Аргументы в пользу появления AGI к 2030 году; три причины, по которым это может произойти через десятки лет; и свежее эссе Сэма Олтмена о мягкой сингулярности

Предлагаем вашему вниманию переводы двух статей, опубликованных на ресурсе 80,000 Hours, который «проводит исследования и оказывает поддержку, помогая талантливым людям выбрать карьеру, которая поможет им решить самые насущные мировые проблемы». Ресурс так назван по числу часов в рабочей карьере — 40 лет по 50 недель по 40 часов.
Первая статья, весьма объемная, вышла 21 марта. Её автор — Бенджамин Тодд. В настоящее время он возглавляет 80,000 Hours, а до этого стажировался в качестве аналитика в ведущем инвестиционном фонде. Получил научную степень по физике и философии в Оксфордском университете, публиковался в Climate Physics. В статье приводятся обстоятельные аргументы в пользу того, что появление AGI может состояться к 2030 году.
Вторая статья вышла буквально на днях, и написана исследователем из 80,000 Hours, Зершане Куреши. Она получила степень магистра математики и философии в Оксфордском университете. Проработав три года в сфере рыночной аналитики в глобальной водной индустрии, она сменила карьеру, чтобы сосредоточиться на исследованиях в области безопасности искусственного интеллекта. Эта статья намного меньше, и в ней приводятся три аргумента в пользу того, что от AGI нас возможно отделяют еще десятки лет.
А еще глава OpenAI Сэм Олтмен приурочил к релизу o3-pro очередное эссе в своем блоге, «Мягкая сингулярность», перевод которого также предлагаем вашему вниманию.
Аргументы в пользу AGI к 2030 году
В последние месяцы руководители ведущих компаний в области искусственного интеллекта (ИИ) становятся всё более уверенными в быстром прогрессе. В этой статье я рассмотрю, что движет недавними достижениями, оценю, как долго эти факторы могут продолжать действовать, и объясню, почему они, вероятно, сохранятся ещё как минимум четыре года. В частности, я расскажу, как новый подход — обучение моделей рассуждению с помощью обучения с подкреплением — позволил ИИ превзойти человеческие способности в сложных задачах, и что это может означать для появления сильного искусственного интеллекта (AGI) к 2030 году.
В последние месяцы руководители ведущих компаний в области ИИ выразили растущую уверенность в быстром прогрессе:
- Сэм Альтман из OpenAI: в ноябре говорил, что «темпы прогресса сохраняются», а в январе заявил: «мы теперь уверены, что знаем, как построить AGI».
- Дарио Амодеи из Anthropic: в январе отметил: «Я более уверен, чем когда-либо, что мы близки к мощным возможностям… в ближайшие 2–3 года».
- Демис Хассабис из Google DeepMind: осенью говорил о сроках «не ранее 10 лет», а к январю сократил прогноз до «вероятно, три-пять лет».
Что объясняет этот сдвиг? Это просто шумиха? Или мы действительно можем достичь AGI к 2030 году?
Не существует единого момента, когда система становится «AGI», и этот термин используется по-разному. Более фундаментально, системы ИИ можно классифицировать по (i) силе и (ii) широте их возможностей. «Узкий» (в русскоязычной литературе обычно говорят «слабый») ИИ демонстрирует высокую результативность в ограниченном наборе задач (например, ИИ для игры в шахматы). Большинство технологий имеют очень узкие области применения. «Общий» (в русскоязычной литературе обычно говорят «сильный») ИИ должен обладать сильными способностями в широком спектре областей, подобно тому, как люди могут обучаться множеству профессий. Однако нет чёткой границы, где узкий ИИ становится общим — это спектр. Обычно, когда люди говорят «AGI», они имеют в виду что-то вроде «по крайней мере на человеческом уровне или лучше в большинстве когнитивных задач». Примерно это я и подразумеваю в данной статье, хотя мои выводы часто не зависят от точного определения, и я рассматриваю несколько определений или обсуждаю конкретные способности. Ещё более общий ИИ мог бы выполнять и некогнитивные задачи; например, в сочетании с робототехникой он мог бы выполнять физические задачи. Обычно лучше прогнозировать конкретные способности, а не «AGI». В противном случае люди фокусируются на разных определениях AGI в зависимости от того, что, по их мнению, может вызвать трансформационные изменения в обществе. Например, те, кто считает важным ускорение исследований ИИ, могут сосредоточиться на определении, достаточном для этого порога; в то время как те, кто считает важным широкое экономическое ускорение, будут больше заботиться о способности выполнять реальные рабочие задачи и робототехнике. Учтите, что сравнительно узкие системы (например, специализированные на научных исследованиях или исследованиях ИИ) всё равно могут вызвать трансформационные изменения, так что «AGI» может быть даже не нужен для драматических социальных перемен. С другой стороны, если ИИ останется ограниченным когнитивными задачами, он не сможет автоматизировать всю производственную цепочку, что ограничит некоторые из наиболее драматичных возможных исходов. Некоторые предлагают использовать термин «трансформационный ИИ», чтобы подчеркнуть, что важны трансформационные эффекты, а не обобщённость. Я решил придерживаться термина AGI, поскольку он наиболее распространён, но стараюсь быть ясным в отношении определений. Определения AGI обычно формулируются в терминах «способностей», то есть способности решать реальные проблемы или выполнять задачи. Говоря об «интеллекте», люди думают о моделях как о чисто интеллектуальных способностях, вроде «ботанистого» гения, но сегодня компании создают универсальных агентов, которые в конечном итоге будут обладать хорошими социальными навыками, креативностью, способностью к физическим манипуляциям и так далее. «Искусственная общая компетентность» могла бы быть более подходящим названием. Более точное определение можно найти в статье исследователей DeepMind: Morris, Meredith, et al. Levels of AGI: Operationalizing Progress on the Path to AGI. arxiv.org/pdf/2311.02462.
В этой статье я рассмотрю, что движет недавним прогрессом, оценю, как долго эти факторы могут продолжать действовать, и объясню, почему они, вероятно, сохранятся ещё как минимум четыре года.
В частности, в 2024 году прогресс в чат-ботах на основе больших языковых моделей (LLM) замедлился, но начал работать новый подход: обучение моделей рассуждению с использованием обучения с подкреплением.
За год это позволило моделям превзойти людей с докторской степенью в ответах на сложные научные вопросы, требующие рассуждений, и достичь экспертного уровня в выполнении часовых задач по программированию.
Мы не знаем, насколько мощным станет ИИ, но экстраполяция текущих темпов прогресса предполагает, что к 2028 году мы можем достичь моделей ИИ с сверхчеловеческими способностями к рассуждению, экспертными знаниями во всех областях и возможностью автономно выполнять проекты, длящиеся несколько недель. Прогресс, вероятно, продолжится и дальше.
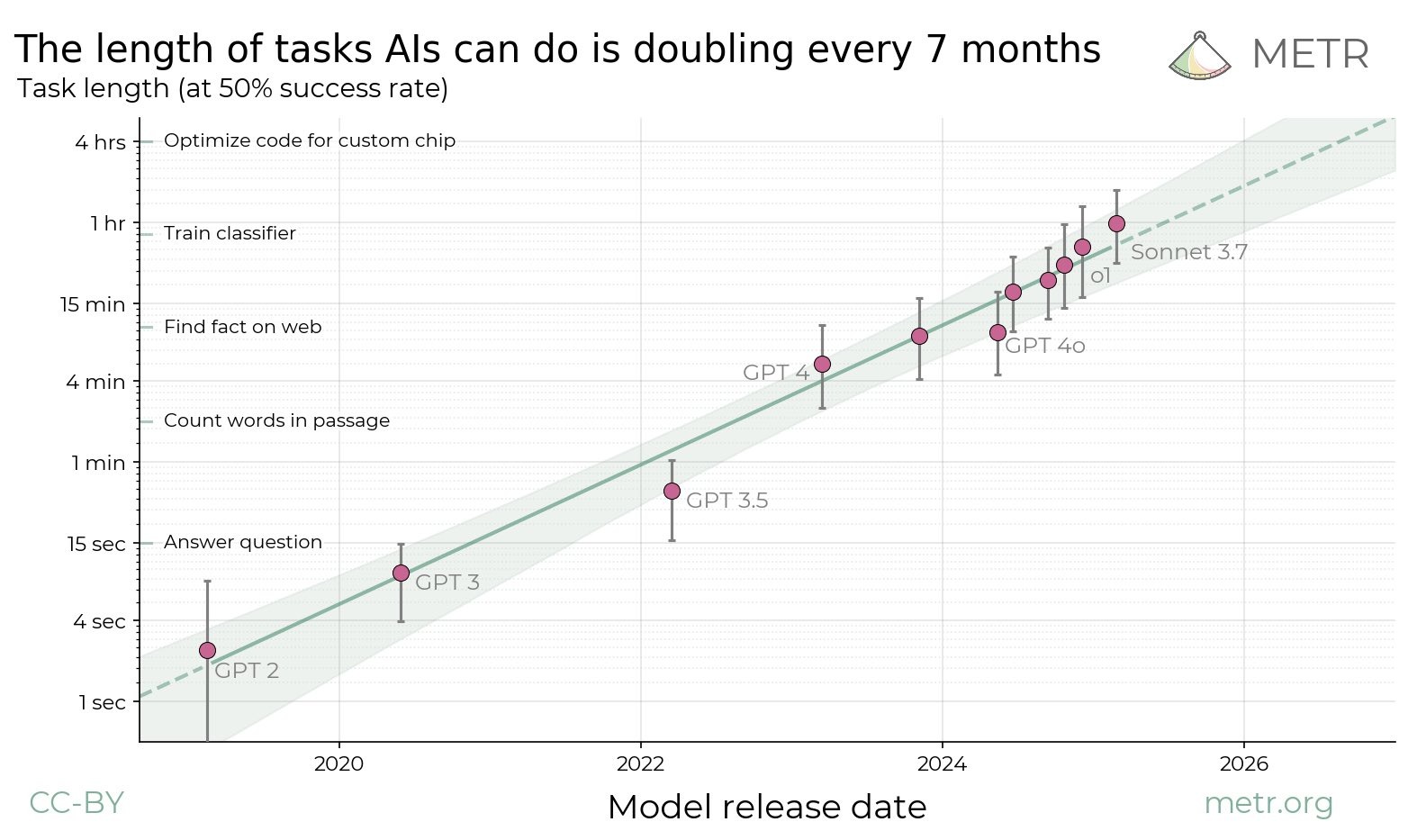
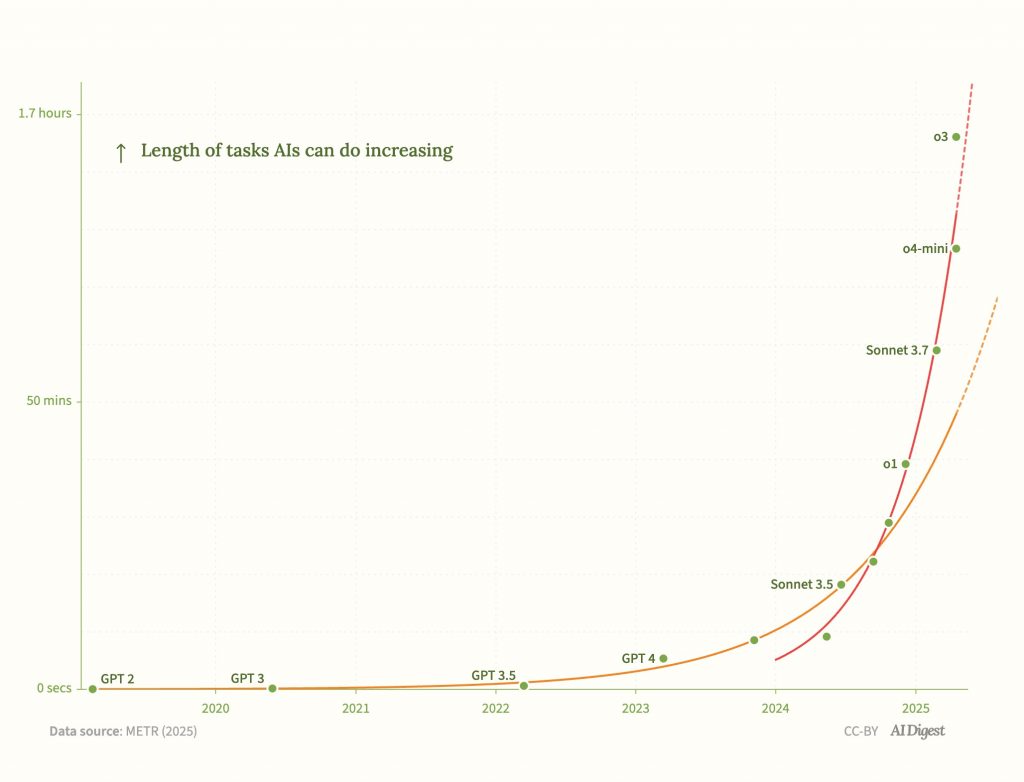
Длительность задач, выполняемых ИИ, удваивается каждые 7 месяцев
Длительность задач (при 50% успешности)
На этом наборе задач по разработке программного обеспечения и использованию компьютеров в 2020 году ИИ мог выполнять задачи, которые обычно занимают у эксперта несколько секунд. К 2024 году этот показатель вырос почти до часа. Если тенденция сохранится, к 2028 году он достигнет нескольких недель.
Эти модели, уже не просто чат-боты, а «агенты», вскоре могут соответствовать многим определениям AGI — то есть систем ИИ, которые сравнимы с человеческими возможностями в большинстве интеллектуальной работы.
Это означает, что, хотя руководители компаний, вероятно, излишне оптимистичны, есть достаточно доказательств, чтобы относиться к их позиции очень серьёзно.
Где мы проводим границу «AGI» — в конечном счёте произвольно. Важно то, что эти модели могут начать ускорять исследования в области ИИ, открывая доступ к огромному числу более способных «ИИ-работников». В свою очередь, достаточная автоматизация может вызвать взрывной рост и привести к 100 годам научного прогресса за 10 лет — переход, к которому общество не готово.
Хотя это может звучать невероятно, это находится в пределах возможностей, которые многие эксперты считают реальными. Эта статья призвана дать вам базовое представление о том, почему это так, а также привести лучшие контраргументы.
Я пишу об AGI с 2014 года. Тогда появление AGI в течение пяти лет казалось крайне маловероятным. Сегодня ситуация кардинально изменилась. Мы видим очертания того, как это может работать и кто это создаст.
Фактически, следующие пять лет кажутся необычайно важными. Основные движущие силы прогресса ИИ — инвестиции в вычислительные мощности и исследования алгоритмов — не смогут продолжать расти текущими темпами после 2030 года. Это означает, что мы либо достигнем систем ИИ, способных вызвать ускорение, в ближайшее время, либо прогресс значительно замедлится.
В любом случае, следующие пять лет определят исход. Давайте разберёмся, почему.
Вкратце
- Четыре ключевых фактора движут прогрессом ИИ: 1) увеличение размера базовых моделей, 2) обучение моделей рассуждению, 3) увеличение времени на размышление моделей и 4) создание агентного каркаса для многоэтапных задач. Эти факторы поддерживаются ростом вычислительных мощностей для работы и обучения систем ИИ, а также увеличением человеческого капитала в исследованиях алгоритмов.
- Все эти факторы будут действовать до 2028 года, а возможно, и до 2032 года.
- Это означает, что мы должны ожидать значительных дальнейших улучшений в результативности ИИ. Мы не знаем, насколько они будут велики, но экстраполяция текущих тенденций на бенчмарках предполагает, что мы достигнем систем со сверхчеловеческой результативностью в программировании и научных рассуждениях, способных автономно выполнять проекты длительностью в несколько недель.
- Называем ли мы эти системы «AGI» или нет, они могут быть достаточными для ускорения исследований в области ИИ, робототехники, технологической индустрии и науки, что приведёт к трансформационным последствиям.
- В качестве альтернативы, ИИ может не справиться с проблемами нечётко определённых задач, требующих высокого контекста и длительных временных горизонтов, и остаться инструментом (хотя и значительно улучшенным по сравнению с сегодняшним днём).
- Увеличение результативности ИИ требует экспоненциального роста инвестиций и исследовательской рабочей силы. При текущих темпах мы, вероятно, начнём сталкиваться с ограничениями около 2030 года. Упрощённо говоря, это означает, что мы либо достигнем AGI к 2030 году, либо прогресс значительно замедлится. Возможны и гибридные сценарии, но следующие пять лет кажутся особенно важными.
I. Что движет недавним прогрессом ИИ? И будет ли это продолжаться?
Эра глубокого обучения
В 2022 году Ян Лекун, главный учёный по ИИ в Meta и лауреат премии Тьюринга, сказал:
«Я беру объект, кладу его на стол и толкаю стол. Вам совершенно очевидно, что объект сдвинется вместе со столом… Я не верю, что в мире существует текст, который это объясняет. Если вы обучите машину, какой бы мощной она ни была… ваш GPT5000, она никогда этому не научится».
Через год после заявления Лекуна GPT-4 дает правильный ответ.
И это не единственный пример, когда эксперты оказывались в замешательстве. До 2011 года ИИ считался мёртвым. Но всё изменилось, когда концептуальные идеи 1970-х и 1980-х годов в сочетании с огромными объёмами данных и вычислительных мощностей породили парадигму глубокого обучения.
С тех пор мы неоднократно видели, как системы ИИ переходят от полной некомпетентности к сверхчеловеческой результативности во многих задачах за пару лет.
Например, в 2022 году, если вы просили Midjourney нарисовать «выдру в самолёте, использующую Wi-Fi», результат был таким:

Два года спустя с Veo 2 вы могли получить вполне приличное видео с выдрой в самолете (статья написана до релиза Veo 3).
В 2019 году GPT-2 могла с трудом оставаться в теме на пару абзацев. И это считалось замечательным прогрессом.
Критики, такие как Лекун, быстро указывали, что GPT-2 не умела рассуждать, демонстрировать здравый смысл, понимать физический мир и так далее. Но многие из этих ограничений были преодолены за пару лет.
Снова и снова делать ставки против глубокого обучения оказывалось опасно. Сегодня даже Лекун говорит, что ожидает AGI через «несколько лет».
«Это не столетия. Это могут быть не десятилетия. Это несколько лет». Источник: Интервью в Центре Блумберга Университета Джонса Хопкинса в 2025 году; временная метка: 27:50.
На ограничениях текущих систем не стоит зацикливаться. Более интересный вопрос: куда это всё ведёт? Что объясняет скачок от GPT-2 к GPT-4, и увидим ли мы ещё один?
Что нас ждёт
На самом общем уровне прогресс ИИ обусловлен:
- Увеличением вычислительных мощностей.
- Улучшением алгоритмов.
Оба фактора быстро совершенствуются. Более конкретно, недавний прогресс можно разделить на четыре ключевых фактора:
- Масштабирование предварительного обучения для создания базовой модели с базовым интеллектом.
- Использование обучения с подкреплением для обучения базовой модели рассуждению.
- Увеличение вычислений на этапе тестирования для увеличения времени, которое модель тратит на обдумывание каждого вопроса.
- Создание агентного каркаса, чтобы модель могла выполнять сложные задачи.
В оставшейся части этого раздела я объясню, как работает каждый из этих факторов, и попытаюсь спрогнозировать их развитие. Погрузитесь в детали, и вы поймёте основы того, как совершенствуется ИИ.
В следующем разделе я использую это для прогнозирования будущего прогресса ИИ и объясню, почему следующие пять лет особенно важны.
1. Масштабирование предварительного обучения для создания базовых моделей с базовым интеллектом
Вычисления для предварительного обучения
Люди часто думают, что прогресс ИИ требует огромных интеллектуальных прорывов, но многое сводится к инженерным решениям. Делайте (гораздо) больше того же самого, и модели становятся лучше.
В скачке от GPT-2 к GPT-4 главным фактором прогресса было использование значительно больших вычислительных мощностей для тех же методов, особенно для «предварительного обучения».
Современный ИИ работает с использованием искусственных нейронных сетей, включающих миллиарды взаимосвязанных параметров, организованных в слои. Во время предварительного обучения (название вводит в заблуждение, так как это просто первый этап обучения) происходит следующее:
- Данные подаются в сеть (например, изображение кошки).
- Значения параметров преобразуют эти данные в предсказанный результат (например, описание: «это кошка»).
- Точность этих результатов оценивается по сравнению с эталонными данными.
- Параметры модели корректируются, чтобы повысить точность.
- Этот процесс повторяется снова и снова с триллионами единиц данных.
Этот метод использовался для обучения всех видов ИИ, но он оказался наиболее полезным для предсказания языка. Данные — это тексты в Интернете, а большие языковые модели (LLM) обучаются предсказывать пропуски в тексте.
Большие вычислительные мощности для обучения (то есть «вычисления для обучения») позволяют использовать больше параметров, что помогает моделям изучать более сложные и абстрактные закономерности в данных. Это также означает, что можно использовать больше данных.
С начала эры глубокого обучения количество вычислений, используемых для обучения моделей ИИ, растёт с ошеломляющей скоростью — более чем в 4 раза в год.
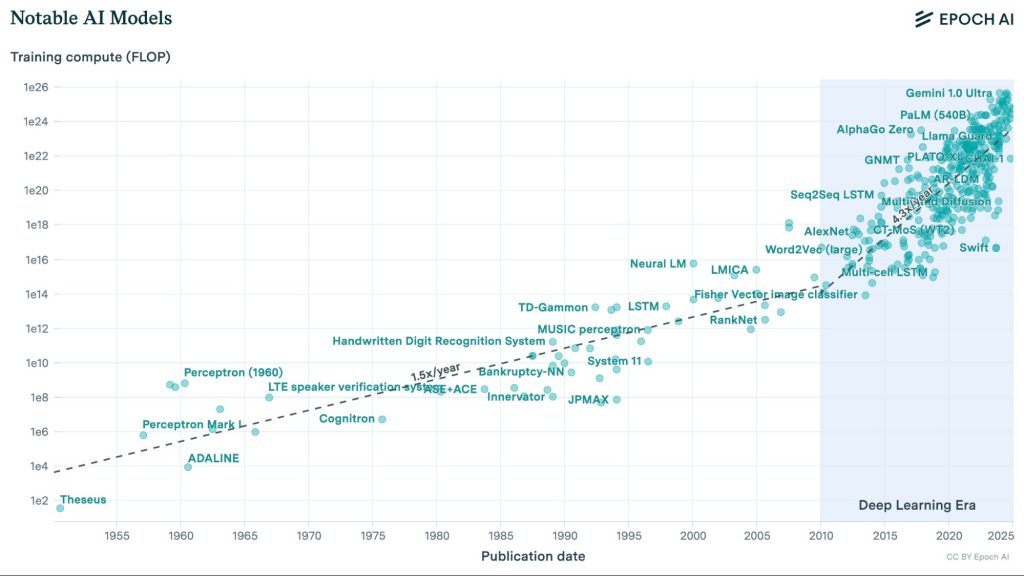
С начала эры глубокого обучения объём вычислительных мощностей (измеряемый во флопсах, выражающих количество операций с плавающей запятой в секунду) для обучения ведущих моделей ИИ увеличивался более чем в четыре раза ежегодно.
Это было обусловлено увеличением расходов и использованием более эффективных чипов.
Увеличение вычислений для обучения было обусловлено:
- увеличением расходов (2.5x в год; из Epoch AI Machine Learning Trends);
- улучшением вычислительной мощности чипов (1.3x в год; из Epoch AI Machine Learning Trends);
- лучшей адаптацией этих чипов для задач ИИ (1.3x в год, экстраполировано).
Исторически каждый раз, когда вычисления для обучения увеличивались в 10 раз, результативность стабильно росла по многим задачам и бенчмаркам.
Например, с тысячекратным увеличением вычислений для обучения модели ИИ стабильно улучшали свои способности отвечать на разнообразные вопросы — от рассуждений на основе здравого смысла до понимания социальных ситуаций и физики. Это демонстрируется на бенчмарке «BIG-Bench Hard», который включает разнообразные вопросы, специально выбранные для того, чтобы бросить вызов LLM.
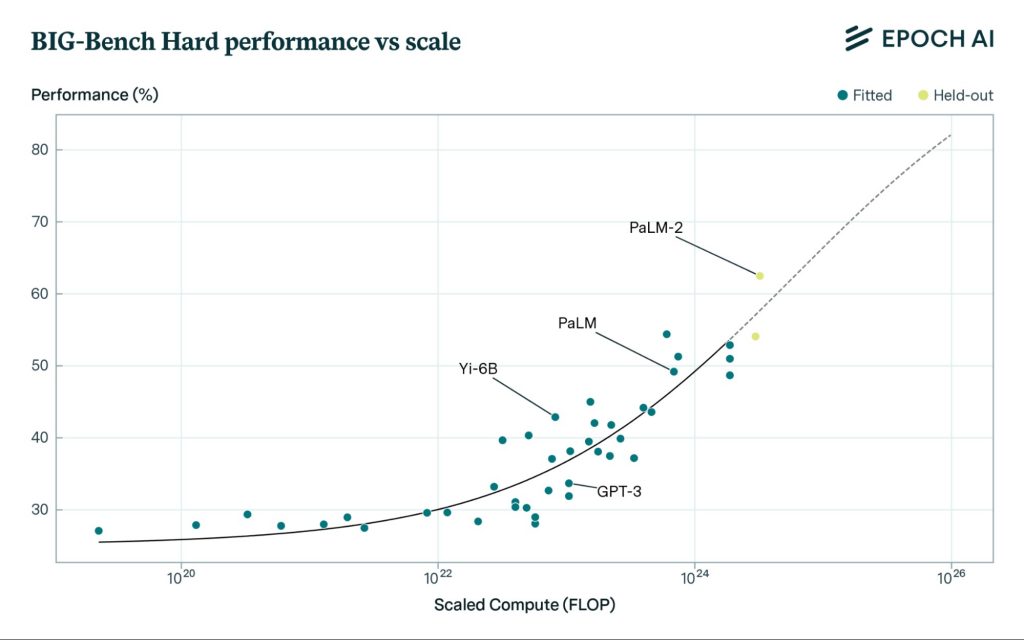
Результативность LLM на сложном бенчмарке (BIG-Bench Hard) улучшается с тысячекратным увеличением вычислений для обучения.
Аналогично, OpenAI создала модель для программирования, которая могла решать простые задачи, а затем использовала в 100 000 раз больше вычислений для обучения улучшенной версии. С увеличением вычислений модель правильно отвечала на всё более сложные вопросы.
Это показано на рисунках 1 и 6 в статье: Chen, Mark, et al. Evaluating Large Language Models Trained on Code. 14 июля 2021, arxiv.org/pdf/2107.03374. OpenAI также сделала аналогичное заявление в посте о выпуске GPT-4. В разделе о предсказуемом масштабировании они показали, что вычисления для обучения имеют предсказуемую связь с результативностью на 23 задачах по программированию в диапазоне пяти порядков. Результативность на разных уровнях вычислений; GPT-4.
Эти тестовые задачи не были в исходных обучающих данных, так что это не было просто лучшим поиском среди запомненных задач.
Эта связь между вычислениями для обучения и результативностью называется «законом масштабирования».
Законы масштабирования — это не технические законы, а закономерности в данных. Законы масштабирования обычно формулируются в терминах «потерь», которые измеряют ошибку предсказания — экспоненциально больше вычислений ведёт к линейному снижению потерь (пока не достигнут фундаментальный предел). Есть вопрос, как потери переводятся в реальные способности. Однако мы можем пропустить понятие потерь и сосредоточиться напрямую на масштабирующей зависимости между вычислениями и результативностью на бенчмарках, которая показывает схожую картину.
Статьи об этих законах были опубликованы к 2020 году. Для тех, кто следил за этими исследованиями, GPT-4 не была сюрпризом — это было просто продолжение тенденции.

Вычислительная мощность лучших чипов росла примерно на 35% в год с начала существования индустрии, что известно как закон Мура. Однако вычислительная мощность, применяемая к ИИ, росла гораздо быстрее — более чем в 4 раза в год.
Эффективность алгоритмов
Вычисления для обучения не только увеличивались, но исследователи нашли гораздо более эффективные способы их использования.
Каждые два года вычисления, необходимые для достижения той же результативности на широком спектре моделей, уменьшались в десять раз.
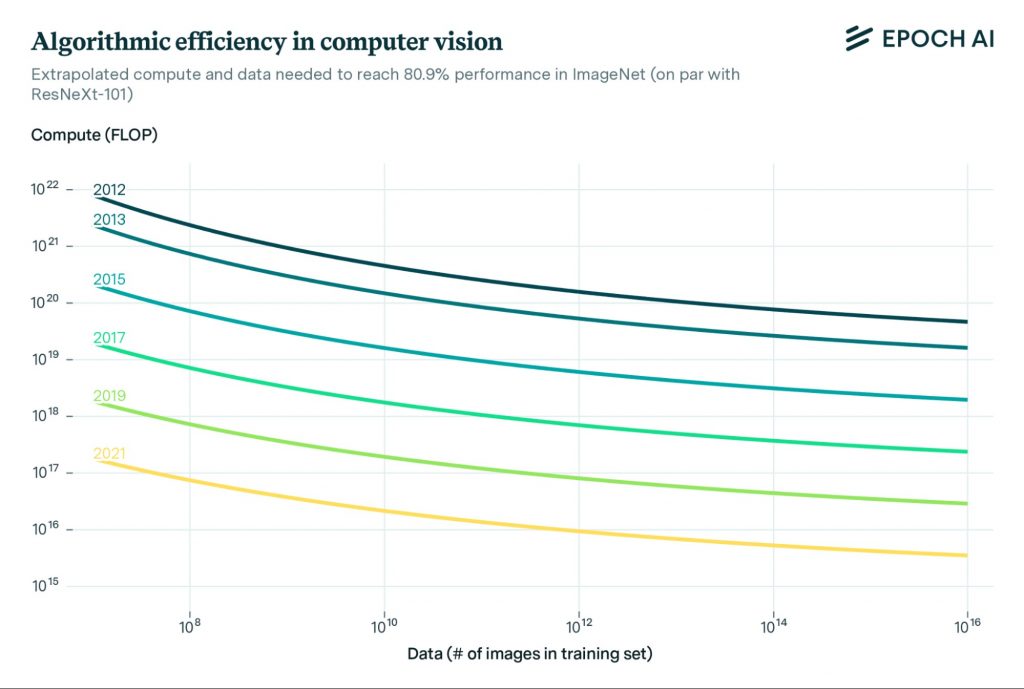
Модели ИИ требуют в 10 раз меньше вычислений для достижения той же точности в распознавании изображений каждые два года (на основе бенчмарка ImageNet).
Эти улучшения также обычно делают модели дешевле в эксплуатации. DeepSeek-V3 рекламировалась как революционный прорыв в эффективности, но она была примерно в тренде: выпущена через два года после GPT-4, она примерно в 10 раз эффективнее.
Вычисления, использованные для финального обучающего запуска GPT-4, вероятно, стоили около 40 миллионов долларов. DeepSeek сообщила, что потратила 6 миллионов долларов на свой финальный запуск (общие затраты значительно выше). Тренд предполагал бы десятикратное снижение, до 4 миллионов долларов, так что DeepSeek оказалась дороже, чем ожидалось по трендам. С другой стороны, DeepSeek-V3 значительно лучше, чем оригинальная GPT-4. Но, с другой стороны, некоторые из этих улучшений обусловлены не только алгоритмической эффективностью. В целом, я бы сказал, что это примерно соответствует тренду или немного опережает его. DeepSeek также взимает с пользователей более чем в 10 раз меньшую плату, чем OpenAI, но это во многом связано с сокращением маржи прибыли, а не с большей эффективностью работы модели. Ранее, без особой шумихи, Google выпустила Gemini Flash 2.0, которая превосходит DeepSeek и на самом деле дешевле, ясно показывая, что другие лаборатории достигли аналогичных успехов. Настоящей новостью стало то, что китайская лаборатория вышла на передовые позиции в алгоритмической эффективности.
Эффективность алгоритмов означает, что не только в четыре раза больше вычислений используется для обучения каждый год, но эти вычисления также дают в три раза больший эффект. Эти два фактора умножаются, обеспечивая 12-кратное увеличение «эффективных» вычислений ежегодно.
Это означает, что чипы, использованные для обучения GPT-4 за три месяца, могли бы быть использованы для обучения модели уровня GPT-2 примерно 300 000 раз.
См. эту модель вычислений для обучения с течением времени.
Это увеличение эффективных вычислений позволило нам перейти от модели, которая с трудом могла связать несколько абзацев, к GPT-4, способной:
- Превосходить большинство старшеклассников на вступительных экзаменах в колледж.
- Вести беседу на естественном языке — в далёком прошлом это считалось признаком истинного интеллекта, как в тесте Тьюринга.
- Решать задачи Winograd — тест на рассуждения на основе здравого смысла, который в 2010-х годах считался требующим истинного понимания.
Левеск, Х. (2012) предложил схемы Винограда — тип теста на рассуждения на основе здравого смысла в языке — как альтернативу тесту Тьюринга. Он утверждал, что схемы Винограда могут помочь определить, действительно ли системы ИИ понимают язык так, как люди, а не просто распознают шаблоны. Каждая схема состоит из предложения с неоднозначным местоимением, и правильная интерпретация зависит от неявного знания значения слов, а не только от статистических корреляций. Он утверждал, что эти вопросы нельзя обойти обманом или «дешёвыми трюками».
Levesque, Hector J. “On Our Best Behaviour.” Artificial Intelligence, vol. 212, July 2014, pp. 27–35, https://doi.org/10.1016/j.artint.2014.03.007.
- Создавать искусство, которое большинство людей не могут отличить от созданного человеком.
Недавнее исследование показало, что непрофессионалы не могут отличить поэзию, сгенерированную ИИ, от написанной человеком. Поэзия ужасна, но она была создана с помощью GPT-3.5.
Поскольку было два варианта (человек или ИИ), случайный выбор давал бы 50%, а идеальный навык — 100%. Медианный балл на тесте составил 60%, лишь немного выше случайного. Средний балл был 60,6%. Участники сказали, что задача оказалась сложнее, чем ожидалось (медианная сложность 4 по шкале от 1 до 5).
Наблюдаемая точность была чуть ниже случайной (46,6%, χ²(1, N=16340)=75,13, p<0,0001)… Участники чаще предполагали, что стихи, сгенерированные ИИ, написаны людьми, чем для стихов, действительно написанных людьми (χ²(2, N=16340)=247,04, w=0,123, p<0,0001). Пять стихотворений с наименьшим количеством оценок «человек» были написаны настоящими поэтами; четыре из пяти стихотворений с наивысшими оценками «человек» были сгенерированы ИИ.
Porter, Brian, and Edouard Machery. “AI-Generated Poetry Is Indistinguishable from Human-Written Poetry and Is Rated More Favorably.” Scientific Reports, vol. 14, no. 1, Nature Portfolio, Nov. 2024, https://doi.org/10.1038/s41598-024-76900-1.
Помимо GPT, этот опрос показал, что большинство людей плохо отличают картины, созданные ИИ, от работ человеческих художников.
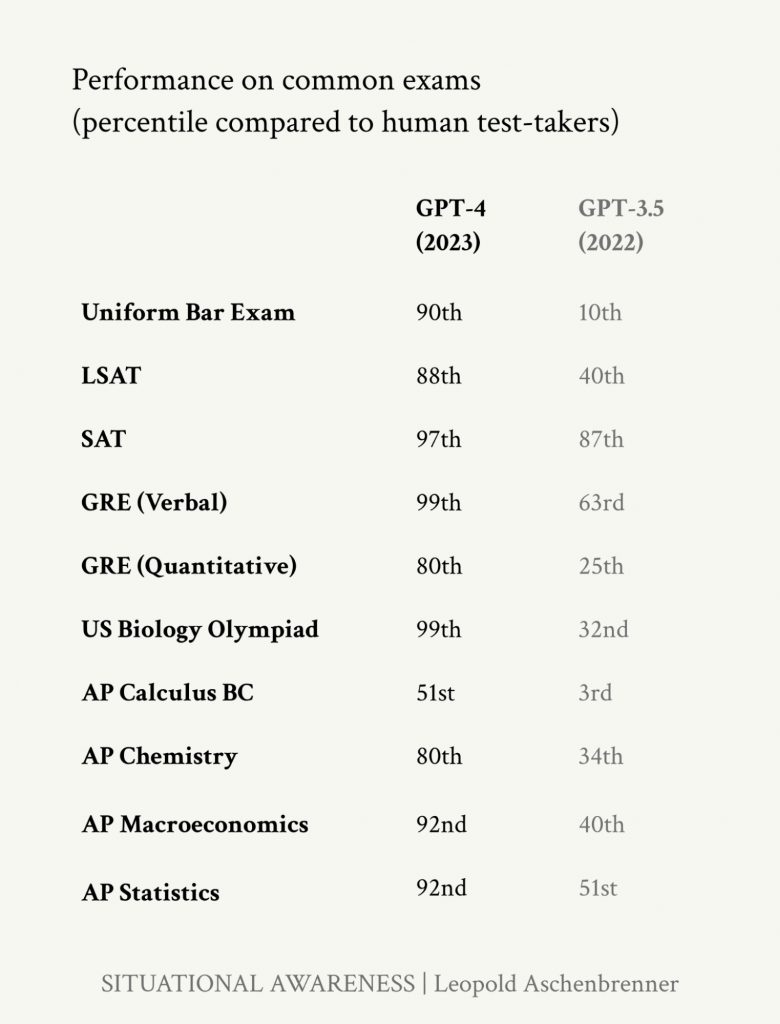
Сравнение процентильных баллов GPT-4 и GPT-3.5 по сравнению с людьми на стандартизированных экзаменах.
Как далеко может масштабироваться предварительное обучение?
Если текущие тенденции сохранятся, то к 2028 году кто-то обучит модель с в 300 000 раз большими эффективными вычислениями, чем у GPT-4.
Общий объём флопс, использованных для обучения, составил бы около 2e28 (примерно в 1000 раз больше, чем у GPT-4), а стоимость финального обучающего запуска составила бы около 6 миллиардов долларов (стоимость кластера, необходимого для обучения, составила бы около 60 миллиардов долларов). См. простую модель здесь.
Это такое же увеличение, какое мы видели от GPT-2 к GPT-4, так что, если потратить это на предварительное обучение, мы могли бы назвать такую гипотетическую модель «GPT-6».
Я не утверждаю, как OpenAI назовёт свою модель в 2028 году. Вероятно, это будет что-то вроде GPT-o3x. (Gadgets News: скорее всего это будет именно GPT-6, потому что в OpenAI позиционируют GPT-5 как модель, объединяющую в себе всё семейство моделей компании, включая reasoning-модели с приставкой «o») Я имею в виду модель, обученную с таким количеством эффективных вычислений. См. очень простую экстраполяцию с цифрами.
После паузы в 2024 году модели размером с GPT-4.5, похоже, соответствуют тренду, а компании уже близки к моделям размером с GPT-5, которые прогнозисты ожидают увидеть в 2025 году.
Но может ли этот тренд продолжаться до GPT-6? Генеральный директор Anthropic Дарио Амодей прогнозирует, что обучение моделей размером с GPT-6 будет стоить около 10 миллиардов долларов.
Тренд показывает, что обучение каждой следующей генерации обходится примерно в 10 раз дороже. Исходя из этого, я ожидаю, что GPT-6 может стоить в 2–3 раза больше 10 миллиардов долларов, но это соответствует порядку величины.
Это всё ещё по карману таким компаниям, как Google, Microsoft или Meta, которые зарабатывают 50–100 миллиардов долларов прибыли ежегодно.
Чистая прибыль за 2024 год:
- Microsoft: 88 миллиардов долларов; Microsoft 2024 Annual Report
- Meta: 62 миллиарда долларов; Meta Reports Fourth Quarter and Full Year 2024 Results
- Alphabet: 100 миллиардов долларов; Alphabet Annual Report 2024
Фактически, эти компании уже строят дата-центры, достаточно большие для таких обучающих запусков — и это было до объявления проекта Stargate стоимостью более 100 миллиардов долларов. (Gadgets News: в действительности стоимость проекта к 2029 году запланирована на уровне $500 млрд)
Nvidia продала ИИ-ускорителей на сумму около 100 миллиардов долларов в 2024 году (пресс-релизы за 1-й, 2-й, 3-й кварталы). Если это сохранится на три года, общий запас чипов будет стоить 300 миллиардов долларов. Общая стоимость дата-центров, содержащих эти чипы, составит около 500 миллиардов долларов. Таким образом, если 2% будут использованы для одного обучающего запуска, этот запуск обойдётся примерно в 10 миллиардов долларов. Это потребовало бы использования 6% мировых чипов в течение четырёх месяцев. Более 10% чипов Nvidia покупают Microsoft и Meta, так что они все могли бы провести обучающий запуск такого размера. Google также имеет достаточно собственных чипов ТПУ для этого. xAI, вероятно, тоже была бы способна на это.
- Брокеры прогнозируют, что выручка Nvidia в 2025 году составит 196 миллиардов долларов. Примерно 80% их общей выручки приходится на дата-центры, а 80% выручки от дата-центров — на продажи ГПУ. Таким образом, прогноз выручки предполагает, что Nvidia продаст чипов примерно на 125 миллиардов долларов в 2025 году, и это основано на уже размещённых заказах. Другие поставщики чипов, помимо Nvidia, также занимают растущую долю рынка, и я их игнорировал в этой оценке. Так что приведённые цифры, вероятно, консервативны.
Кроме того, доступна информация о некоторых конкретных планах:
- Google строит кластер мощностью 1 ГВт, примерно в 7 раз больше, чем крупнейшие кластеры сегодня (около 100 тысяч чипов H100 / 150 МВт).
- Microsoft строит набор дата-центров, которые могут работать вместе, содержащих 500–700 тысяч чипов B200 (эквивалентно, возможно, 1,2 миллиона чипов H100), и это потребляло бы около 1 ГВт.
- xAI объявила о намерении построить кластер из одного миллиона ГПУ.
Передовые модели ИИ уже приносят более 10 миллиардов долларов дохода, и доход утроился в годовом исчислении, так что вскоре доходы от ИИ сами по себе смогут покрыть расходы на обучающий запуск стоимостью 10 миллиардов долларов.
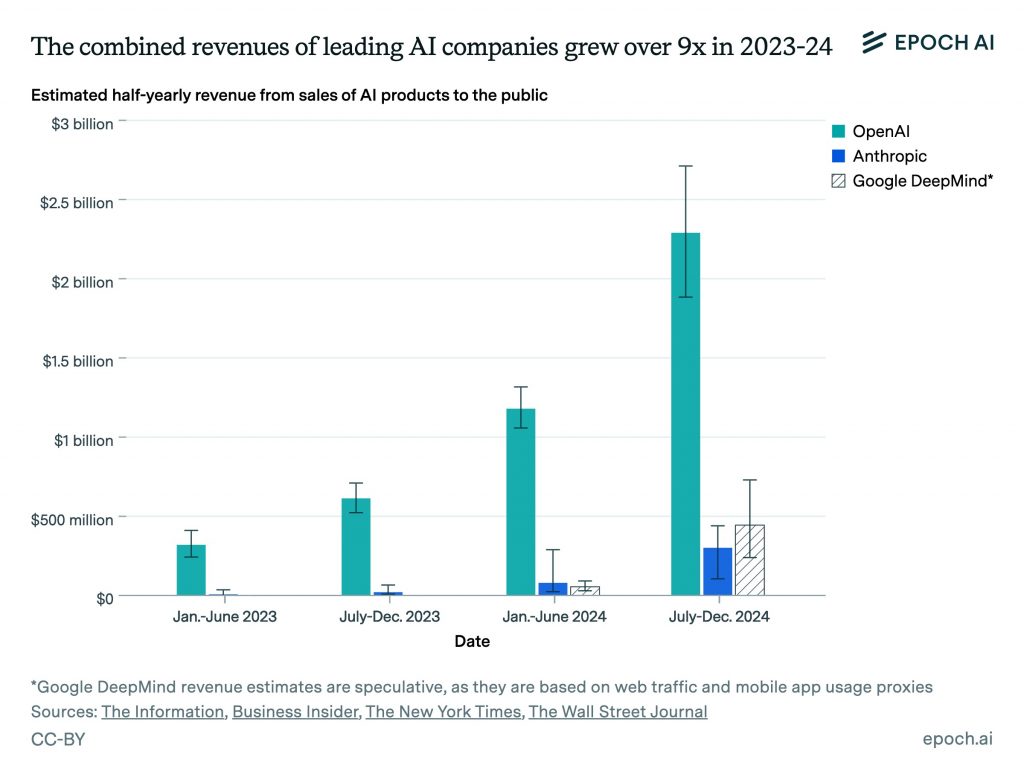
Epoch AI оценивает, что доходы передовых компаний в области ИИ растут более чем в 3 раза в год.
Microsoft заработала около 13 миллиардов долларов на ИИ в 2024 году (рост в 2.75 раза), OpenAI, возможно, 4 миллиарда долларов (рост около 3 раз), а Anthropic, вероятно, около 1 миллиарда долларов (рост в 5 раз). Кроме того, Google и Meta активно используют ИИ внутри компании для улучшения своих продуктов, что косвенно приносит доход. Многие недавно созданные ИИ-стартапы также сообщают о очень быстром росте выручки.
Я подробнее расскажу об узких местах позже, но наиболее вероятным из них являются обучающие данные. Однако лучшее исследование, которое я нашёл, предполагает, что данных будет достаточно для проведения обучающего запуска масштаба GPT-6 к 2028 году.
И даже если это не так, это уже не критично — компании в области ИИ нашли способы обойти проблему нехватки данных.
2. Постобучение моделей рассуждения с использованием обучения с подкреплением
Часто говорят: «ChatGPT просто предсказывает следующее слово». Но это никогда не было полностью правдой.
Грубое предсказание слов из Интернета приводит к регулярно абсурдным результатам (что неудивительно, учитывая, что это Интернет).
GPT стала по-настоящему полезной только с добавлением обучения с подкреплением на основе человеческой обратной связи (RLHF, Reinforcement Learning from Human Feedback):
- Результаты базовой модели показываются человеческим оценщикам.
- Оценщиков просят определить, какие результаты наиболее полезны.
- Модель корректируется, чтобы чаще выдавать такие полезные результаты («подкрепление»).
Модель, прошедшая RLHF, не просто «предсказывает следующий токен», она обучена предсказывать, что человеческие оценщики сочтут наиболее полезным.
Можно представить начальную LLM как фундамент концептуальной структуры. RLHF необходим для направления этой структуры к конкретной полезной цели.
RLHF — это одна из форм «постобучения», так названная, потому что она происходит после предварительного обучения (хотя оба процесса — просто виды обучения).
Существует множество других видов улучшений постобучения, включая такие простые вещи, как предоставление модели доступа к калькулятору или Интернету. Но сейчас особенно важен один: обучение с подкреплением для тренировки моделей в рассуждении.
Идея в том, что вместо обучения модели делать то, что люди считают полезным, её обучают правильно отвечать на задачи. Вот как это работает:
1. Показать модели задачу с проверяемым ответом, например, математическую головоломку.
2. Попросить её построить цепочку рассуждений для решения задачи («цепочка мыслей»).
Это происходит путём генерации одного токена рассуждения, затем возвращения этого токена в модель и запроса предсказать, какой следующий токен будет наиболее логичным в цепочке рассуждений, учитывая предыдущий токен, и так далее. Это называется «цепочка мыслей» или CoT.
3. Если ответ правильный, скорректировать модель, чтобы она чаще так делала («подкрепление»).
OpenAI, вероятно, также проводит обучение с подкреплением на каждом шаге рассуждения.
4. Повторить.
Этот процесс учит LLM строить длинные цепочки (правильных) рассуждений о логических задачах.
До 2023 года это, похоже, не работало. Если каждый шаг рассуждения слишком ненадёжен, цепочки быстро идут не туда. А если вы не можете приблизиться к правильному ответу, вы не можете применить подкрепление.
Но в 2024 году, когда многие говорили, что прогресс ИИ застопорился, эта новая парадигма начала набирать обороты.
Рассмотрим бенчмарк GPQA Diamond — набор научных вопросов, разработанных так, чтобы люди с докторской степенью в этой области могли на них ответить, а неспециалисты — нет, даже с 30 минутами доступа к Google. Он содержит вопросы вроде этого:

Пример научных задач уровня PhD на новом бенчмарке GPQA Diamond. Я проходил магистерский курс по теоретической физике в университете, и у меня нет идей.
В 2023 году GPT-4 показывала результат чуть лучше случайного угадывания на этом бенчмарке. Она могла справляться с рассуждениями, необходимыми для научных задач уровня старшей школы, но не с задачами уровня PhD.
Однако в октябре 2024 года OpenAI взяла базовую модель GPT-4o и использовала обучение с подкреплением, чтобы создать o1.
Они, вероятно, также выполнили несколько других шагов, таких как тонкая настройка базовой модели на наборе данных с примерами рассуждений. Они, вероятно, также проводят положительное подкрепление на основе каждого шага в рассуждении, а не только конечного ответа. OpenAI обсуждает использование моделей вознаграждения за каждый шаг в своей статье 2023 года Let’s verify step by step.
Она достигла 70% точности — примерно на уровне PhD в каждой области при ответе на эти вопросы.
Утверждать, что эти модели просто воспроизводят свои обучающие данные, больше неубедительно — ни ответы, ни цепочки рассуждений, необходимые для их получения, не существуют в Интернете.
Большинство людей не решают научные задачи уровня PhD в повседневной жизни, поэтому они просто не заметили недавнего прогресса. Они всё ещё считают LLM простыми чат-ботами.
Но это было только начало. В начале новой парадигмы улучшения могут происходить особенно быстро.
Всего через три месяца после o1 OpenAI опубликовала результаты o3. Это вторая версия, названная «o3», потому что «o2» — это телекоммуникационная компания. (Но, пожалуйста, не просите меня объяснять другие аспекты практики именования моделей OpenAI.)
o3, вероятно, это o1, но с ещё большим обучением с подкреплением (и ещё одним изменением, о котором я расскажу позже).
Она превзошла человеческий экспертный уровень на GPQA:
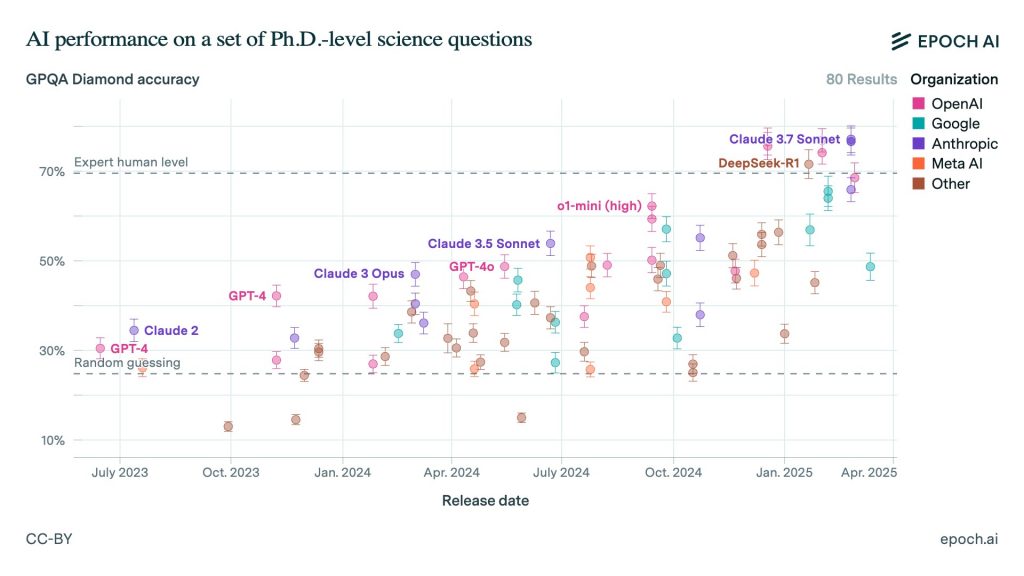
Модели ИИ не могли ответить на эти сложные научные вопросы в 2023 году лучше, чем случайно, но к концу 2024 года они могли превзойти PhD в этой области.
Обучение с подкреплением должно быть наиболее полезным для задач с проверяемыми ответами, таких как наука, математика и программирование. o3 значительно превосходит свою базовую модель во всех этих областях.
Интересно, что это противоположно предыдущему поколению систем. Изначально LLM были удивительно хороши в писательских и творческих задачах, но слабы в математике.
Большинство бенчмарков по математическим вопросам теперь насыщены — ведущие модели могут ответить правильно почти на все вопросы.
В ответ Epoch AI создала Frontier Math — бенчмарк невероятно сложных математических задач. Самые простые 25% похожи на задачи уровня олимпиад. Самые сложные 25%, по словам лауреата медали Филдса Теренса Тао, «чрезвычайно сложны» и обычно требуют эксперта в этой области математики для решения.
Предыдущие модели, включая GPT-o1, почти не могли решить ни одну из этих задач.
В тестах Epoch лучшая модель могла ответить на 2% (Рисунок 2 в анонсе). Если бы лаборатории проводили собственные тесты, результат мог бы быть немного выше.
В декабре 2024 года OpenAI заявила, что GPT-o3 может решить 25%.
Были споры о результате, поскольку OpenAI была частично вовлечена в создание бенчмарка. Однако я ожидаю, что основной вывод — o3 работала значительно лучше предыдущих моделей — всё же верен.
Эти результаты остались совершенно незамеченными в СМИ. В тот же день, когда были объявлены результаты o3, The Wall Street Journal публиковала эту историю:
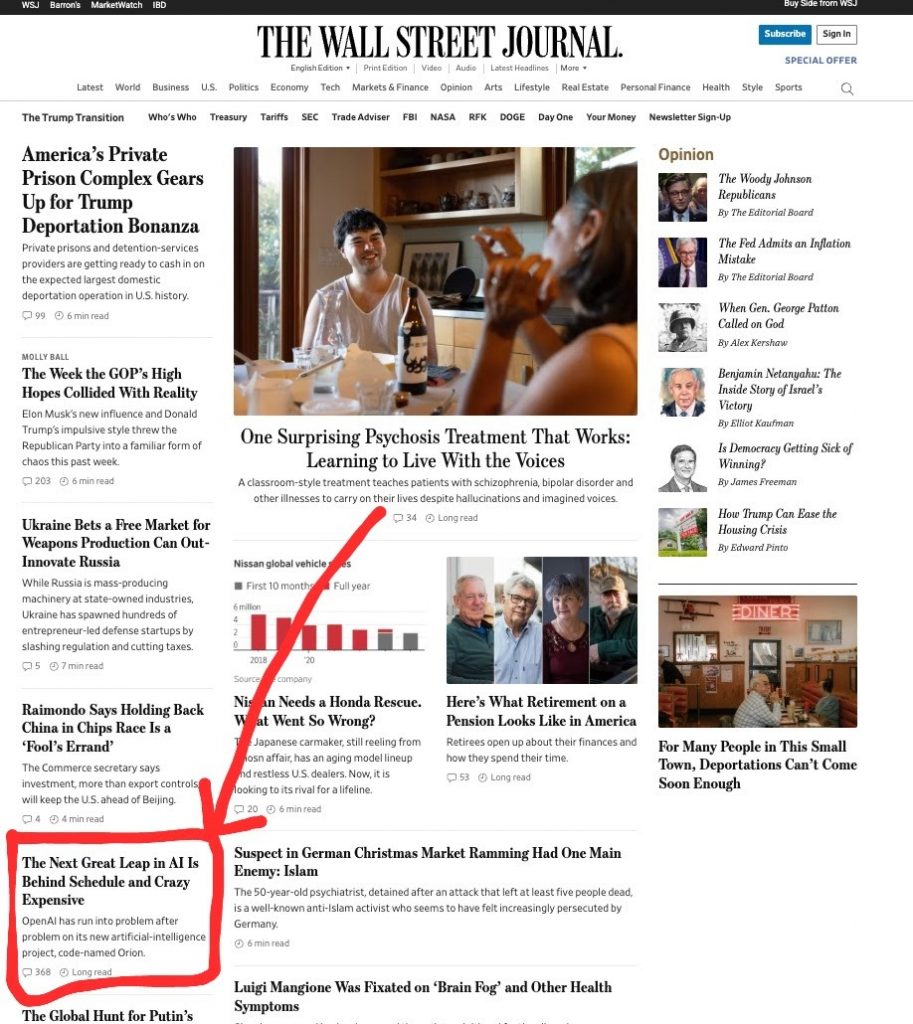
В тот же день, когда o3 продемонстрировала выдающуюся результативность на чрезвычайно сложных математических задачах, The Wall Street Journal сообщала о задержках с GPT-5 на своей главной странице.
Это упускает ключевой момент: GPT-5 больше не нужен — началась новая парадигма, которая может приносить ещё более быстрые улучшения, чем раньше. (Gadgets News: как уже отмечалось выше, в действительности релиз GPT-5 планируется, и эта модель будет интегрирована с o-моделью текущего или следующего поколения. Что касается проблем, о которых пишет FT, то разочаровавшая многих GPT-4.5, по мнению некоторых специалистов — это GPT-5, к которой пока не «прикрутили» reasoning)
Как далеко может масштабироваться обучение моделей рассуждения?
В январе DeepSeek воспроизвела многие результаты o1. Их статья показала, что даже самая простая версия процесса работает, предполагая, что есть ещё много возможностей для экспериментов.
DeepSeek-R1 также раскрывает всю цепочку рассуждений пользователю, демонстрируя её сложность и удивительно человеческое качество: она размышляет над своими ответами, возвращается назад, если ошибается, рассматривает несколько гипотез, получает озарения и многое другое.

Всё это поведение возникает из простого обучения с подкреплением. Исследователь OpenAI Себастьян Бубек отметил:
Модели не давали никаких тактик. Всё возникает само собой. Всё выучивается через обучение с подкреплением. Это безумие.
Вычисления для этапа обучения с подкреплением DeepSeek-R1, вероятно, стоили всего около 1 миллиона долларов.
Если это продолжит работать, OpenAI, Anthropic и Google теперь могут потратить 1 миллиард долларов на тот же процесс, что соответствует примерно 1000-кратному увеличению вычислений.
1 миллиард долларов легко доступен, учитывая уже собранные средства, и всё ещё дёшев по сравнению с обучением GPT-6. В терминах эффективных вычислений масштабирование может быть даже больше из-за повышения эффективности чипов и алгоритмов. Однако, если это будет применено к большим моделям, вычисления на каждый проход вперёд возрастут.
Также обратите внимание, что GPT-5 и GPT-6 могут быть отложены, поскольку вычисления будут использованы для обучения с подкреплением на этапе постобучения вместо предварительного обучения более крупной базовой LLM. Однако тенденция тратить больше на вычисления для обучения, вероятно, сохранится.
Одна из причин, почему это возможно масштабировать, заключается в том, что модели сами генерируют свои данные.
Это может звучать как замкнутый круг, и идея, что синтетические данные вызывают коллапс модели, широко обсуждалась.
Но в данном случае нет ничего кругового. Вы можете попросить GPT-o1 решить 100 000 математических задач, затем взять только те случаи, где она ответила правильно, и использовать их для обучения следующей модели.
Поскольку решения можно быстро проверить, вы генерируете больше примеров действительно хороших рассуждений.
Фактически, эти данные гораздо качественнее того, что можно найти в Интернете, потому что они содержат всю цепочку рассуждений и известно, что они правильные (чем Интернет не славится).
Кроме того, есть другие примеры полезности синтетических данных.
Это потенциально создаёт маховик:
1. Попросите модель решить множество задач.
2. Используйте решения для обучения следующей модели.
Статья DeepSeek показывает, что это можно сделать ещё проще, взяв старую модель и дистиллировав её в гораздо меньшую модель. Это позволяет получить схожую результативность, но с гораздо меньшими вычислительными затратами. Это, в свою очередь, позволяет создавать следующую партию данных дешевле.
Кроме того, тенденция 10-кратного роста алгоритмической эффективности каждые два года означает, что ваша способность производить синтетические данные увеличивается в 10 раз каждые два года. Так что даже если изначально это требует много вычислений, это быстро изменится.
3. Следующая модель может решать ещё более сложные задачи.
4. Это генерирует ещё больше решений.
5. И так далее.
Если модели уже способны к рассуждениям уровня PhD, следующий этап — это рассуждения уровня исследователя, а затем генерация новых озарений.
Это, вероятно, объясняет необычно оптимистичные заявления руководителей компаний в области ИИ. Сдвиг во мнении Сэма Альтмана точно совпадает с выпуском o3 в декабре 2024 года.
Хотя наиболее эффективно в проверяемых областях, навыки рассуждения, вероятно, будут хотя бы частично обобщаться. Мы уже видели, как o1 улучшает юридические рассуждения, например.
По словам Натана Лабенца в эпизоде его подкаста Cognitive Revolution.
В других областях, таких как бизнес-стратегия или писательство, сложнее чётко оценить успех, так что процесс занимает больше времени, но мы должны ожидать, что он сработает в какой-то степени. Как хорошо это будет работать — ключевой вопрос на будущее.
3. Увеличение времени, которое модели тратят на размышления
Если вы можете думать над задачей только минуту, вы, вероятно, не далеко продвинетесь. Если вы можете думать месяц, вы достигнете гораздо большего прогресса — даже если ваш исходный интеллект не выше.
Ранее LLM не могли думать над задачей дольше минуты, прежде чем ошибки накапливались или они отклонялись от темы, что сильно ограничивало их возможности.
Но по мере того, как модели становились надёжнее в рассуждениях, они начали лучше справляться с более длительными размышлениями.
OpenAI показала, что если дать o1 думать в 100 раз дольше, чем обычно, точность на задачах по программированию увеличивается линейно.
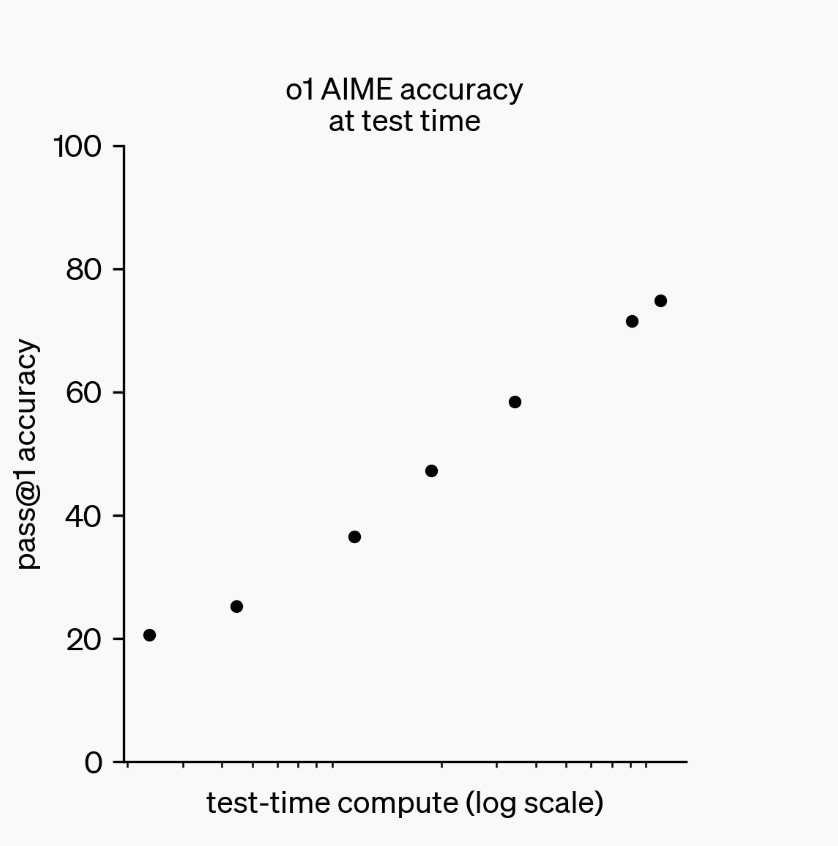
Точность на задачах по программированию увеличивается с увеличением времени, которое модель тратит на «размышления».
Это называется использованием «вычислений на этапе тестирования» — вычислений, затрачиваемых, когда модель работает, а не обучается.
Если GPT-4o могла полезно думать около одной минуты, GPT-o1 и DeepSeek-R1, похоже, могут думать эквивалентно часу.
Под этим я подразумеваю, что они могут рассуждать примерно на столько же токенов, сколько человек мог бы произвести за час, примерно 10 000. Это примерно в 100 раз больше, чем GPT-4o, что соответствует двум порядкам дополнительного вычислительного времени на тестировании, которое OpenAI показала как возможное.
По мере того как модели рассуждения становятся надёжнее, они смогут думать всё дольше и дольше. При текущих темпах вскоре у нас будут модели, которые могут думать месяц — а затем год.
(Особенно интригующе, что произойдёт, если они смогут думать бесконечно — при достаточных вычислениях и при условии, что прогресс в принципе возможен, они могли бы непрерывно улучшать свои ответы на любой вопрос.)
Использование большего количества вычислений на этапе тестирования может быть использовано для решения задач методом грубой силы. Один из методов — пытаться решить задачу 10, 100 или 1000 раз и выбирать решение с наибольшим количеством «голосов». Вероятно, это ещё один способ, которым o3 смогла превзойти o1.
Натан Лабенц обсуждает возможность использования o3 поиска по дереву в эпизоде своего подкаста Cognitive Revolution:
«Похоже, что с o3 происходит что-то, что не является просто однократным авторегрессионным развертыванием… Количество токенов, которые они генерируют в секунду, выше, чем можно реально сгенерировать одним авторегрессионным развертыванием. Так что, похоже, с o3 что-то происходит, где они нашли способ параллелизовать вычисления и получить результат. Мы не знаем, что это… Можно сделать огромное количество генераций и взять наиболее частые решения. Может быть, это так. Может быть, у них есть другой алгоритм, который агрегирует эти разные развертывания».
Есть и другие способы поиска по дереву — голосование большинства — лишь один пример.
Непосредственный практический результат всего этого в том, что вы можете платить больше, чтобы получить более продвинутые возможности раньше.
Количественно, в 2026 году я ожидаю, что вы сможете заплатить в 100 000 раз больше, чтобы получить результативность, которая ранее была бы доступна только в 2028 году.
Предположим, GPT-o7 сможет ответить на вопрос за 1 доллар в 2028 году. Вместо этого вы сможете заплатить GPT-o5 100 000 долларов, чтобы она думала в 100 000 раз дольше, и получить тот же ответ в 2026 году.
В 2023 году Epoch оценила, что вы сможете заставить модель думать в 100 000 раз дольше и получить прирост результативности, эквивалентный модели, обученной на вычислениях, в 1000 раз больших — примерно на одно поколение впереди.
В некоторых случаях можно достичь той же результативности, что и у модели, обученной с использованием на 2 порядка больше вычислений, за счёт дополнительных вычислений во время вывода. Это примерно разница между последовательными поколениями моделей GPT (например, GPT-3 и GPT-4), без учёта алгоритмического прогресса.
Pablo Villalobos and David Atkinson (2023), “Trading Off Compute in Training and Inference”.
Большинство пользователей не захотят это делать, но если у вас есть критически важная инженерная, научная или бизнес-задача, даже 1 миллион долларов — это выгодная сделка.
В частности, исследователи ИИ могут использовать эту технику для создания ещё одного маховика для исследований ИИ. Это процесс, называемый итеративной дистилляцией и усилением, о котором вы можете прочитать здесь. Вот как это примерно работает:
- Попросите модель думать дольше, чтобы получить лучшие ответы («усиление»).
- Используйте эти ответы для обучения новой модели. Эта модель теперь может выдавать почти такие же ответы сразу, без необходимости думать дольше («дистилляция»).
- Теперь попросите новую модель думать дольше. Она сможет генерировать ещё лучшие ответы, чем исходная.
- Повторите.
Именно так DeepMind сделала AlphaZero сверхчеловеческой в игре Го за пару дней без использования человеческих данных.
4. Следующий этап: создание лучших агентов
GPT-4 похож на коллегу в первый рабочий день, который умен и компетентен, но отвечает только на один-два вопроса, прежде чем покинуть компанию.
Неудивительно, что это лишь немного полезно. Но компании в области ИИ теперь превращают чат-ботов в агентов.
Агент ИИ способен выполнять длинную цепочку задач для достижения цели. Например, если вы хотите создать приложение, вместо того чтобы просить модель помочь на каждом шаге, вы просто говорите: «Создай приложение, которое делает X». Затем она задаёт уточняющие вопросы, создаёт прототип, тестирует и исправляет ошибки и предоставляет готовый продукт — подобно человеческому инженеру-программисту.
Агенты работают, беря модель рассуждения и предоставляя ей память и доступ к инструментам («каркас»):
- Вы сообщаете модулю рассуждения цель, и он составляет план для её достижения.
- На основе этого он использует инструменты для выполнения некоторых действий.
- Результаты возвращаются в модуль памяти.
- Модуль рассуждения обновляет план.
- Цикл продолжается, пока цель не достигнута (или не определено, что это невозможно).
Агенты ИИ уже немного работают. SWE-bench Verified — это бенчмарк реальных задач по разработке программного обеспечения с GitHub, которые обычно занимают около часа.
GPT-4 практически не справляется с этими задачами, потому что они требуют использования нескольких приложений.
Однако, когда его помещают в простой агентный каркас:
Согласно официальной таблице лидеров SWE-bench Verified
- GPT-4 может решить около 20%.
- Claude Sonnet 3.5 могла решить 50%.
- А GPT-o3, как сообщается, могла решить более 70%.
Это означает, что o3 примерно так же хороша, как профессиональные инженеры-программисты, в выполнении этих дискретных задач.
На соревновательных задачах по программированию она заняла бы примерно 200-е место в мире.
Вот как выглядят эти агенты по программированию в действии:
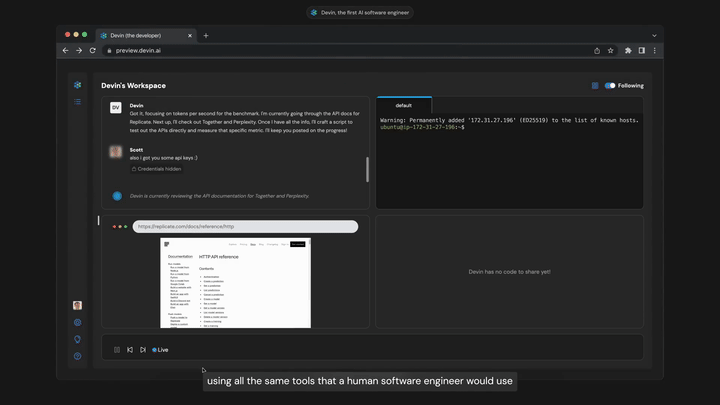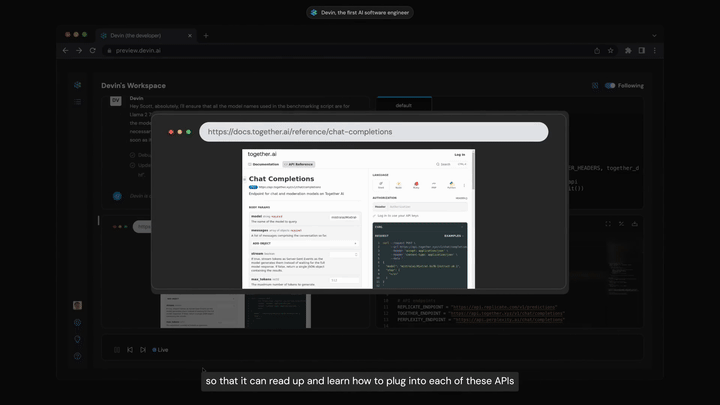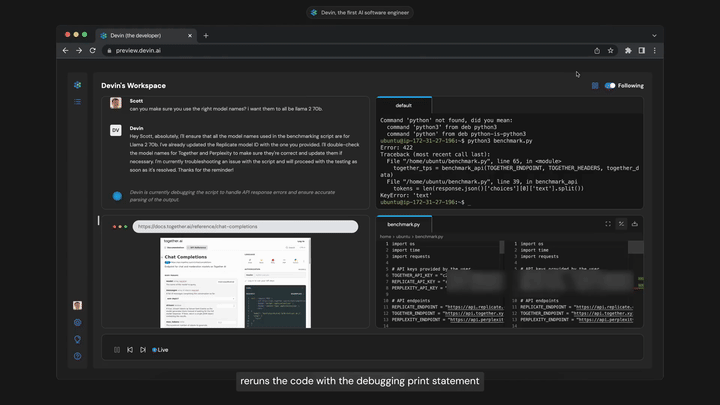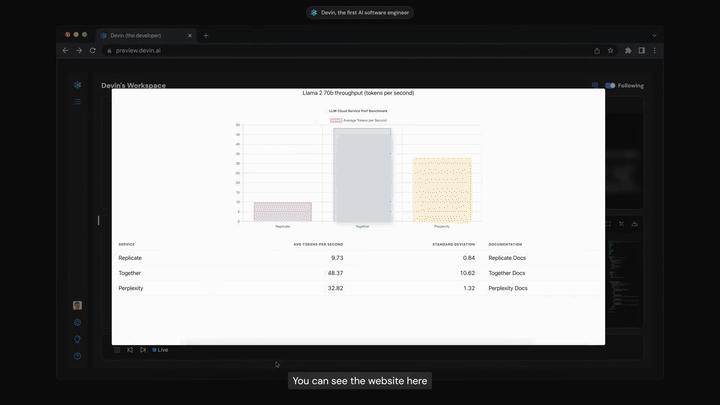
Чтобы получить представление, как это выглядит, посмотрите демо агента по программированию Devin.
Теперь рассмотрим, возможно, самый важный бенчмарк в мире: набор сложных инженерных задач по исследованию ИИ от METR («RE Bench»).
Эти задачи включают, например, тонкую настройку моделей или предсказание экспериментальных результатов, с которыми инженеры сталкиваются для улучшения передовых систем ИИ. Они были разработаны как действительно сложные задачи, близко приближающиеся к реальным исследованиям ИИ.
Простой агент, построенный на GPT-o1 и Claude 3.5 Sonnet, превосходит человеческих экспертов, когда ему дают два часа.
Эта результативность превзошла ожидания многих прогнозировщиков (и o3 ещё не тестировалась).
Многие прогнозировщики ИИ ожидали, что этот скачок займёт несколько лет. Аджейя Котра написала о том, как этот результат заставил её значительно сократить свои сроки, как и Даниэль Кокотайло.
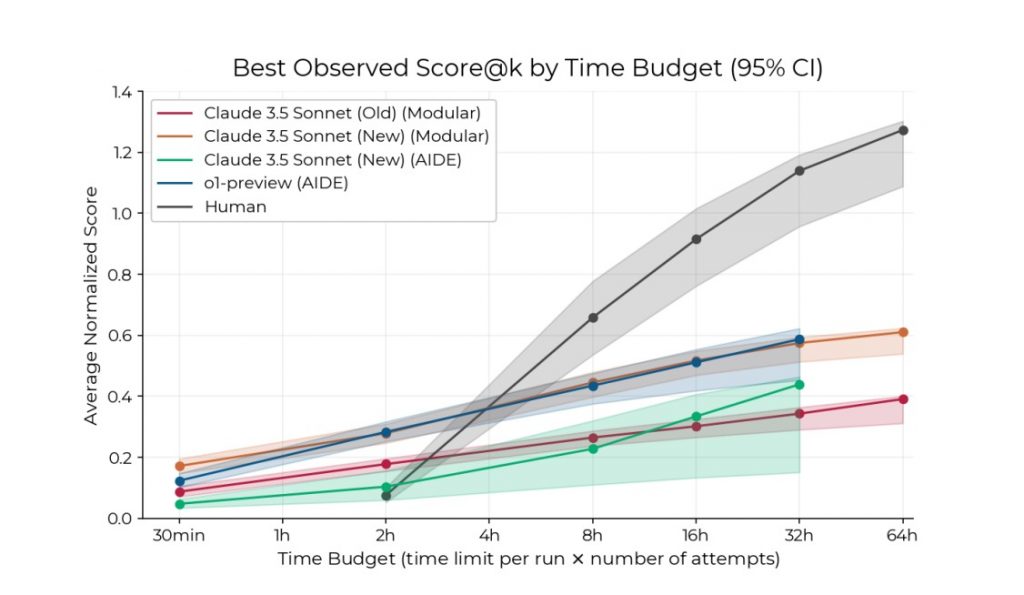
Когда даётся два часа на выполнение сложных инженерных задач по исследованию ИИ, модели превосходят людей. Если дать больше двух часов, люди всё ещё значительно превосходят модели ИИ, и это преимущество увеличивается с увеличением времени.
Источник: Wijk, Hjalmar, et al. RE-Bench: Evaluating Frontier AI R&D Capabilities of Language Model Agents against Human Experts.
Результативность ИИ увеличивается медленнее, чем человеческая, когда даётся больше времени, так что человеческие эксперты всё ещё превосходят ИИ примерно на четырёхчасовой отметке.
Но модели ИИ быстро догоняют. GPT-4o могла выполнять задачи, которые занимали у людей около 30 минут.
Согласно отчёту от Model Evaluation and Threat Research (METR):
«Предварительные оценки GPT-4o и Claude. Мы также использовали наш набор задач для оценки результативности простых базовых агентов LM, построенных с использованием моделей семейств Claude и GPT-4. Мы обнаружили, что агенты, основанные на самых способных моделях (3.5 Sonnet и GPT-4o), выполняют долю задач, сравнимую с тем, что наши человеческие базовые испытуемые могут сделать примерно за 30 минут.»
METR создала более широкий бенчмарк задач по использованию компьютеров, категоризированный по временному горизонту. GPT-2 могла выполнять задачи, которые занимали у людей несколько секунд; GPT-4 справлялась с задачами на несколько минут; а последние модели рассуждения могли выполнять задачи, которые занимали у людей чуть меньше часа.
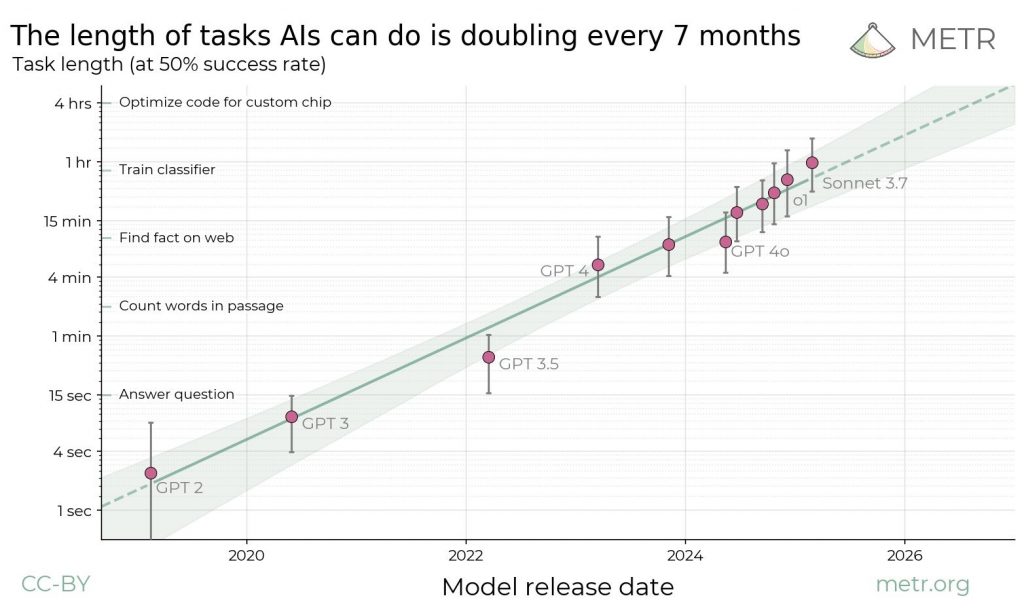
Источник: Kwa, Thomas, et al. “Measuring AI Ability to Complete Long Tasks.” arxiv.org/abs/2503.14499.
Если эта тенденция продолжится до конца 2028 года, ИИ сможет выполнять задачи по исследованию ИИ и разработке программного обеспечения, которые занимают у человеческих экспертов несколько недель.
График выше использует логарифмическую шкалу. На линейной шкале он выглядит так:
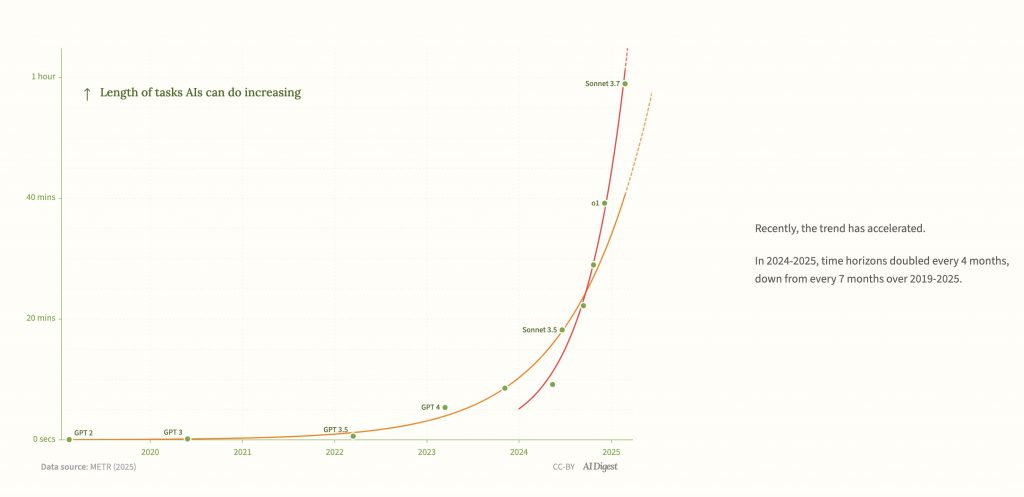
Источник: AI Digest
Красная линия показывает, что в последний год тенденция была даже быстрее, возможно, из-за парадигмы моделей рассуждения.
Обновление, апрель 2025: Результаты для o3 были опубликованы, и она, похоже, соответствует более быстрому тренду после 2024 года, а не более медленному тренду после 2020 года, обсуждаемому выше. Если это продолжится, прогресс будет почти вдвое быстрее: временной горизонт удваивается каждые четыре месяца, а не каждые семь.
Модели ИИ также всё лучше понимают свой контекст — правильно отвечают на вопросы о своей архитектуре, прошлых выводах и о том, обучаются они или используются. Это ещё одно условие для агентности.
На более лёгкой ноте, хотя Claude 3.7 всё ещё ужасно играет в Pokémon, она гораздо лучше, чем 3.5, а всего год назад Claude 3 вообще не могла играть. (Gadgets News: на момент публикации этого перевода отсутствуют конкретные данные о том насколько лучше или хуже в Pokémon играет Claude 4)
Графики выше объясняют, почему, хотя модели ИИ могут быть очень «умными» в ответах на вопросы, они ещё не автоматизировали многие рабочие места.
Большинство рабочих мест — это не просто списки дискретных часовых задач, они включают определение того, что делать, координацию с командой, длительные, новые проекты с большим количеством контекста и так далее.
Даже в одной из сильнейших областей ИИ — разработке программного обеспечения — сегодня он может выполнять задачи, которые занимают менее часа. И его всё ещё часто сбивают с толку такие вещи, как поиск нужной кнопки на веб-сайте. Это означает, что он далёк от возможности полностью заменить инженеров-программистов.
Однако тенденции предполагают, что это скоро изменится. ИИ, способный выполнять задачи длительностью в день или неделю, сможет автоматизировать значительно больше работы, чем текущие модели. Компании смогут начать нанимать сотни «цифровых работников» под руководством небольшого числа людей.
Как далеко может продолжаться улучшение агентов?
OpenAI назвала 2025 год «годом агентов».
- Хотя каркасы для агентов ИИ всё ещё примитивны, это приоритет для ведущих лабораторий, что должно привести к дальнейшему прогрессу.
- Улучшения также придут от подключения каркасов агентов к всё более мощным моделям рассуждения — предоставляя агенту более надёжный «планирующий мозг».
- В свою очередь, они будут основаны на базовых моделях, обученных на гораздо большем количестве видеоданных, что может значительно улучшить восприятие агентов — текущую основную проблему.
Как только агенты начнут немного работать, это откроет дальнейший прогресс:
- Поставьте агенту задачу, например, совершить покупку или написать популярный твит. Затем, если он успешен, используйте обучение с подкреплением, чтобы повысить вероятность успеха в следующий раз.
- Кроме того, каждая успешно выполненная задача может быть использована как обучающие данные для следующего поколения агентов.
Мир — это бесконечный источник данных, который позволяет агентам естественно развивать причинно-следственную модель мира.
Агенты также могут быть поставлены перед миллионами виртуальных тестовых задач или взаимодействовать с другими агентами. Такой «самоигровой» процесс может привести к быстрому улучшению способностей без внешних данных, как это произошло с AlphaZero (которая играла против самой себя миллионы раз, чтобы стать сверхчеловеческой в Го примерно за день).
Любая из этих мер может значительно повысить надёжность, и, как мы видели несколько раз в этой статье, улучшения надёжности могут внезапно открыть новые возможности:
- Даже простая задача, такая как поиск и бронирование отеля, соответствующего вашим предпочтениям, требует десятков шагов. При 90% вероятности правильного выполнения каждого шага общий шанс успеха в 20 шагах составляет всего 10%.
- Однако при 99% надёжности на каждом шаге общий шанс успеха взлетает с 10% до 80% — разница между бесполезностью и высокой полезностью.
Таким образом, прогресс может ощущаться весьма взрывным.
При этом агентность — наиболее неопределённый из четырёх факторов. У нас пока нет отличных бенчмарков для её измерения, так что, хотя в навигации по определённым типам задач может быть много прогресса, в других аспектах он может оставаться медленным. Несколько значительных слабостей могут ограничить применение ИИ. Возможно, потребуются более фундаментальные прорывы, чтобы это действительно заработало.
Тем не менее, недавние тенденции и вышеуказанные улучшения в разработке означают, что я ожидаю значительного прогресса.
II. Насколько мощным станет ИИ к 2030 году?
Продолжение четырёх факторов прогресса
Давайте подведём итог всему, что мы рассмотрели. Заглядывая на два года вперёд, все четыре фактора прогресса ИИ, похоже, продолжат действовать и усиливать друг друга:
- Будет выпущена базовая модель, обученная с в 500 раз большими эффективными вычислениями, чем GPT-4 («GPT-5»).
- Эта модель может быть обучена рассуждению с вычислениями, в 100 раз большими, чем у o1 («o5»).
- Она сможет думать эквивалентно месяцу над каждой задачей, когда это нужно.
- Она будет подключена к улучшенному агентному каркасу и дополнительно усилена для большей агентности.
И это не конец. Ведущие компании на пути к проведению обучающих запусков стоимостью 10 миллиардов долларов к 2028 году. Этого будет достаточно для предварительного обучения базовой модели размером с GPT-6 и проведения в 100 раз большего обучения с подкреплением (или какой-то другой комбинации).
Трудно прогнозировать, как вычисления будут распределены между предварительным обучением, постобучением и выводом. На практике они будут направлены туда, где достигаются наибольшие успехи. Возможно, большая часть вычислений для обучения будет потрачена на обучение с подкреплением, и GPT-6 будет отложена относительно старых трендов. Общая тенденция в том, сколько вычислений используется для обучения и работы моделей ИИ, более устойчива.
Кроме того, новые факторы, такие как модели рассуждения, появляются примерно каждые 1–2 года, так что мы должны прогнозировать как минимум ещё одно такое открытие в ближайшие четыре года. И есть некоторая вероятность, что мы увидим более фундаментальный прорыв, сравнимый с самим глубоким обучением.
| Фактор прогресса | 2019–2023 | 2024–2028 |
|---|---|---|
| Масштабирование эффективных вычислений для предварительного обучения | 12x в год, 300 000x всего, от GPT-2 к GPT-4 | 12x в год, 300 000x всего, от GPT-4 к GPT-6 Может быть отложено, если вычисления используются для обучения с подкреплением или вывода. |
| Постобучение | RLHF, цепочка мыслей, использование инструментов | Обучение с подкреплением на моделях рассуждения, масштабирование в 40 000x? Каков масштаб увеличения обучения с подкреплением? Предположим, на o1 было использовано 1–10 миллионов долларов вычислений. Лаборатории имеют ресурсы, чтобы потратить до 1 миллиарда долларов, если это продолжит работать, что в 100–1000 раз больше финансирования. В течение следующих четырёх лет чипы будут как минимум в 4 раза эффективнее при выводе (H100 против GB200 и того, что будет дальше). Модели будут примерно в 100 раз эффективнее алгоритмически, чем GPT-4o. Но модели могут иметь в 10 раз больше параметров (если используется GPT-5) или в 100 раз, если GPT-6, что означает, что каждый проход вперёд требует больше вычислений. Итак, в общей сложности это 400–400 000 раз больше эффективных вычислений для обучения с подкреплением к концу 2028 года. |
| Длительное размышление | Работает плохо | Размышление в 100 000x дольше над задачами высокой ценности |
| Агенты | В основном не работают | От задач длительностью 1 час до многонедельных? |
| Новый фактор или парадигматический прорыв | RLHF, цепочка мыслей, модели рассуждения, базовые агентные каркасы начали работать | ??? Растущая рабочая сила ИИ означает больше открытий |
С учётом всего этого люди, представляющие будущее как «немного улучшенные чат-боты», ошибаются. Без серьёзных сбоев прогресс не собирается здесь останавливаться.
Вероятность вторжения на Тайвань до 2030 года составляет 25% согласно Metaculus по состоянию на 11 февраля 2025 года. Вторжение на Тайвань, вероятно, приведёт к уничтожению большинства фабрик TSMC по производству чипов, что остановит поставки всех ИИ-чипов. Это, вероятно, не полностью остановит прогресс ИИ — прогресс может продолжаться некоторое время с использованием уже установленных чипов. Будет предпринято грандиозное усилие по созданию новых фабрик на американской территории (как TSMC уже сделала в Аризоне), что может возобновить поставки в течение пары лет. В то же время война с Китаем может привести к массовым инвестициям в ИИ для получения конкурентного преимущества.
Другие сценарии, которые могут существенно замедлить прогресс, включают крупную экономическую рецессию, другую глобальную катастрофу, подобную COVID, или массовое регуляторное ужесточение, вызванное общественным сопротивлением — это, вероятно, не остановит прогресс навсегда (поскольку военные и экономические преимущества слишком велики), но может значительно его задержать.
Многотриллионный вопрос — насколько продвинутым станет ИИ.
Экстраполяция тенденций возможностей ИИ
В конечном счёте никто не знает, но один из способов получить более точный ответ — экстраполировать прогресс на бенчмарках, измеряющих возможности ИИ.
Поскольку все факторы прогресса продолжают развиваться с темпами, схожими с прошлыми, мы можем примерно экстраполировать недавние темпы прогресса.
Экстраполяцию можно проводить в терминах времени или вычислений; это не сильно повлияет. Можно утверждать, что прогресс должен ускоряться, особенно для задач, подходящих для обучения с подкреплением, но давайте использовать линейные приросты для консервативности.
Вот сводка всех бенчмарков, которые мы обсудили (плюс пара других), и где мы можем ожидать их к 2026 году:
| Бенчмарк | Результаты лучших моделей в 2022 | Результаты лучших моделей в конце 2024 | Примерная экстраполяция тренда к концу 2026 |
|---|---|---|---|
| MMLU: сборник тестов по знаниям уровня колледжа и профессиональных | PaLM 69% | ~90% (насыщен) Claude Sonnet 3.5 с 5-кратным промптингом цепочки мыслей, согласно Anthropic | Насыщен |
| BIG-Bench Hard: задачи от рассуждений на основе здравого смысла до физики и социальных предубеждений, выбранные как особенно сложные для LLM в 2021 | ~70% GPT-3 и PaLM набрали около 70% в среднем по предметам с использованием рассуждений на основе цепочки мыслей (Таблица 2; Laskar, et al. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets. Май 2023, https://doi.org/10.48550/arxiv.2305.18486). С дополнительной тонкой настройкой модели могут набирать ещё больше. Например, PaLM-модель с 3-кратной цепочкой мыслей после тонкой настройки набрала около 78%. | ~90% (насыщен) | Насыщен |
| Humanity’s last exam: сборник из 3000 ещё более сложных вопросов на границе человеческих знаний | <3% GPT-4 может получить около 3%. Лучшие модели 2022 года, вероятно, были бы хуже. o3-mini теперь может получить 13%. https://agi.safe.ai/ | 9% | Уже 25% в феврале 2025. 40% до насыщения? |
| SWE-bench Verified: реальные задачи по разработке ПО с GitHub, обычно занимающие менее часа | <10% | 70% (примерно уровень человеческого эксперта) | Насыщен |
| GPQA Diamond: научные вопросы уровня PhD, разработанные так, чтобы их нельзя было найти в Google | Случайное угадывание (25%) | ~90% (выше уровня PhD в соответствующей дисциплине) | Насыщен |
| MATH: вопросы по математике уровня школьных соревнований | 50% | 100% | 100% |
| FrontierMath: математические вопросы, требующие профессиональных математиков в соответствующей области | 0% | 25% | 50% до насыщения? |
| RE-bench: семь сложных инженерных задач по исследованию ИИ | Не справляется ни с одной | Лучше экспертов с двумя часами | Лучше экспертов с 10–100 часами |
| METR Time horizon benchmark: задачи по разработке ПО, кибербезопасности и инженерии ИИ | Задачи, которые люди выполняют за 1 минуту | Задачи, которые люди выполняют за 30 минут | Задачи, которые люди выполняют за 6 часов |
| Situational Awareness: вопросы, проверяющие, понимает ли модель себя и контекст | <30% | 60% | 90%? |
Это предполагает, что через два года мы должны ожидать системы ИИ, которые:
- Обладают экспертными знаниями во всех областях.
- Могут отвечать на вопросы по математике и науке так же хорошо, как многие профессиональные исследователи.
- Превосходят людей в программировании.
- Имеют общие навыки рассуждения лучше, чем почти у всех людей.
- Могут автономно выполнять многие задачи длительностью в день на компьютере.
- И всё ещё быстро совершенствуются.
Следующий скачок может привести нас к решению задач сверхчеловеческого уровня — способности самостоятельно отвечать на пока нерешённые научные вопросы.
Какие рабочие места смогут поддерживать эти системы?
Множество узких мест препятствует реальному развёртыванию агентов ИИ, даже тех, что могут использовать компьютеры. К ним относятся регулирование, нежелание позволять ИИ принимать решения, недостаточная надёжность, институциональная инерция и отсутствие физического присутствия.
Хотя алгоритмы робототехники также быстро совершенствуются, это может быть не сильно отстаёт.
Изначально мощные системы также будут дорогими, и их развёртывание будет ограничено доступными вычислениями, так что они будут направлены только на самые ценные задачи.
Это означает, что большая часть экономики, вероятно, продолжит функционировать как обычно ещё некоторое время. Вы всё ещё будете консультироваться с человеческими врачами (даже если они используют инструменты ИИ), покупать кофе у человеческих бариста и нанимать человеческих сантехников.
Однако есть несколько ключевых областей, где, несмотря на эти узкие места, эти системы могут быть быстро развёрнуты с значительными последствиями.
Разработка программного обеспечения
Это область, где ИИ применяется наиболее активно уже сегодня. Google сообщила, что около 25% их нового кода пишется ИИ. Стартапы Y Combinator говорят, что это 95%, и что они растут в несколько раз быстрее, чем раньше.
Если программирование станет в 10 раз дешевле, мы будем использовать его гораздо больше. Возможно, вскоре мы увидим софтверные стартапы стоимостью в миллиард долларов с небольшим числом человеческих сотрудников и сотнями агентов ИИ. Несколько ИИ-стартапов уже стали самыми быстрорастущими компаниями всех времён.
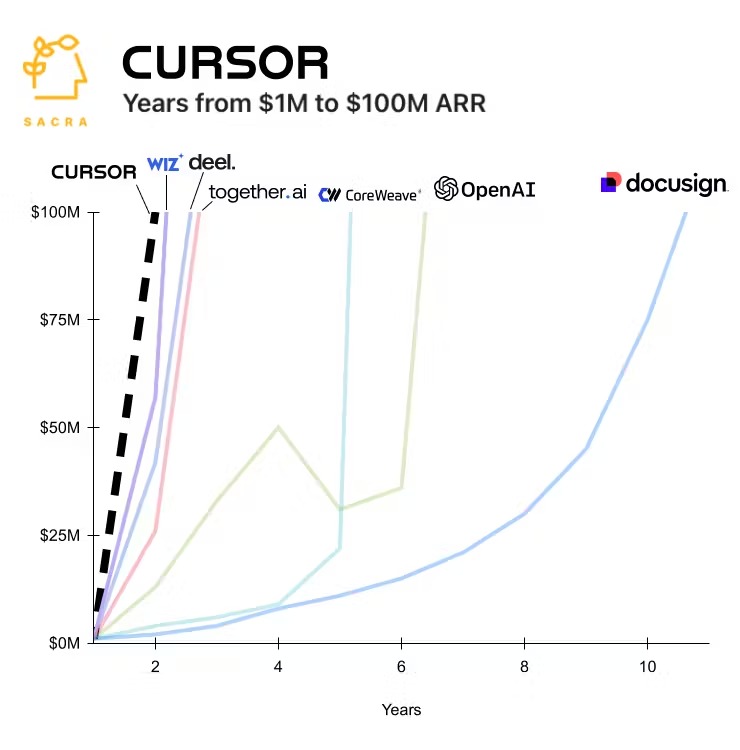
Когда OpenAI запустилась, она была самым быстрорастущим стартапом всех времён по доходам. С тех пор несколько других ИИ-компаний побили рекорд, последней стала Cursor (агент по программированию). Для сравнения на графике показан Docusign, типичный успешный SaaS-стартап до волны ИИ. Источник.
Таким образом, это узкое применение ИИ может быстро создать экономическую ценность в сотни миллиардов долларов — достаточно для финансирования дальнейшего масштабирования ИИ.
Применение ИИ в экономике может значительно расшириться отсюда. Например, Epoch оценивает, что около трети рабочих задач можно выполнять удалённо через компьютер, и их автоматизация может более чем удвоить экономику.
Научные исследования
Создатели AlphaFold уже получили Нобелевскую премию за разработку ИИ, решающего проблему свёртывания белков.
Модели ИИ также обнаружили сотни тысяч стабильных кристаллов, которые можно использовать в материаловедении и создавать более быстрые и точные прогнозы погоды.
Ранее в этой секции упоминалась исследовательская статья, в которой утверждалось, что инструмент ИИ сделал ведущих учёных-материаловедов на 80% продуктивнее в поиске новых материалов. MIT с тех пор расследовал эту статью и попросил отозвать её из обсуждения. Университет заявил, что «не имеет уверенности в происхождении, надёжности или достоверности данных и не имеет уверенности в правдивости исследований, содержащихся в статье».
Будущие модели могут быть способны генерировать действительно новые озарения, просто когда их об этом попросят. Но даже если нет, многое в науке поддаётся грубой силе. В частности, в любой области, которая в основном виртуальна, но имеет проверяемые ответы — например, математика, экономическое моделирование, теоретическая физика или информатика — исследования могут быть ускорены путём генерации тысяч идей и последующей проверки, какие из них работают.
Даже экспериментальная область, такая как биология, ограничена такими вещами, как программирование и анализ данных, ограничения, которые могут быть существенно сняты.
Одно изобретение, такое как ядерное оружие, может изменить ход истории, так что воздействие любого ускорения здесь может быть драматичным.
Исследования ИИ
Область, особенно поддающаяся ускорению, — это сами исследования ИИ. Помимо того, что она полностью виртуальна, это область, которую исследователи ИИ понимают лучше всего, имеют огромные стимулы автоматизировать и не сталкиваются с барьерами для развёртывания ИИ.
Изначально это будет выглядеть как использование исследователями агентов ИИ уровня стажёров для снятия блокировок на конкретных задачах или инженерных мощностей по программированию (что является основным узким местом), или даже для помощи в мозговом штурме идей.
Позже это может выглядеть как чтение моделями всей литературы, генерация тысяч идей для улучшения алгоритмов и автоматическое тестирование их в мелкомасштабных экспериментах.
Модель ИИ уже создала исследовательскую статью по ИИ, которая была принята на конференционный семинар. Вот список других способов, которыми ИИ уже применяется в исследованиях ИИ.
Учитывая всё это, вероятно, у нас будут агенты ИИ, занимающиеся исследованиями ИИ, раньше, чем люди разберутся со всеми нюансами, позволяющими ИИ выполнять большинство удалённых рабочих задач.
Широкое экономическое применение ИИ, таким образом, не обязательно хороший способ измерять прогресс ИИ — оно может последовать взрывообразно после того, как возможности ИИ уже значительно продвинутся.
Аргументы против впечатляющего прогресса ИИ к 2030 году
Вот самый сильный контраргумент, на мой взгляд. Сначала признать, что ИИ, вероятно, станет сверхчеловеческим в чётко определённых, дискретных задачах, что означает, что мы увидим дальнейший быстрый прогресс на бенчмарках.
Но утверждать, что он останется слабым в нечётко определённых, высококонтекстных и длительных по времени задачах. Это потому, что такие задачи не имеют чётко и быстро проверяемых ответов, так что их нельзя обучать с помощью обучения с подкреплением, и они также не содержатся в обучающих данных.
Это означает, что темпы прогресса в таких задачах будут медленными и могут даже достичь плато. Если также утверждать, что начальная позиция слабая, то даже после 4–6 лет прогресса он всё ещё может быть плохим.
Во-вторых, утверждать, что большинство интеллектуальных работ в значительной степени состоят из этих длительных, хаотичных, высококонекстных задач.
Например, инженеры-программисты тратят много времени на определение того, что строить, координацию с другими и понимание огромных кодовых баз, а не на выполнение списка чётко определённых задач. Даже если их эффективность в программировании увеличится в 10 раз, если программирование составляет только 50% их работы, их общая эффективность примерно удвоится.
Главный пример хаотичной, нечётко определённой задачи — это получение новых исследовательских озарений, так что можно утверждать, что эта задача, особенно важная для запуска ускорения, вероятно, будет самой сложной для автоматизации (в отличие от тех, кто думает, что исследования ИИ могут быть легче автоматизировать, чем многие другие работы).
В этом сценарии у нас будут чрезвычайно умные и осведомлённые помощники ИИ и, возможно, ускорение в некоторых ограниченных виртуальных областях (например, исследованиях математики), но они останутся инструментами, а люди останутся главным экономическим и научным узким местом.
Исследователи ИИ увидят рост своей эффективности, но недостаточный для запуска цикла положительной обратной связи — прогресс ИИ останется ограниченным новыми озарениями, человеческой координацией и вычислениями.
Эти ограничения, в сочетании с проблемами поиска бизнес-модели и другими барьерами для развёртывания ИИ, будут означать, что модели не создадут достаточно дохода для оправдания обучающих запусков стоимостью более 10 миллиардов долларов. Это будет означать, что прогресс резко замедлится после примерно 2028 года. Как только прогресс замедлится, маржа прибыли на фронтирных моделях рухнет, что сделает ещё сложнее оплату дальнейших обучений.
Если рост доходов прекратится сейчас, возможно, люди даже не захотят финансировать обучающие запуски стоимостью 10 млрд, но мы уже близки к созданию достаточно больших кластеров, и есть достаточно игроков (xAI, Meta, Google), которые могли бы рискнуть, так что потребуется многое, чтобы никто не попытался это сделать на этом этапе.
Главный контраргумент — это более ранний график от METR: модели улучшаются в действиях на более длительных горизонтах, что требует более глубокого понимания контекста и обработки более абстрактных, сложных задач. Экстраполяция этой тенденции предполагает гораздо более автономные модели в течение четырёх лет.
Это может быть достигнуто через множество постепенных улучшений, которые я описал, но также возможно, что мы увидим более фундаментальную инновацию — сам человеческий мозг доказывает, что такие способности возможны.
Например, можно добиться прогресса в создании агентов с длительным горизонтом через:
- Более крупные мультимодальные запуски предварительного обучения, делающие модели более надёжными на каждом шаге и лучше воспринимающими.
- Улучшенные модели рассуждения, думающие дольше, чтобы лучше планировать.
- Улучшенные каркасы агентов.
- Прямое обучение агентности с помощью RL.
- Слабые модели агентов, генерирующие обучающие данные для более мощных.
Кроме того, задачи с длительным горизонтом, скорее всего, можно разбить на более короткие задачи (например, составить план, выполнить первый шаг и т.д.). Если ИИ станет достаточно хорош в коротких задачах, то задачи с длительным горизонтом могут быстро начать работать.
Это, пожалуй, центральный вопрос прогнозирования ИИ прямо сейчас: достигнет ли горизонт, на котором могут действовать ИИ, плато или продолжит улучшаться?
Вот ещё несколько способов, которыми прогресс ИИ может быть медленнее или менее впечатляющим:
- Бестелесный когнитивный труд может оказаться не очень полезным, даже в науке, поскольку инновации возникают из обучения на практике по всей экономике. Требуется более широкая автоматизация (которая займёт гораздо больше времени). Подробнее.
- Предварительное обучение может иметь большие убывающие отдачи, так что GPT-5 и GPT-6 будут разочаровывающими (возможно, из-за ухудшения качества данных).
- ИИ продолжит быть плохим в визуальном восприятии, ограничивая его способность использовать компьютер (см. парадокс Моравеца). В целом, способности ИИ могут оставаться очень неравномерными — слабыми в измерениях, которые ещё не хорошо поняты, и это может ограничить их применение.
- Бенчмарки могут серьёзно переоценивать прогресс из-за проблем с загрязнением данных и трудностей с захватом хаотичных задач.
- Экономический кризис, конфликт на Тайване, другая катастрофа или массовое регуляторное ужесточение могут задержать инвестиции на несколько лет.
- Могут быть другие непредвиденные узкие места (см. ошибку планирования).
Для более глубокого изучения скептической точки зрения см. «Are we on the brink of AGI?» Стива Ньюмана, «The promise of reasoning models» Мэттью Барннетта, «A bear case: My predictions regarding AI progress» Тейна Рутениса и подкаст Дваркеша с Epoch AI.
В конечном счёте, доказательства никогда не будут решающими в ту или иную сторону, и оценки будут зависеть от суждений, по которым люди могут обоснованно расходиться. Однако мне трудно смотреть на доказательства и не придавать значительную вероятность AGI к 2030 году.
Когда эксперты ожидают появления AGI?
Я сделал несколько громких заявлений. Как неспециалисту, было бы здорово, если бы эксперты могли сказать нам, что думать.
К сожалению, таких экспертов нет. Есть только разные группы с разными недостатками. Я рассмотрел взгляды этих групп экспертов в отдельной статье.
Один поразительный момент — каждая группа резко сократила свои оценки. Сегодня даже многие «скептики» в области ИИ считают, что AGI будет достигнута через 20 лет — в середине карьеры сегодняшних студентов колледжей.
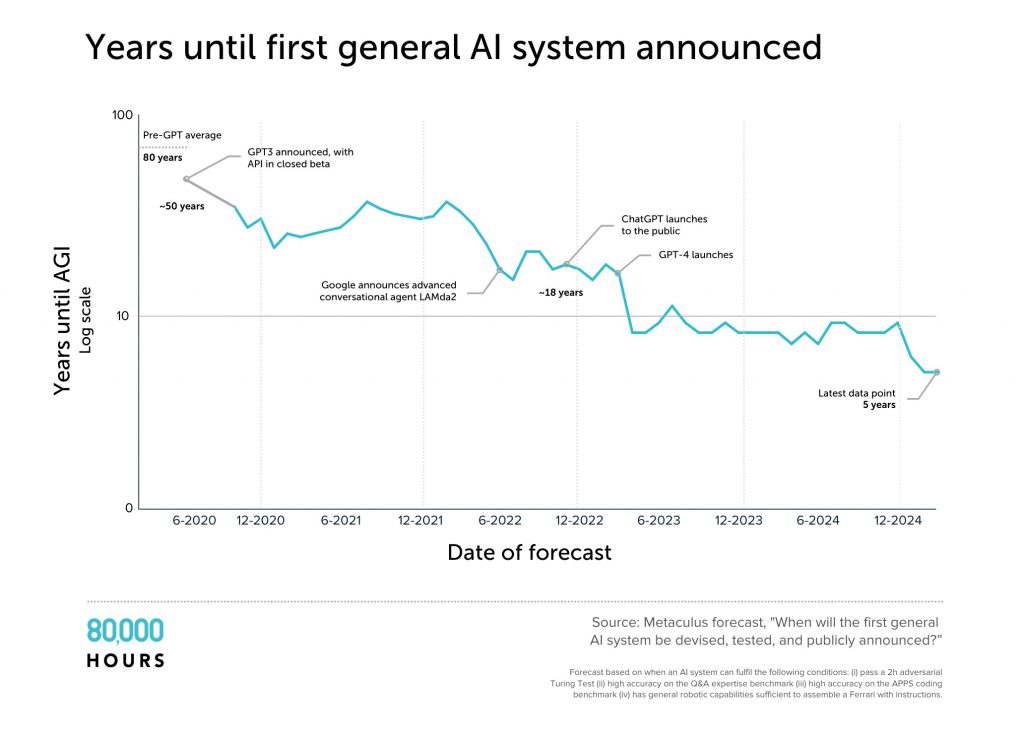
За четыре года средняя оценка на Metaculus того, когда будет разработан AGI, рухнула с 50 лет до пяти лет. Есть проблемы с используемым определением, но график отражает более широкую тенденцию сокращения оценок.
Моя общая оценка такова, что AGI к 2030 году находится в пределах экспертного мнения, так что отмахиваться от этого как от «научной фантастики» неоправданно. Действительно, люди, которые больше всего знают о технологии, похоже, имеют самые короткие сроки.
Конечно, многие эксперты считают, что это займёт гораздо больше времени. Но если 30% экспертов думают, что самолёт взорвётся, а остальные 70% считают, что всё будет в порядке, как неспециалисты мы не должны заключать, что этого точно не произойдёт. Если что-то неопределённо, это не значит, что этого не случится.
III. Почему следующие 5 лет важны
Естественно предположить, что, поскольку мы не знаем, когда появится AGI, это может случиться скоро, в 2030-х, 2040-х и так далее.
Хотя это распространённая точка зрения, я не уверен, что она верна. Основные движущие силы прогресса ИИ — это больше вычислений и лучшие алгоритмы.
Более мощный ИИ, скорее всего, будет открыт, когда вычисления и труд, используемые для улучшения ИИ, растут наиболее драматично.
Сейчас общий объём вычислений, доступных для обучения и работы ИИ, растёт в 3 раза в год, и рабочая сила также быстро увеличивается.
Общие расходы на ИИ-чипы увеличиваются примерно в 2 раза в год (оценка на основе годовых отчётов NVIDIA), а эффективность этих чипов для выполнения задач ИИ увеличивается примерно в 1.6 раза в год (экстраполировано из расходов и вычисления для обучения). Вычисления для обучения росли примерно в 4 раза в год, поскольку большая часть вычислений была выделена на тренировочные запуски.
Это означает, что каждый год количество моделей ИИ, которые можно запустить, увеличивается в 3 раза. Кроме того, в три раза больше вычислений можно использовать для обучения, и это обучение может использовать лучшие алгоритмы, что делает модели более способными и многочисленными.
Ранее я утверждал, что эти тенденции могут продолжаться до 2028 года. Но теперь я покажу, что они, скорее всего, столкнутся с узкими местами (бутылочными горлышками) вскоре после этого.
Бутылочные горлышки около 2030 года
Сначала деньги:
- Google, Microsoft, Meta и др. тратят десятки миллиардов долларов на строительство кластеров, которые могли бы обучить модель размером с GPT-6 в 2028 году.
- Ещё одно 10-кратное масштабирование потребовало бы сотен миллиардов инвестиций. Это возможно, но больше их текущей годовой прибыли и было бы сравнимо с ещё одной программой «Аполлон» или проектом «Манхэттен» по масштабу.
- GPT-8 потребовала бы триллионов. ИИ должен был бы стать главным военным приоритетом или уже приносить триллионы долларов дохода (что, вероятно, уже означало бы AGI).
Даже если деньги есть, будут и другие узкие места, такие как:
- Энергия: Текущие уровни продаж чипов для ИИ, если их поддерживать, означают, что чипы ИИ будут использовать более 4% электроэнергии США к 2028 году, но ещё одно 10-кратное масштабирование составило бы более 40%. Это возможно, но потребовало бы строительства множества электростанций.
Этот показатель рассчитан на основе продаж чипов для ИИ и находится в пределах оценок других экспертов:
- Согласно данным Управления энергетической информации США, текущая мощность электроэнергетики США составляет примерно 1230 ГВт.
- Согласно отчету RAND о потребностях ИИ в электроэнергии в условиях экспоненциального роста, в период с 2024 по 2028 год мощность электроэнергетики США увеличится почти на 160 ГВт.
- В отчете RAND оценивается, что потребности ИИ в электроэнергии к 2028 году достигнут 117 ГВт (8.4 % от общего объема поставок в США), но следует отметить, что другие оценки Goldman Sachs, McKinsey и SemiAnalysis варьируются от 3.5 до 5 %.
- Производство чипов: Taiwan Semiconductor Manufacturing Company (TSMC) производит все ведущие чипы для ИИ в мире, но её самые передовые мощности всё ещё в основном используются для мобильных телефонов. Это означает, что TSMC может комфортно производить в 5 раз больше чипов для ИИ, чем сейчас. Однако достижение 50-кратного увеличения было бы огромной задачей.
Их общая мощность в терминах пластин — единицы измерения в производстве чипов — только недавно увеличилась на ~10% в годе (или чуть выше, если скорректировать на транзисторы на пластину), поэтому, как только существующая ведущая мощность пластин будет использоваться для ИИ, темпы роста значительно замедлятся. Новые фабрики можно построить за два года, и они могли бы строить их гораздо быстрее, чем в прошлом, если бы было достаточно финансирование, но, вероятно, медленнее, чем текущий темп роста 2x.
Узнайте больше в статье Can AI scaling continue through 2030? от Epoch AI.
- «Ограничения задержки» также могут предотвратить обучающие запуски размером с GPT-7.
Epoch обсуждает этот bottleneck в Data movement bottlenecks to LLM scaling. Хотя инновации до сих пор не были сосредоточены на этом bottleneckе, я бы предположил, что можно преодолеть ограничения, описанные в отчете. Этот bottleneck также не помешает проводить много обучения с подкреплением на меньшей модели.
Erdil, Ege, and David Schneider-Joseph. “Data Movement Limits to Frontier Model Training.” ArXiv.org, 2024, arxiv.org/abs/2411.01137.
Таким образом, скорее всего, темпы роста вычислений замедлятся около 2028–2032 годов.
Алгоритмический прогресс также сейчас очень быстр, но по мере совершения каждого открытия следующее становится всё сложнее. Поддержание постоянного темпа прогресса требует экспоненциально растущей рабочей силы исследователей.
В 2021 году в OpenAI было около 300 сотрудников; сегодня их около 3000. Anthropic и DeepMind также выросли более чем в 3 раза, и появились новые компании. Количество статей по машинному обучению, публикуемых в год, примерно удваивается каждые два года.
Трудно точно определить рабочую силу людей, которые действительно продвигают возможности (в отличие от продажи продукта или проведения других исследований в области машинного обучения). Но если рабочая сила должна удваиваться каждые 1–3 года, это может продолжаться лишь ограниченное время, пока не исчерпается пул талантов.
Существуют аналогичные динамики с эффективностью чипов, которая росла быстрее, чем закон Мура, за счёт адаптации чипов к рабочим процессам ИИ, например, переход с FP32 на tensor-FP16 привёл к 10-кратному увеличению эффективности согласно данным Epoch AI:
По сравнению с использованием не тензорного FP32, TF32, tensor-FP16 и tensor-INT8 обеспечивают примерно в 6 раз, 10 раз и 12 раз большую производительность в среднем в совокупных тенденциях производительности.
Однако это не может продолжаться бесконечно без экспоненциально растущей рабочей силы исследователей чипов.
Моя оценка такова, что рост легко может продолжаться до конца десятилетия, но, вероятно, начнёт замедляться в начале 2030-х годов (если только ИИ не станет достаточно хорош, чтобы заменить исследователей ИИ к тому времени).
Алгоритмический прогресс также зависит от увеличения вычислений, которые позволяют проводить больше экспериментов. При достаточных вычислениях исследователи могут даже проводить поиск оптимальных алгоритмов методом полного перебора. Таким образом, замедление роста вычислений соответственно замедлит алгоритмический прогресс.
Если вычисления и эффективность алгоритмов будут расти только на 50% в год вместо 3x, скачок, эквивалентный переходу от GPT-3 к GPT-4, займёт более 14 лет вместо 2,5.
Это также снижает вероятность открытия новой парадигмы ИИ.
Таким образом, идёт гонка:
- Могут ли модели ИИ улучшиться достаточно, чтобы генерировать достаточно дохода для оплаты следующего раунда обучения, прежде чем это станет недоступным?
- Могут ли модели начать вносить вклад в исследования алгоритмов, прежде чем мы исчерпаем человеческих исследователей, брошенных на эту проблему?
Момент истины наступит около 2028–2032 годов. Либо прогресс замедлится, либо ИИ сам преодолеет эти узкие места, позволяя прогрессу продолжаться или даже ускоряться.
Два потенциальных будущего для ИИ
Если ИИ, способный вносить вклад в исследования ИИ, не будет достигнут до 2028–2032 годов, годовая вероятность его открытия существенно снизится.
Прогресс не остановится внезапно — он будет замедляться постепенно. Вот некоторые иллюстративные оценки вероятности достижения AGI (не цитируйте меня по точным числам!):
Очень грубо, мы можем планировать два сценария:
Точнее, мы могли бы разделить на несколько сценариев: вероятность AGI через пять лет, вероятность появления в 2030-х годах (вероятно, ниже); вероятность появления в 2040-х годах (ещё ниже) и т.д. Фокус на двух — это упрощение.
- Либо мы достигнем ИИ, который может вызвать трансформационные эффекты, к ~2030 году: прогресс ИИ продолжится или даже ускорится, и мы, вероятно, вступим в период взрывных изменений.
- Либо прогресс замедлится: модели ИИ станут гораздо лучше в чётко определённых задачах, но не смогут выполнять нечётко определённую работу с длительным горизонтом, необходимую для запуска нового режима роста. Мы увидим много автоматизации ИИ, но в остальном мир будет выглядеть более «нормальным».
Мы узнаем гораздо больше о том, в каком сценарии мы находимся, в ближайшие несколько лет.
Я примерно оцениваю эти сценарии как 50:50 — хотя мои оценки могут варьироваться от 30% до 80% в зависимости от дня.
Возможны также гибридные сценарии — масштабирование может замедляться более постепенно или быть отложено на несколько лет из-за конфликта на Тайване, отодвигая «AGI» на начало 2030-х. Но полезно начать с простой модели.
Числа, которые вы присваиваете каждому сценарию, также зависят от вашего определения AGI и того, что вы считаете трансформационным. Я больше всего заинтересован в прогнозировании ИИ, который может существенно вносить вклад в исследования ИИ.
Ключевой момент — это когда команда исследователей-людей с помощью ИИ более чем в 2 раза продуктивнее, чем команда без ИИ, поскольку это эквивалентно удвоению рабочей силы исследователей ИИ, что может быть достаточно для запуска цикла положительной обратной связи. См. подробнее.
AGI в смысле модели, которая может выполнять почти все удалённые рабочие задачи дешевле, чем человек, может занять больше времени из-за длинного ряда узких мест. С другой стороны, AGI в смысле «лучше почти всех людей в рассуждениях, когда даётся час», похоже, уже почти здесь.
Заключение
Итак, будет ли у нас AGI к 2030 году? Каково бы ни было точное определение, есть значительные доказательства в пользу этой возможности — нам может потребоваться лишь поддерживать текущие тенденции ещё несколько лет.
У нас никогда не будет решающих доказательств ни в одну, ни в другую сторону, но мне кажется явно излишне самоуверенным думать, что вероятность до 2030 года ниже 10%.
Учитывая огромные последствия и серьёзные риски, есть достаточно доказательств, чтобы относиться к этой возможности чрезвычайно серьёзно.
Сегодняшняя ситуация ощущается как февраль 2020 года, незадолго до локдаунов из-за COVID: чёткая тенденция указывала на скорые, масштабные изменения, но большинство людей продолжали жить как обычно.
В предстоящей статье я буду утверждать, что автоматизация ИИ большей части удалённой работы и удвоение экономики может быть консервативным исходом.
Если ИИ сможет заниматься исследованиями ИИ, разрыв между AGI и «суперинтеллектом» может быть коротким. Это может вызвать массовое расширение исследовательской рабочей силы, потенциально обеспечивая столетие научного прогресса менее чем за десятилетие. Робототехника, биоинженерия и космические поселения могут наступить гораздо раньше, чем обычно ожидается.
Следующие пять лет станут началом одного из самых ключевых периодов в истории.
Дополнительная литература
Пожалуй, лучший аргумент в пользу быстрого краткосрочного прогресса ИИ — это глава 1 из Situational Awareness Леопольда Ашенбреннера.
AI 2027 — это наиболее тщательная попытка конкретного анализа сценария, в котором AGI появляется в ближайшее время благодаря автоматизации исследований ИИ. Это не попытка предсказать наиболее вероятный исход, а скорее глубокое исследование одного сценария. Однако команда также предоставляет свои всесторонние прогнозы нескольких ключевых исходов в сопровождающих исследованиях.
Наиболее влиятельный аргумент против краткосрочного появления AGI, вероятно, — это The case for multidecade AI timelines Эге Эрдиля, опубликованное Epoch AI. Эге и Тамай обсудили эти идеи в подкасте Дваркеша в апреле 2025 года. (Конечно, 30 лет — это не долго в историческом масштабе, и Эге всё ещё считает, что ИИ окажет трансформационное воздействие на общество.)
Томас Пуэйо предлагает более доступное введение, охватывающее материал, схожий с этой статьёй: The most important time in history is now.
Reinforcement learning works! — подкаст Натана Лабенца — хорошее объяснение моделей рассуждения и того, почему они могут открыть путь к значительному прогрессу. Хелен Тонер добавляет полезное резюме дебатов о том, как далеко это может зайти.
Epoch AI имеет обзор всех различных способов прогнозирования ИИ. Все они совместимы с появлением AGI до 2030 года, хотя некоторые дают меньшие вероятности. (Несколько оценок также сократились после написания статьи.)
Epoch AI также предоставляет множество отличных наборов данных, которые лежат в основе этой статьи. См. их страницу ключевых трендов для обзора и их статью Can scaling continue through 2030.
Подход к прогнозированию ИИ, который был популярен несколько лет назад, заключается в оценке вычислений, используемых для «обучения» человеческого мозга, и последующей оценке, когда ведущие модели ИИ могут превзойти этот уровень (вкратце: мы, возможно, уже близки к этому). См. Forecasting transformative AI: the ‘biological anchors’ method in a nutshell Холдена Карнофски для введения.
When do experts expect AGI? — это дополнительная статья к данному посту о том, что мы можем узнать из прогнозов экспертов. Также см. Through a glass darkly Скотта Александра, которая более глубоко исследует эту тему.
Вот некоторые из лучших статей, которые я видел, аргументирующих против трансформационного прогресса ИИ в ближайшие годы: Are we on the brink of AGI? Стива Ньюмана, The promise of reasoning models Мэттью Барннетта, A bear case: My predictions regarding AI progress Тейна Рутениса, Эге и Тамай в подкасте Дваркеша, а также Why I don’t think AGI is around the corner Дваркеша Пателя, который утверждает, что непрерывное обучение может быть значительным узким местом (хотя см. обсуждение в комментариях).
Три причины, по которым AGI может появиться только через десятилетия
Недавно мы утверждали, что AGI может появиться к 2030 году. И мы не единственные — руководители ведущих ИИ-лабораторий и многие исследователи ИИ говорят нечто подобное. Но многие с этим не согласны, и есть вероятность, что AGI не появится к 2030 году. Некоторые считают, что это может быть ещё через десятилетия. Так почему стоит ожидать более долгого пути к AGI?
Причина 1: Путь к AGI неочевиден
Современные системы ИИ могут писать отличный код, создавать исследовательские отчёты и выполнять работу, достойную Нобелевской премии, в области свёртывания белков.
Но передовые системы всё ещё не могут:
- Самостоятельно выполнять сложные задачи в течение часов, дней или недель.
- Взаимодействовать с физическим миром сложными и адаптивными способами.
- Постоянно учиться на прошлых взаимодействиях, чтобы улучшать результативность со временем.
Другими словами, у нас пока нет AGI — систем ИИ с общей интеллектуальностью, которые могли бы надёжно заменить людей в широком спектре задач.
В 2024 году Сэм Альтман из OpenAI заявил: «Мы теперь уверены, что знаем, как построить AGI». Но как мы этого достигнем?
Некоторые считают, что AGI можно создать, масштабируя существующие модели. Однако другие утверждают, что масштабирование значительно улучшило результативность ИИ только в таких областях, как разработка программного обеспечения, где задачи чётко определены и часто быстро проверяемы. Это не особо помогло системам ИИ справляться с реальным миром, где всё гораздо сложнее.
Возможно, именно навыки работы в реальном мире сделают разницу между ИИ, способными действительно трансформировать общество, и теми, которые являются просто полезными инструментами. Подумайте о разнице между постановкой точного медицинского диагноза — что уже могут современные системы ИИ — и проактивным ведением пациента через шесть месяцев лечения, реагируя на его меняющиеся потребности.
Что это значит, если масштабирования недостаточно для достижения AGI?
Некоторые исследователи, такие как Франсуа Шолле, утверждают, что текущая парадигма ИИ имеет фундаментальные недостатки, и нам нужны новые идеи. А их открытие может занять время.
Причина 2: Мы можем столкнуться с серьёзными ограничениями или убывающей отдачей в ближайшее время
Темпы прогресса ИИ в последние годы были стремительными. Это стало возможным благодаря увеличению вычислительных ресурсов, постоянным улучшениям эффективности и миллиардам долларов инвестиций.
Однако этот темп может не сохраниться навсегда. Мы можем столкнуться с ограничениями:
- Инвестиции, необходимые для создания более крупных систем ИИ, могут иссякнуть.
- Производство ИИ-чипов может не успевать за спросом.
- Может закончиться высококачественный набор данных, необходимый для обучения моделей.
- Алгоритмические улучшения могут давать убывающую отдачу, поскольку мы уже собрали «низко висящие фрукты».
Мы уже утверждали в другом месте, что эти ограничения, вероятно, проявятся к 2030 году, а возможно, и раньше — и если к этому моменту мы ещё не достигнем AGI, прогресс может значительно замедлиться.
Эти потенциальные ограничения также ставят под сомнение идею, что автоматизация исследований ИИ быстро приведёт к разработке AGI — даже с автоматизацией могут быть пределы того, как быстро прогресс может идти в реальности.
Другие крупные мировые события также могут затормозить прогресс, например, глобальная рецессия, ещё одна пандемия или война великих держав. Эти события могут привести к более раннему возникновению ограничений.
Причина 3: Мир, похоже, ещё не верит в это
Если бы AGI был за углом, разве мы не видели бы более явных признаков? Рынки, похоже, не учитывают в ценах масштабное краткосрочное потрясение экономики. Правительства не спешат перестраивать институты, чтобы справиться с фундаментально новым миром. И хотя политики начинают действовать, это не с той срочностью или масштабом, которые можно было бы ожидать, если бы они действительно верили, что технология, определяющая цивилизацию, уже близко.
Даже в сообществе ИИ идея AGI к 2030 году вызывает споры. Некоторые эксперты бьют тревогу, но другие считают, что мы находимся в десятилетиях от очень продвинутых систем ИИ.
Это не доказывает, что AGI не появится очень скоро. Но если ваша модель будущего не синхронизирована с тем, что делает большая часть мира — включая рынки, политиков и даже некоторых экспертов в этой области, — стоит задаться вопросом, почему.
Итак, к чему это нас приводит?
Несмотря на всё это, мы всё ещё считаем, что AGI может появиться очень скоро. И мы думаем, что эту идею стоит воспринимать очень серьёзно, даже если вы считаете более медленный прогресс более вероятным.
Важно, что многие люди, которые отвергают идею, что мы на пороге AGI, всё ещё считают, что это может быть всего через пару десятилетий или меньше. Например:
- Ян Лекун из Meta говорит, что ИИ на человеческом уровне «займёт несколько лет, если не десятилетие».
- Когнитивный учёный Гэри Маркус говорит, что AGI может «появиться через 10 или 20 лет».
- Франсуа Шолле (ранее работавший в Google) говорит, что AGI «вероятно появится в следующие 10–15 лет».
- Исследователи ИИ Эге Эрдиль и Тамай Бесироглу недавно обосновали, что AGI может быть через 20–30 лет.
Gadgets News: К этому можно добавить мнение Эндрю Ына, высказанное им еще в прошлом году (соответствующий фрагмент интервью был опубликован 1 сентября 2024), что до появления AGI «еще много десятилетий, а может и больше».
Раньше мы спорили, возможно ли вообще достичь AGI в этом веке. Теперь дебаты идут о том, через несколько лет это произойдёт или через 30 лет.
Как отметила Хелен Тонер, «даже скептический взгляд подразумевает, что нас ждёт невероятное десятилетие или два».
И даже если AGI появится через несколько десятилетий, нам уже сейчас нужны люди, работающие над тем, чтобы направить человечество подальше от катастрофических рисков ИИ. Решение этих проблем может потребовать много работы — а ставки чрезвычайно высоки.
«Мягкая сингулярность», Сэм Олтмен
Мы пересекли горизонт событий; взлёт начался. Человечество близко к созданию цифрового сверхразума, и пока это гораздо менее странно, чем кажется на первый взгляд.
Роботы ещё не ходят по улицам, и большинство из нас не общается с ИИ весь день. Люди всё ещё умирают от болезней, мы всё ещё не можем легко отправиться в космос, и многое во Вселенной остаётся для нас загадкой.
И всё же мы недавно создали системы, которые во многом умнее людей и способны значительно увеличивать продуктивность тех, кто их использует. Самая сложная часть работы позади; научные открытия, которые привели нас к системам вроде GPT-4 и o3, были трудными, но они приведут нас далеко.
ИИ внесёт вклад в мир множеством способов, но улучшение качества жизни за счёт ускорения научного прогресса и повышения продуктивности будет огромным; будущее может быть значительно лучше настоящего. Научный прогресс — главный двигатель общего прогресса; захватывающе думать о том, сколько ещё мы можем достичь.
В каком-то важном смысле ChatGPT уже мощнее любого человека, когда-либо жившего. Сотни миллионов людей полагаются на него каждый день для всё более важных задач; небольшая новая возможность может создать огромный положительный эффект, а небольшое несоответствие, умноженное на сотни миллионов людей, может вызвать значительный негативный эффект.
2025 год принёс появление агентов, способных выполнять настоящую когнитивную работу; написание компьютерного кода уже никогда не будет прежним. В 2026 году, вероятно, появятся системы, способные находить новые идеи. В 2027 году могут появиться роботы, выполняющие задачи в реальном мире.
Гораздо больше людей смогут создавать программное обеспечение и искусство. Но миру нужно больше и того, и другого, и эксперты, вероятно, всё ещё будут значительно лучше новичков, если они примут новые инструменты. В целом, способность одного человека сделать гораздо больше в 2030 году, чем в 2020, будет поразительным изменением, и многие люди найдут способы извлечь из этого пользу.
В самых важных аспектах 2030-е годы могут не сильно отличаться. Люди всё ещё будут любить свои семьи, выражать свою креативность, играть в игры и плавать в озёрах.
Но в очень важных аспектах 2030-е годы, вероятно, будут кардинально отличаться от любого предыдущего времени. Мы не знаем, насколько далеко за пределы человеческого интеллекта мы сможем зайти, но скоро это выясним.
В 2030-х годах интеллект и энергия — идеи и способность воплощать их в жизнь — станут невероятно доступными. Эти два фактора долгое время были основными ограничителями человеческого прогресса; с избытком интеллекта и энергии (и хорошим управлением) мы теоретически сможем получить всё остальное.
Мы уже живём с невероятным цифровым интеллектом, и после первоначального шока большинство из нас к этому привыкло. Очень быстро мы переходим от удивления, что ИИ может создать красиво написанный абзац, к вопросу, когда он сможет написать красиво написанный роман; или от удивления, что он может поставить спасительный медицинский диагноз, к вопросу, когда он сможет разработать лекарства; или от удивления, что он может создать небольшую компьютерную программу, к вопросу, когда он сможет создать целую новую компанию. Так происходит сингулярность: чудеса становятся рутиной, а затем минимальным стандартом.
Учёные уже говорят, что они в два или три раза продуктивнее, чем были до появления ИИ. Продвинутый ИИ интересен по многим причинам, но, возможно, ничто не так значимо, как то, что мы можем использовать его для ускорения исследований в области ИИ. Мы можем открыть новые вычислительные платформы, лучшие алгоритмы и кто знает, что ещё. Если мы сможем провести десятилетие исследований за год или месяц, то темпы прогресса будут совершенно иными.
Отныне инструменты, которые мы уже создали, помогут нам находить новые научные открытия и создавать лучшие системы ИИ. Конечно, это не то же самое, что ИИ, полностью автономно обновляющий свой код, но это зародышевая версия рекурсивного самоулучшения.
Есть и другие самоусиливающиеся циклы. Создание экономической ценности запустило маховик наращивания инфраструктуры для работы всё более мощных систем ИИ. А роботы, которые могут создавать других роботов (и в каком-то смысле дата-центры, которые могут строить другие дата-центры), уже не так далеки.
Если нам придётся создавать первый миллион гуманоидных роботов старым способом, но затем они смогут управлять всей цепочкой поставок — добывать и очищать минералы, водить грузовики, управлять заводами и т.д. — чтобы строить ещё больше роботов, которые смогут строить больше фабрик по производству чипов, дата-центров и т.д., то темпы прогресса будут совершенно иными.
По мере автоматизации производства дата-центров стоимость интеллекта в конечном итоге должна приблизиться к стоимости электроэнергии. (Людей часто интересует, сколько энергии потребляет запрос в ChatGPT; средний запрос использует около 0,34 ватт-часа, примерно столько, сколько духовка использует чуть больше чем за секунду, или высокоэффективная лампочка — за пару минут. Также он потребляет около 0,000085 галлона воды; примерно одну пятнадцатую чайной ложки.)
Темпы технологического прогресса будут продолжать ускоряться, и люди, как всегда, будут способны адаптироваться почти к чему угодно. Будут сложные моменты, например, исчезновение целых категорий профессий, но, с другой стороны, мир будет богатеть так быстро, что мы сможем серьёзно рассматривать новые политические идеи, которые раньше были невозможны. Мы, вероятно, не примем новый общественный договор сразу, но, оглядываясь назад через несколько десятилетий, постепенные изменения сложатся в нечто значительное.
Если судить по истории, мы найдём новые дела и новые желания, и быстро освоим новые инструменты (смена профессий после промышленной революции — хороший недавний пример). Ожидания вырастут, но возможности будут расти так же быстро, и у нас будет всё лучше. Мы будем создавать всё более удивительные вещи друг для друга. У людей есть важное и любопытное долгосрочное преимущество перед ИИ: мы запрограммированы заботиться о других людях, о том, что они думают и делают, и нам не так уж важны машины.
Ведущий натуральное хозяйство крестьянин тысячу лет назад посмотрел бы на то, что многие из нас делают, и сказал бы, что у нас ненастоящая работа — он подумал бы, что мы просто играем в игры, чтобы развлекать себя, раз у нас полно еды и невообразимой роскоши. Я надеюсь, что мы сегодня взглянем на будущую, спустя тысячу лет, работу, и подумаем, что она ненастоящая, и я не сомневаюсь, что она будет казаться невероятно важной и доставляющей удовольствие для тех, кто её будет делать.
Темпы появления новых чудес будут огромными. Трудно даже представить сегодня, что мы откроем к 2035 году; возможно, мы перейдём от решения задач высокоэнергетической физики в один год к началу колонизации космоса в следующем; или от крупного прорыва в материаловедении в один год к настоящим высокоскоростным интерфейсам мозг-компьютер в следующем. Многие люди выберут жить примерно так же, но некоторые, вероятно, решат «подключиться».
Глядя вперёд, это звучит сложно для осмысления. Но, вероятно, проживание этого будет впечатляющим, но управляемым. С релятивистской точки зрения, сингулярность происходит постепенно, и слияние происходит медленно. Мы взбираемся по длинной дуге экспоненциального технологического прогресса; она всегда кажется вертикальной, глядя вперёд, и плоской, оглядываясь назад, но это одна плавная кривая. (Вспомните 2020 год и как бы это звучало, если бы вам сказали, что к 2025 году мы будем близки к AGI, по сравнению с тем, как прошли последние пять лет.)
Есть серьёзные вызовы, с которыми нужно справиться, наряду с огромными преимуществами. Нам нужно решить проблемы безопасности, как технические, так и общественные, но затем критически важно широко распространить доступ к сверхразуму, учитывая экономические последствия. Лучший путь вперёд может быть таким:
- Решить проблему контроля ИИ, то есть гарантировать, что мы можем надёжно заставить системы ИИ учиться и действовать в соответствии с тем, чего мы коллективно действительно хотим в долгосрочной перспективе (ленты социальных сетей — пример несогласованного ИИ; алгоритмы, которые ими управляют, невероятно эффективны в том, чтобы заставить вас продолжать прокручивать, и явно понимают ваши краткосрочные предпочтения, но делают это, эксплуатируя что-то в вашем мозге, что перечёркивает ваши долгосрочные предпочтения).
- Затем сосредоточиться на том, чтобы сделать сверхразум дешёвым, широко доступным и не слишком сконцентрированным у одного человека, компании или страны. Общество устойчиво, креативно и быстро адаптируется. Если мы сможем использовать коллективную волю и мудрость людей, то, хотя мы совершим множество ошибок и некоторые вещи пойдут совсем не так, мы быстро научимся и адаптируемся, и сможем использовать эту технологию для получения максимальной выгоды и минимального вреда. Предоставление пользователям большой свободы в широких рамках, которые должно определить общество, кажется очень важным. Чем раньше мир начнёт обсуждение того, какими должны быть эти широкие рамки и как мы определяем коллективное выравнивание, тем лучше.
Мы (вся индустрия, не только OpenAI) создаём мозг для мира. Он будет чрезвычайно персонализированным и простым в использовании для всех; нас будут ограничивать только хорошие идеи. Долгое время технические люди в стартап-индустрии высмеивали «людей с идеями»; тех, у кого была идея и кто искал команду для её реализации. Теперь кажется, что их день на солнце близок.
OpenAI сейчас многое собой представляет, но прежде всего мы — компания, исследующая сверхразум. У нас впереди много работы, но большая часть пути теперь освещена, и тёмные участки быстро отступают. Мы чрезвычайно благодарны за возможность делать то, что мы делаем.
Интеллект, слишком дешёвый, чтобы его измерять, уже в пределах досягаемости. Это может звучать безумно, но если бы мы сказали вам в 2020 году, что мы окажемся там, где мы сегодня, это, вероятно, звучало бы ещё безумнее, чем наши текущие прогнозы о 2030 годе.
Пусть мы плавно, экспоненциально и без происшествий продвинемся к сверхразуму.
Что касается модели o3 Pro, которая вероятно и вдохновила главу OpenAI на это эссе — вот какими впечатлениями поделились одни из первых пользователей этой модели:
Мой соучредитель Алексис и я потратили время на то, чтобы собрать историю всех наших прошлых плановых совещаний в Raindrop, всех наших целей, даже записать голосовые заметки: а затем попросили o3 Pro разработать план.
Мы были потрясены: он выдал именно тот конкретный план и анализ, который я всегда хотел, чтобы создал LLM — с целевыми показателями, сроками, приоритетами и строгими инструкциями о том, что нужно обязательно исключить.
План, который нам предоставил o3, был правдоподобным и разумным, но план, который нам предоставил o3 Pro, был настолько конкретным и обоснованным, что фактически изменил наше представление о будущем.