Birentech раскрыла новые подробности о ГПУ Biren BR100

Пару недель назад китайская компания Birentech анонсировала графический ускоритель Biren BR100, а сегодня в рамках конференции Hot Chips 34 раскрыла о нем новые подробности. Вот как на сегодня выглядят полные характеристики одного из самых производительных в мире ГПУ — в таблице снизу они приводятся вместе с Nvidia H100:
| Biren BR100 (Birentech) | H100 (Nvidia) | |
| Техпроцесс | 7 нм TSMC | 4 нм TSMC |
| Площадь кристалла | 1074 мм2 (два чиплета) | 814 мм2 |
| Кол-во транзисторов | 77 млрд | 80 млрд |
| Кэш L2 | 256 Мб | 50 Мб |
| Кэш L1 | 8 Мб | 33 Мб |
| Память | 64 Гб HBM2E (1.64 Тб/с) | 80 Гб HBM3 (3 Тб/с) |
| Производительность | FP32: 256 TFLOPS BF16: 1014 TFLOPS INT8: 2048 TOPS | FP32: 60 (500) TFLOPS BF16: 120 (1000) TFLOPS INT8: 2000 TOPS |
| TDP | 550 Вт | 700 Вт |
| Интерфейс с другими графическими ускорителями (пропускная способность) | BLink (512 Гб/с) | NVLink 4 (450 Гб/с) |

По всей видимости, заявленное для Biren BR100 быстродействие относится к тензорным вычислениям, поэтому для Nvidia H100 в скобках приведены аналогичные данные. Сама Birentech сравнивает свой графический ускоритель не с H100 (анонсирован в марте 2022), а с его предшественником A100 (май 2020):
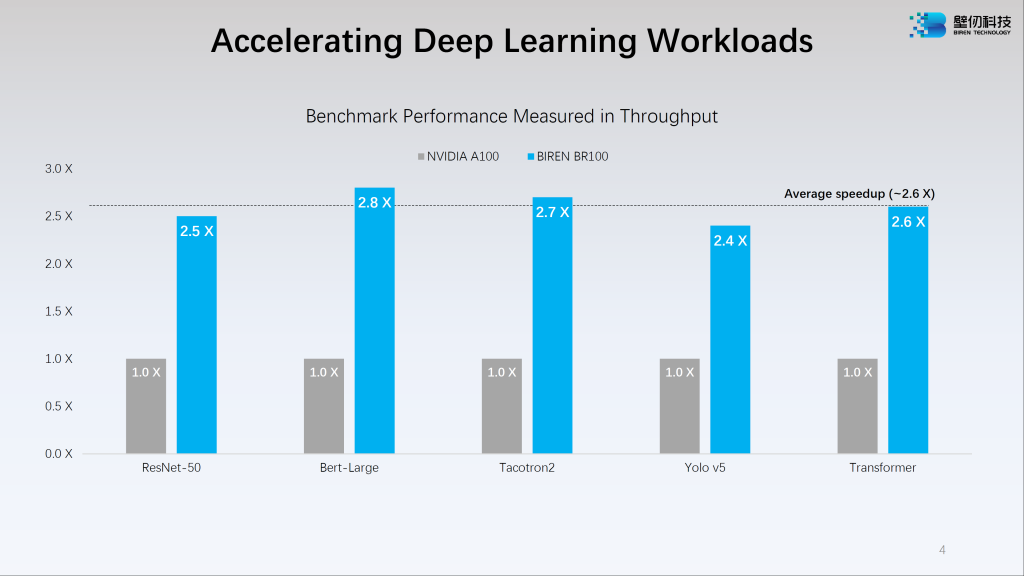
Таким образом, превосходство Biren BR100 над Nvidia A100 является 2.4-2.8-кратным. Что касается H100, то согласно Nvidia разница в его производительности с предшественником, A100, в некоторых задачах (например, инференс, т.е. вывод данных из модели) является 30-кратной. Но даже создание достойного соперника для топового графического ускорителя 2-летней давности является для Китая большим достижением. Тем более, что сравнение с устаревшей Nvidia A100 на вышеупомянутой конференции Hot Chips 34 предпочла сделать даже Intel — при том, что её графический ускоритель Ponte Vecchio Xe-HPC (52 TFLOPS FP32, L1 — 64 Мб, L2 — 408 Мб) еще не поступил в продажу.
