднем у физиков.
Кстати, на днях вышла со статья с критикой популярного рейтинга Chatbot Arena, который мы упомянули выше — и ответ на неё со стороны авторов рейтинга.
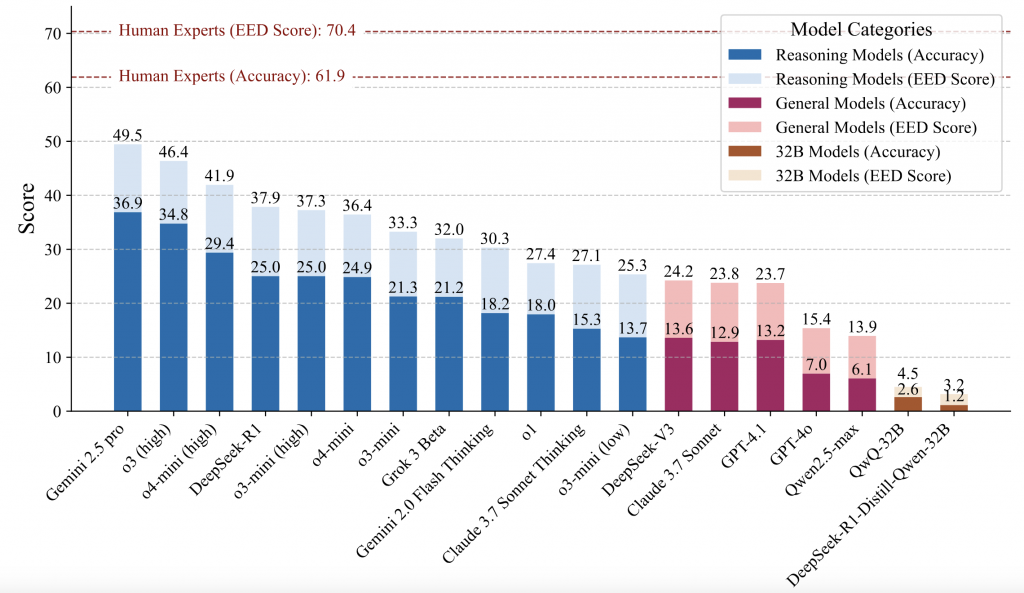
Но если динамика развития ИИ позволяет надеяться на улучшение результатов даже в таких сложных бенчмарков, все больше сомнений возникает в надежности нынешних моделей. Согласно самой OpenAI, в бенчмарке PersonQA, провоцирующем модель на галлюцинации, o3 и o4-mini соответственно вдвое и втрое хуже, чем o1 — 33% и 48% против 16%. И что больше всего удручает, в OpenAI не знают почему так получилось — там признаются, что для понимания причины требуются дополнительные исследования. Очевидно, что при таком ужасающе низком уровне надежности о полноценном пользовании ИИ не может быть и речи — тем более удивительно, что в индексе готовности AGI за апрель прибавились еще два процента, и теперь он составляет 94%.
В числе других интересных релизов этого месяца — дистиллированная версия Gemini 2.5 Pro, Gemini 2.5 Flash. Это своего рода ответ китайцам, чья DeepSeek R1 наделала столько шуму благодаря своей беспрецедентно низкой стоимости. Gemini 2.5 Flash превосходит её в бенчмарках, и при этом соразмерна по стоимости:
| Gemini 2.5 Flash | Gemini 2.5 Pro | DeepSeek-R1 | o3 | 04-mini | GPT-4.52 | |
| Загрузка 1 млн токенов | $0.15 | $1.25 / $2.501 | $0.55 | $10.00 | $1.10 | $75.003 |
| Выгрузка 1 млн токенов | $3.50 | $10.00 / $15.001 | $2.19 | $40.00 | $4.40 | $150.00 |
1 в зависимости от размера промпта 2 не оснащена reasoning
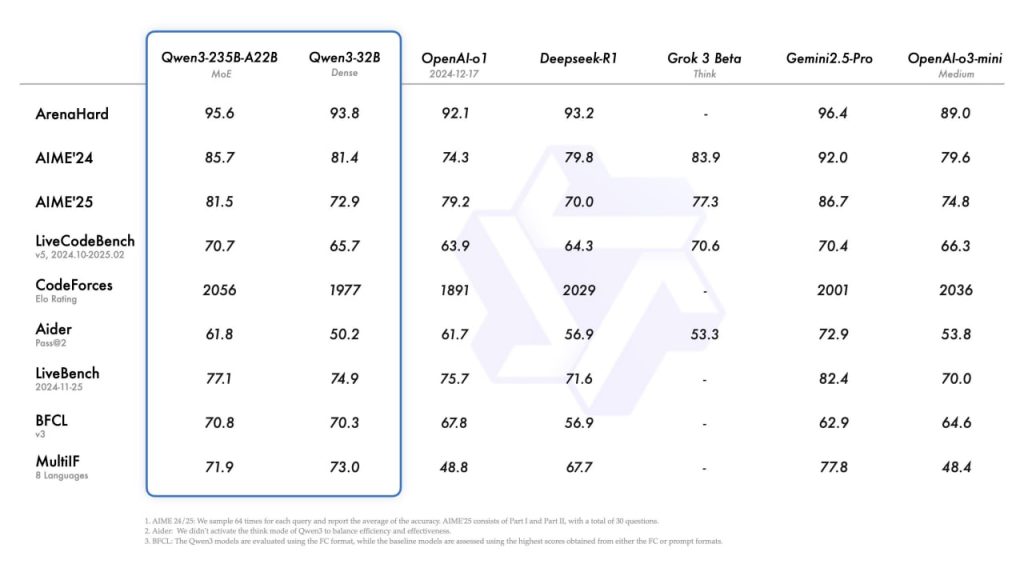
3 расценки на все модели OpenAI см. здесьТакже в апреле вышло новое поколение опенсорсной модели, разработанной Alibaba — Qwen 3. В некоторых бенчмарках её результаты сопоставимы даже с лучшей на сегодня моделью, Gemini 2.5 Pro:
Ну и наконец на днях Илон Маск объявил, что на следующей неделе состоится ограниченный релиз бета-версии Grok-3.5. По словам предпринимателя, «это первый ИИ, который может, например, точно отвечать на вопросы о ракетных двигателях или по электрохимии», при этом она сможет отвечать на вопросы, информация по которым в Интернете отсутствует.
В заключение про модели — еще одна, помимо растущих галлюцинаций, негативная новость. На днях вышла работа, авторы которой утверждают, что обучение с подкреплением не порождает принципиально новых рассуждений. По мнению исследователей, это требует от нас фундаментального переосмысления влияния обучения с подкреплением на рассуждения больших языковых моделей и поиска новых подходов.
В отличие от новых моделей, новое аппаратное обеспечение для ИИ выходит нечасто, и в апреле как раз состоялся один из таких редких анонсов. Компания Google представила свой TPU (тензорное процессорное устройство) 7-е поколения, Ironwood. Чип позиционируется для инференса (обработки пользовательских запросов). Как обычно, Google избегает прямых сравнений своего продукта с предшественником по всем параметрам — нам пришлось искать их по крупицам и делать расчеты. Вот как по результатам наших усилий выглядят сравнительные характеристики Ironwood:
| Ironwood (апрель 2025) | Trillium (декабрь 2024) | |
| Пиковая производительность на 1 Вт (FP8) | 29.3 TFLOPS | 14.6 TFLOPS 1 |
| Пиковая производительность общая (FP8) | 4614 TFLOPS | 923 TFLOPS 2 |
| Энергопотребление | 157 Вт 3 | 63 Вт 3 |
2 Ironwood offers five times more peak compute capacity … compared to the prior-generation TPU (источник)
3 Общая производительность делится на производительность на 1 Вт
Предположительно речь идет о производительности в обычных, а не разреженных матрицах (в которых производительность обычно вдвое выше). Таким образом, графический ускоритель Ironwood имеет производительность в 4.6 петафлопс (FP8) при энергопотреблении 157 Вт. Для сравнения, имеющий аналогичную производительность (5 петафлопс) чип Nvidia B200 (Blackwell) потребляет около 1 КВт электроэнергии, что в 6 раз превышает энергопотребление Ironwood. Вероятно это объясняется тем, что ТПУ Ironwood является специализированным процессором, заточенным под тензорные вычисления. Вычислительный кластер из Ironwood масштабируется до 9,216 чипов общей производительностью 42.5 EFLOPS (экзафлопс).

Еще один интересный анонс касается нового и весьма перспективного направления вычислительной техники. Стартап Lightmatter представил фотонный процессор, который выполняет 65.5 трлн операций в формате ABFP в секунду, потребляя всего 78 Вт электрической мощности и 1.6 Вт оптической мощности. Формат ABFP (Adaptive Block Floating Point) был предложен сотрудниками компании еще в препринте 2022 года, и, как утверждается, обеспечивает потерю точности всего в 1% по сравнению с форматом FP32. Для сравнения, упомянутое выше ГПУ Nvidia B200, которое потребляет около 1 КВт электроэнергии, имеет производительность 90 терафлопс (триллионов операций в секунду) FP32. Соответственно, фотонный процессор Lightmatter имеет на 27% меньшую производительность, потребляя в 12 раз меньше электроэнергии.
Еще более очевидным представляется перспективность применения фотоники в соединении чиплетов, процессоров и серверов. По словам CEO и со-основателя Lightmatter Николаса Харриса, за последние 30 лет производительность процессоров выросла в миллион раз, тогда как скорость межпроцессорных соединений — только в тысячу раз. Эта проблема особенно актуальна сейчас, во время гонки за создание еще более умных ИИ-моделей — фактически она сводится к развертыванию всё более крупных дата центров. Например, «похороненная» на днях модель GPT-4 обучалась, по слухам, на 25 тыс графических ускорителей Nvidia A100 (2020), а компания Илона Маска xAI уже располагает кластером Colossus в 200 тыс ГПУ, планируя в будущем довести это число до 1 млн. В этих условиях критически важное значение обретает скорость передачи данных между процессорами, между процессорами и оперативной памятью, между серверами дата-центров. Фотонно-электронный модуль Lightmatter, L200, обеспечивает пропускную способность в 1.5 Тбит/с на миллиметровое волокно, достигая 256 Тбит/с на один процессор (пакет XPU, т.е. вычислительный блок, в качестве которого выступает высокопроизводительное ЦПУ, ГПУ и ТПУ сервера). Согласно Николасу Харрису, это в 18 раз больше, чем в лучших на сегодня решениях. Поставки L200 запланированы через год, во 2-м кв 2026.