Большие языковые модели от OpenAI и Google DeepMind взяли золото на Международной математической олимпиаде

Позавчера OpenAI объявила, что её новейшая экспериментальная большая языковая модель общего назначения взяла золото на международной математической олимпиаде, International Mathematical Olympiad (IMO) 2025, решив 5 из 6 задач и набрав 35 из 42 очков. Вот что об этом пишет Алекс Вэй (Alex Wei), научный сотрудник OpenAI, работающий над LLM и рассуждениями — он возглавляет команду, разработавшую технологию, которая лежит в основе новой модели:
Рад сообщить, что наша новейшая экспериментальная рассуждающая LLM решила давнюю и амбициозную задачу в области ИИ: достигла результата уровня золотой медали на самой престижной в мире математической олимпиаде — Международной математической олимпиаде (IMO).
Мы оценивали наши модели на задачах IMO 2025 года по тем же правилам, что и для участников-людей: две сессии экзамена по 4.5 часа, без инструментов или Интернета, читая официальные условия задач и записывая доказательства на естественном языке.
Почему это так важно? Во-первых, задачи IMO требуют нового уровня продолжительного творческого мышления по сравнению с прошлыми бенчмарками. По времени, необходимому для рассуждений, мы продвинулись от GSM8K (около 0.1 минуты для лучших людей) → бенчмарка MATH (около 1 минуты) → AIME (около 10 минут) → IMO (около 100 минут).
Во-вторых, решения задач IMO — это сложные, многостраничные доказательства, которые трудно проверить. Прогресс в этой области требует выхода за рамки парадигмы обучения с подкреплением (RL), основанной на четких и проверяемых вознаграждениях. Благодаря этому мы получили модель, способную создавать сложные, безупречные аргументы на уровне человека-математика.
Помимо самого результата, я в восторге от нашего подхода: мы достигли такого уровня возможностей не с помощью узкоспециализированной методологии, а открывая новые горизонты в области универсального обучения с подкреплением и масштабирования вычислений во время тестирования.
В ходе нашей оценки модель решила 5 из 6 задач на IMO 2025. Для каждой задачи трое бывших медалистов IMO независимо оценивали представленное моделью доказательство, а окончательные оценки выставлялись после достижения единогласного консенсуса. Модель набрала 35/42 баллов, что достаточно для золотой медали!
Кстати, скоро мы выпускаем GPT-5, и нам не терпится дать вам его попробовать. Но чтобы внести ясность: LLM, завоевавшая золото на IMO, — это экспериментальная исследовательская модель. Мы не планируем выпускать что-либо с таким уровнем математических способностей в течение нескольких месяцев.
И все же — это подчеркивает, как быстро развивался ИИ в последние годы. В 2021 году мой научный руководитель попросил меня спрогнозировать прогресс ИИ в математике к июлю 2025 года. Я предсказал 30% на бенчмарке MATH (и думал, что все остальные слишком оптимистичны). А вместо этого мы получили золото на IMO.

Любопытно, что аналогичного результата достигла и «продвинутая версия Gemini Deep Think», также решившая 5 из 6 задач и также набравшая 35 баллов. Причем в отличие от OpenAI, результаты, полученные моделью DeepMind, были официально оценены и сертифицированы координаторами IMO по тем же критериям, что и для студенческих решений.
Вот что об этом говорится в официальном блоге DeepMind:
На IMO 2024 AlphaGeometry и AlphaProof потребовали от экспертов сначала перевести задачи с естественного языка на языки предметной области, такие как Lean, и наоборот для доказательств. Кроме того, вычисления заняли два-три дня. В этом году наша усовершенствованная модель Gemini работала от начала до конца на естественном языке, создавая строгие математические доказательства непосредственно из официальных описаний задач — и всё это в рамках отведённого на соревнование времени, составляющего 4.5 часа.
…
В этом году мы достигли результата, используя продвинутую версию Gemini Deep Think — расширенный режим рассуждений для решения сложных задач, включающий некоторые из наших новейших исследовательских методов, включая параллельное мышление. Такая конфигурация позволяет модели одновременно исследовать и комбинировать несколько возможных решений, прежде чем дать окончательный ответ, а не следовать единой линейной цепочке рассуждений.
Чтобы максимально эффективно использовать возможности Deep Think в области рассуждений, мы дополнительно обучили эту версию Gemini новым методам обучения с подкреплением, которые позволяют использовать больше данных для многошаговых рассуждений, решения задач и доказательства теорем. Мы также предоставили Gemini доступ к тщательно отобранному корпусу высококачественных решений математических задач и добавили в инструкции несколько общих советов и рекомендаций по решению задач ИМО.
К этому можно добавить комментарий Тана Луонга (Thang Luong), старшего научного сотрудника Google DeepMind:
В этом году произошел серьезный сдвиг парадигмы, когда мы можем решать задачи от конца до конца на естественном языке. С помощью новых методов обучения с подкреплением мы смогли обучить усовершенствованную модель Gemini на данных, подтверждающих многоступенчатые рассуждения, что расширило возможности модели в плане генерации длинных ответов. В сочетании с мощью модели Deep Think, позволяющей модели думать параллельно и дольше, в случае с IMO этого года — 4,5 часа, мы можем решить безупречно пять задач из шести!
В DeepMind подчеркивают, что «наш подход с Gemini был основан исключительно на естественном языке», но обещают продолжить работу и над формальными системами AlphaGeometry и AlphaProof. Таким образом, в очередной раз посрамлен Ян Лекун большие языковые модели доказали свой огромный потенциал и оправдали возложенные на них надежды.
Решить задачи IMO 2025 с гораздо более скромным результатом попытались и публично доступные модели — Gemini 2.5Pro (32%), o3 (17%), o4-mini (14%), Grok-4 (12%) и Deepseek-R1 (7%).
До сих пор лучшего результата сумели добиться, в прошлом году, две специализированные модели компании Google DeepMind, AlphaGeometry 2 (решила единственную геометрическую задачу) и AlphaProof (решила две алгебраические задачи и одну задачу по теории чисел). Тогда система DeepMind набрала 28 из 42 баллов, недобрав один балл до золотой медали (каждый год количество баллов для золотой медали определяется в индивидуальном порядке — тогда было 29 баллов, в этом году — 35 баллов). Причем если на олимпиаде у студентов на решение шести задач отводится 9 часов (две сессии по 4.5 часа), то тогдашнее детище DeepMind задачу по геометрии решало 19 секунд (после получения её в формализованном виде), одну задачу — за несколько минут, и две остальные — аж до трех дней:
| OpenAI Google DeepMind (2025) | Google DeepMind (2024) | |
| Состав | Большая языковая модель общего назначения, с рассуждением | AlphaGeometry сочетает 1) большую языковую модель и 2) основанный на правилах формальной логики механизм символьного вывода, работающие в тандеме для поиска решений AlphaProof сочетает 1) предобученную языковую модель Gemini, которая перевела с естественного языка на формальный язык Lean миллионы математических задач, и 2) алгоритм обучения с подкреплением AlphaZero |
| Время решения | несколько часов | 3 дня |
| Результат | 35 из 42 баллов (83%) | 28 из 42 баллов (67%) |
Вот как результаты OpenAI комментирует другой сотрудник OpenAI, Ноам Браун (Noam Brown):
Обычно для достижения таких результатов ИИ, как в Go/Dota/Poker/Diplomacy, исследователи тратят годы на создание ИИ, который овладевает одной узкой областью и не делает ничего другого. Но это не модель, ориентированная на ИМО. Это рассуждающий LLM, который включает в себя новые экспериментальные техники общего назначения.
Что же изменилось? Мы разработали новые методы, которые позволяют LLM гораздо лучше справляться с труднопроверяемыми задачами. Задачи IMO стали идеальным вызовом для этого: доказательства занимают много страниц, и экспертам требуются часы для их оценки. Сравните это с AIME, где ответы — это просто целое число от 0 до 999.
Также эта модель думает *долго*. o1 думает несколько секунд. Deep Research — несколько минут. Эта модель думает часами. Важно, что она также более эффективна в своих размышлениях. И есть много возможностей для дальнейшего развития вычислений и эффективности в тестовом времени.
Стоит задуматься о том, насколько быстрым был прогресс ИИ, особенно в математике. В 2024 году лаборатории ИИ использовали математику начальной школы (GSM8K) в качестве оценки при выпуске своих моделей. С тех пор мы достигли эталона MATH (средняя школа), затем AIME, а сейчас находимся на уровне золотого медалиста IMO.
К чему это приведет? Как бы быстро ни развивался ИИ в последнее время, я вполне допускаю, что эта тенденция сохранится. Важно отметить, что, на мой взгляд, мы близки к тому, чтобы ИИ внес существенный вклад в научные открытия. Существует большая разница между ИИ, который находится чуть ниже уровня человеческой производительности, и тем, который находится чуть выше.
Это была работа небольшой команды под руководством Алекса Вэй (см. выше). Он взял исследовательскую идею, в которую мало кто верил, и использовал ее для достижения результата, который мало кто считал возможным. Это также было бы невозможно без многолетних исследований и инженерных разработок многих людей в OpenAI и более широком сообществе ИИ.
Когда вы работаете в передовой лаборатории, вы, как правило, узнаете о передовых возможностях за несколько месяцев до остальных. Но этот результат — совершенно новый, с использованием недавно разработанных методик. Это стало сюрпризом даже для многих исследователей OpenAI. Сегодня каждый может увидеть, где находится граница.
Нам требуется несколько месяцев, чтобы превратить экспериментальный исследовательский рубеж в продукт. Но прогресс настолько быстр, что несколько месяцев могут означать огромную разницу в возможностях.
Своими впечатлениями поделилась еще одна участница команды OpenAI, работавшей над проектом, Шерил Хсу (Sheryl Hsu):
Это безумие, как мы прошли путь от 12% на AIME (GPT 4o) → IMO gold за ~ 15 месяцев. Мы проделали очень большой путь очень быстро. Я не удивлюсь, если к следующему году модели будут выводить новые теоремы и вносить вклад в оригинальные математические исследования!
Любопытно, что взятие искусственным интеллектом золота на IMO 2025 стало предметом пари между двумя известными исследователями в области ИИ, Полом Кристиано (Paul Christiano) и Элиезером Юдковски. Первый поставил на 8% вероятность этого события, второй — на 16%.
Впрочем, один из крупнейших математиков планеты, Теренс Тао, прокомментировал эту новость довольно сдержанно:
Заманчиво рассматривать возможности современных технологий ИИ как некую единую величину: либо данная задача X по силам современным инструментам, либо нет. Однако на самом деле существует очень большой разброс в возможностях (на несколько порядков), который зависит от того, какие ресурсы и помощь предоставляются инструменту и как именно сообщается о его результатах.
Это можно проиллюстрировать на примере с человеком. В качестве примера я использую недавно завершившуюся Международную математическую олимпиаду (IMO). Формат таков: каждая страна выставляет команду из шести участников (старшеклассников) во главе с руководителем команды (часто профессиональным математиком). В течение двух дней каждому участнику дается по четыре с половиной часа в день на решение трех сложных математических задач, имея при себе только ручку и бумагу. Никакое общение между участниками (или с руководителем команды) в этот период не допускается, хотя участники могут просить наблюдателей разъяснить формулировки задач. Руководитель команды отстаивает работы студентов перед жюри IMO в процессе оценки, но непосредственно в экзамене IMO не участвует.
IMO по праву считается очень строгим критерием математических достижений, и для старшеклассника получение медали, особенно золотой или идеального балла, является большим успехом. В этом году порог для золотой медали составил 35/42 балла, что соответствует безупречному решению пяти из шести задач. Даже идеальное решение одной задачи заслуживает «похвального отзыва».
Но представьте, как изменится уровень сложности Олимпиады, если мы по-разному изменим формат:
- Дать студентам несколько дней на решение каждой задачи, а не четыре с половиной часа на три задачи. (Если немного развить эту метафору, представьте себе научно-фантастический сценарий, где студенту по-прежнему дается всего четыре с половиной часа, но руководитель команды помещает его в некую дорогую и энергозатратную машину ускорения времени, в которой для студента за этот период проходят месяцы или даже годы.)
- Перед началом экзамена руководитель команды переписывает задачи в формат, с которым студентам легче работать.
- Руководитель команды предоставляет студентам неограниченный доступ к калькуляторам, системам компьютерной алгебры, формальным ассистентам доказательств, учебникам или возможность поиска в интернете.
- Руководитель команды заставляет всю команду из шести студентов работать над одной и той же задачей одновременно, общаясь друг с другом о частичном прогрессе и сообщая о тупиковых путях.
- Руководитель команды дает студентам подсказки, направляющие их к перспективным подходам, и вмешивается, если один из студентов тратит слишком много времени на направление, которое, как он знает, вряд ли приведет к успеху.
- Каждый из шести студентов команды представляет решения, но руководитель выбирает для отправки на конкурс только «лучшее» решение, отбрасывая остальные.
- Если ни один из студентов команды не получает удовлетворительного решения, руководитель вообще не представляет никакого решения и молча снимается с конкурса, так что их участие нигде не фиксируется.
В каждом из этих форматов представленные решения все еще технически создаются старшеклассниками, а не руководителем команды. Однако сообщаемый уровень успешности студентов на конкурсе может кардинально измениться из-за таких изменений формата; студент или команда студентов, которые могли бы не получить даже бронзовой медали в стандартных условиях конкурса, вместо этого могут достичь уровня золотой медали в некоторых из измененных форматов, указанных выше.
Таким образом, в отсутствие контролируемой методологии тестирования, которая не была бы выбрана самими соревнующимися командами, следует с осторожностью относиться к прямому сравнению результатов различных моделей ИИ на таких соревнованиях, как IMO, или между такими моделями и участниками-людьми.
В связи с этим я не буду комментировать никакие самостоятельно заявленные результаты ИИ на соревнованиях, методология которых не была раскрыта до начала состязания. P.S. В частности, вышеуказанные комментарии не относятся к какому-то одному конкретному результату такого рода.
И хотя представители OpenAI ответили бы (или возможно ответят) на это замечание куда более компетентно, рискну возразить, что замечание математика относится к архитектуре ИИ — если это и преимущество, то неотъемлемое.
Другой математик прокомментировал некоторые из найденных моделью OpenAI решений:
Задача 1
Математика подтвердилась — модель вбила ключевую лемму: для n > 3 любое n-строчное покрытие P_n должно включать сторону треугольника (т.е. не солнечную линию). Это сводит проблему к n = 3, где все становится случайным. Чистый ход. Однако, написание статьи несколько грязновато:
1) Избыточно используются сокращения и фрагменты предложений.
2) Вводятся новые термины без определений — например, «запрещенный», «солнечные партнеры» например, «Перечислите все неупорядоченные пары точек в S и проверьте условие запрещенности: Запрещено, если x равно или y равно или сумма равна.»
3) Отсутствует структурная ясность (например, «Хорошая лемма для S3» просто отброшена на середине доказательства).
4) Дублируется терминология: «запрещенный» и «несолнечный» используются как взаимозаменяемые без объяснения причин.
5) Слишком многословна. Человек мог бы выделить ключевую лемму, обработать базу n=3, построить примеры для 0/1/3 и закончить за ~10% от объема. [Модель] OpenAI использовала для этого LLM. DeepMind, по слухам, использует Lean, что может принести больше строгости и структуры. Любопытно посмотреть, с чем сравнятся их разработки, когда они выйдут.
Задача 2
Это задача по геометрии, которая обычно решается людьми с помощью интуиции, симметрии и элегантных теорем. Однако [модель] OpenAI пошла на полный перебор: 442 строки координатной геометрии и алгебры. Технически безупречно. Эстетически — не очень. Никаких геометрических изысков, никаких умных идей — только сплошная алгебраическая зубрежка. Проблема решена, но математической эстетики не чувствуется.
Задача 3
Напротив, представляет собой задачу с функциональными уравнениями, и, что удивительно, решение здесь гораздо лучше. Оно чистое, лаконичное и читается почти так, как будто его написал человек. На самом деле, оно короче, чем решение задачи 1, хотя функциональные уравнения (особенно задачи 3 IMO) обычно имеют тенденцию быть длиннее. Баланс детализации и ясности просто правильный. Гораздо лучше, чем в решениях задач 1 и 2.
Представители олимпиады также упомянули успехи ИИ, не называя пока конкретных моделей. Вот что по этому поводу сообщил директор олимпиады, Грегор Долинар (Gregor Dolinar):
Очень радостно наблюдать за прогрессом в математических способностях моделей ИИ, но мы хотели бы внести ясность: IMO не может проверить методы их получения, включая объем использованных вычислительных ресурсов, наличие человеческого вмешательства или воспроизводимость результатов. Что мы можем утверждать, так это то, что корректные математические доказательства верны, независимо от того, были ли они получены блестящими студентами или моделями ИИ.
Как бы то ни было, решение пяти из шести задач на международной математической олимпиаде — выдающееся достижение, доказывающее, что стремительное развитие ИИ пока не замедляется. Особенно важно, что такого результата достигли именно большие языковые модели, без привлечения специализированных систем формальной логики — причем сразу у двух компаний, OpenAI и Google DeepMind.
Еще весной этого года лучшим результатом в менее сложной, по сравнению с международной, американской олимпиаде USAMO 2025 были неполных 5% от DeepSeek-R1 — а на сегодня он составляет 62%. Этот результат принадлежит Grok 4, релиз которого состоялся в этом месяце, при этом в IMO 2025 он набрал всего 12%. Теперь же речь идет об уровне золотого медалиста в самой сложной математической олимпиаде, и этим достижением могут похвастать большие языковые модели общего назначения.
При этом следует помнить, что используемая в экспериментальной модели OpenAI технология не задействована в GPT-5, релиз которой запланирован не позднее августа. OpenAI заявляет, что «мы не планируем выпускать модель с таким уровнем возможностей в течение многих месяцев» — вероятно, данный уровень интеллекта мы увидим (во всяком случае у OpenAI) не раньше следующего года, а то и вовсе в GPT-6. Очевидно, что запуск продукта, которым пользуются сотни миллионов (а в перспективе — миллиарды) людей, требует тщательной подготовки — прежде всего на предмет предотвращения нежелательного контента, галлюцинаций и т.д. Вероятно тестирование GPT-5 уже подходит к завершению, тогда как внедрение новых технологий из экспериментальной модели может задержать релиз новой версии ChatGPT.
Что касается Google DeepMind, то там сделают версию этой модели Deep Think доступной для группы доверенных тестировщиков, включая математиков, прежде чем распространить её среди подписчиков Google AI Ultra.
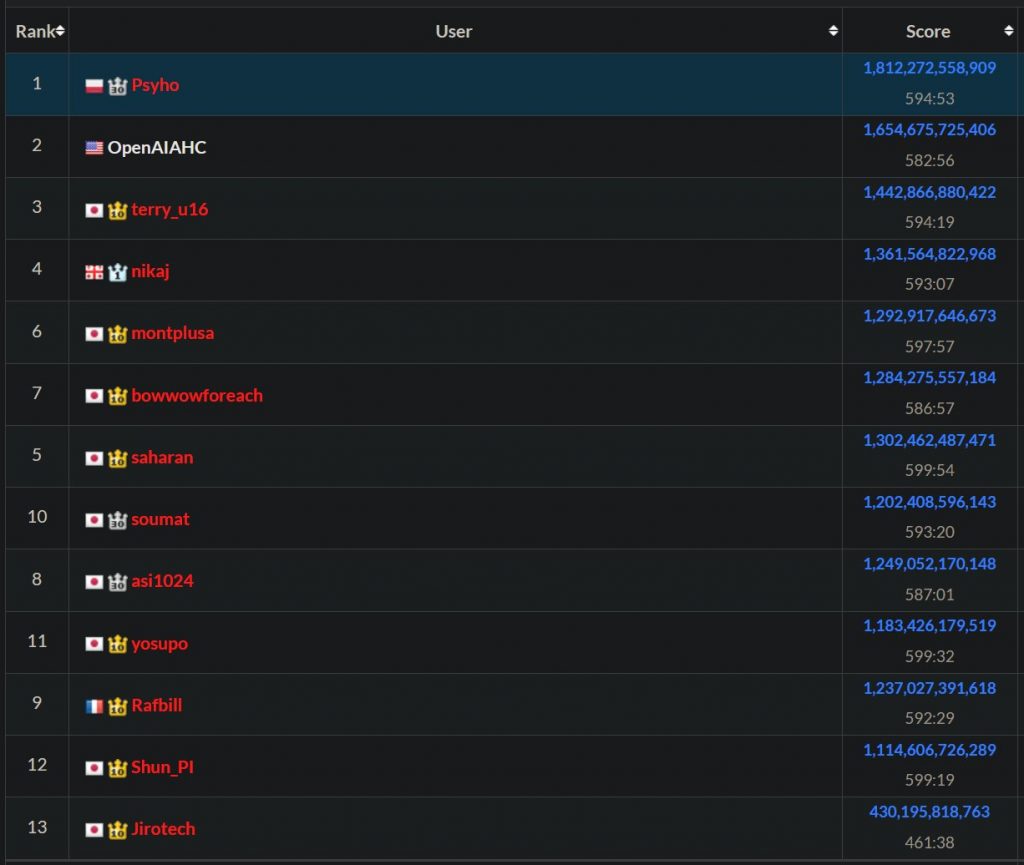
Другое свежее достижение ИИ касается области, которая близка к математике — программирования. В состоявшемся на днях соревновании AtCoder 2025, где нужно было за 10 часов написать наилучшее решение для оптимизационной задачи, второе место заняла некая модель от OpenAI. Первое место занял (возможно в последний раз) польский программист Пшемыслав Дембяк, выступающий под ником Psyho. Сэм Олтмен поздравил победителя, а спустя три дня оставил в Твиттере такое сообщение:
Проснулся рано утром в субботу, чтобы иметь пару часов испытать нашу новую модель для небольшого проекта по программированию. Сделал за 5 минут. Это очень, очень хорошо. Не уверен в своих чувствах по этому поводу…