Искусственный интеллект Microsoft превзошел человека в распознавании речи
На днях Microsoft поделилась новым достижением своей системы распознавания речи. В октябре прошлого года уровень её погрешности в популярном бенчмарке Switchboard (наборе аудиофайлов с записью телефонных разговоров на английском языке) сравнялся с человеческим, который согласно компании составляет 5.9%. В марте этого года IBM получила еще более высокий результат — 5.5%, при этом средняя доля ошибок человека по её данным составляет 5.1%. И вот теперь пальма первенства возвращается к Microsoft, которая объявила о выходе на уровень в 5.1% — что по её оценкам превосходит человека, а по оценкам IBM соответствует ему.
Как мы уже рассказывали, разработанная Microsoft система распознавания речи была создана при помощи её собственного нейросетевого инструментария CNTK (Computational Network Toolkit), чей исходный код доступен всем желающим. В основе систем распознавания речи традиционно лежат два типа нейронных сетей: сверточная для акустического моделирования и многослойная рекуррентная для как акустического, так и языкового моделирования. Microsoft усовершенствовала этот подход за счет:
- акустической модели CNN-BLSTM
- долгой краткосрочной памяти (разновидности рекуррентных нейронных сетей), основанной не на словах, а на буквах
- долгой краткосрочной памяти, использующей предшествовавшую речь для понимания контекста
- комбинирования предсказаний, полученных от многочисленных акустических моделей, на уровне как слов, так и т.н. сенонов (грубо говоря звуков, из которых складывается речь)
- внесения поправок в языковую модель после построения сети спутывания.
С учетом наблюдаемой динамики можно не сомневаться, что тенденция улучшения распознавания речи продолжится, и превосходство искусственного интеллекта над человеческим в этой конкретной задаче будет окончательно закреплено. В то же время Microsoft напоминает про задачи, которые еще предстоит решить в этом направлении: распознавание речи далеко стоящего от микрофона человека в шумной обстановке; распознавание речи на языке или с акцентом, по которым имеется ограниченный объем данных; и наконец пожалуй самое главное — понимание смысла услышанного и распознанного текста.
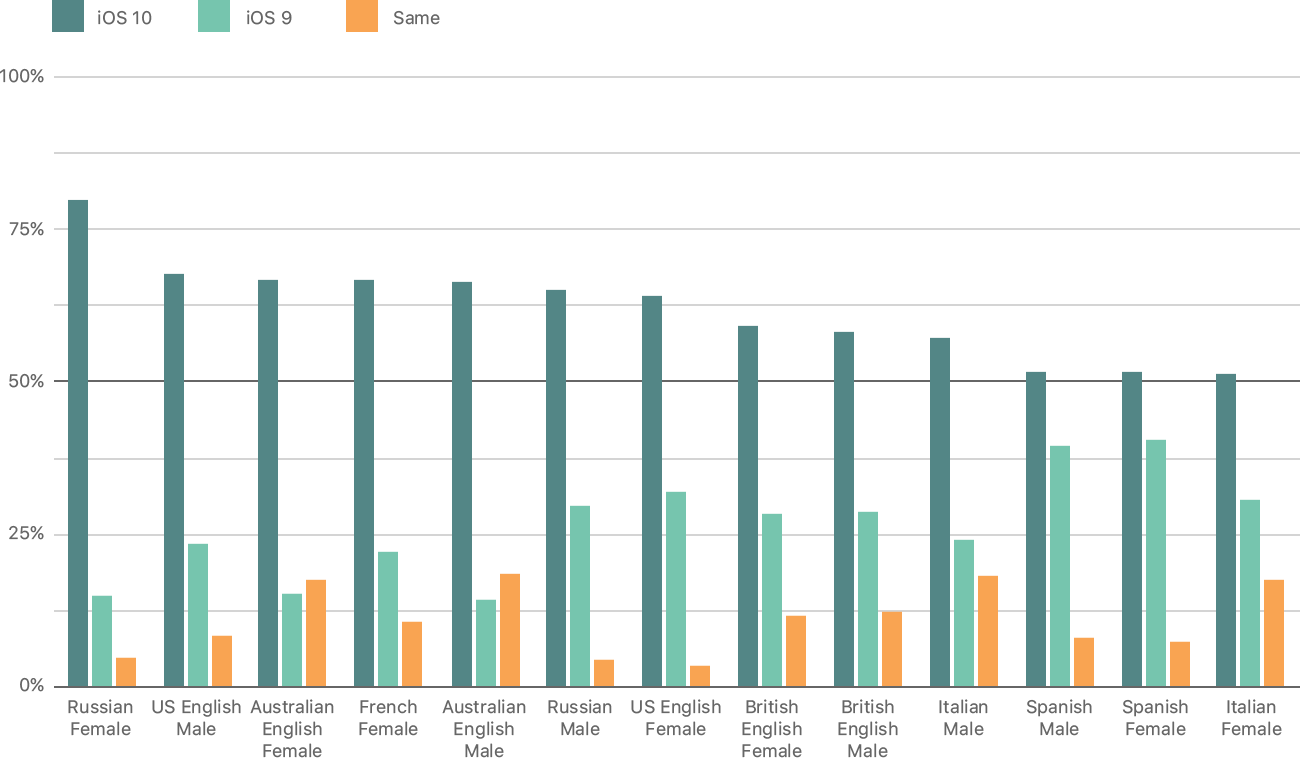
Немалые успехи имеются и в обратной задаче — преобразовании текста в голосовую речь. Публикация Microsoft почти совпала с докладом Apple, в котором приводятся примеры произнесенных Siri фраз — в версиях для iOS 9, iOS 10 и iOS 11. Нельзя не отметить, что с каждой новой прошивкой интонация виртуальной помощницы становится все более естественной. Иллюстрация сверху не вполне понятна, но судя по ней особенно большой прогресс был достигнут в русскоязычной версии Siri. Интересно, что элементы искусственного интеллекта для этой функции появились начиная лишь с iOS 10. Обучение происходит на базе т.н. глубокой сети смешанной плотности (deep mixture density network, MDN), которая сочетает традиционную глубокую нейросеть со смешанной гауссовской моделью.