Google TPU v4, Habana Gaudi2 и Tachyum Prodigy T16128: новейшие процессоры для искусственного интеллекта [обновлено]

В рамках прошедшей на днях Google I/O (на которой были анонсированы Pixel 6a и другие новинки), компания представила свой новый тензорный процессор для облачных расчетов в области искусственного интеллекта, TPU v4. Это довольно запоздавшее обновление — предыдущие выходили в 2018, 2017 и 2016. Вот как изменились характеристики новинки по сравнению с предшественником:
| TPU v4 | TPU v3 | |
| Релиз | 2022 | 2018 |
| Техпроцесс | 7 нм | 16 нм |
| Пиковая производительность (bf16 или int8) | 275 TFLOPS | 123 TFLOPS |
| Объем и пропускная способность HBM2 | 32 Гб 1200 Гб/с | 16 Гб 1 900 Гб/с |
| Энергопотребление (мин, среднее, макс) | 90/170/192 Вт | 123/220/262 Вт |
| Кол-во процессоров в вычислительном кластере | 4096 | 1024 |
| Пиковая производительность кластера (bf16 или int8) | 1.1 EFLOPS | 126 PFLOPS |
| Топология | 3D | 2D |
| Минимальная пропускная способность между частями сети | 24 Тб/с | 6.4 Тб/с |
1 согласно тексту пресс-релиза (в таблице — 32 Гб)
Для сравнения, производительность TPU v2 (2017, 16 нм) достигает 45 TFLOPS (180 TFLOPS у платы с четырьмя чипами). Таким образом, за четыре года быстродействие тензорных процессоров Google увеличилось в 6 раз. По сравнению с TPU v3 пиковая энергоэффективность (производительность на ватт) TPU v4 выросла втрое.

Google не только использует тензорные кластеры для собственных нужд, но и предоставляет их в пользование — для облачных вычислений в области крупномасштабной обработка естественного языка, рекомендательных систем и компьютерного зрения. Компания заявляет, что общая производительность её дата-центра в Оклахоме достигает 9 EFLOPS (экзафлопс), что делает его крупнейшим в мире среди общедоступных. При этом хаб на 90% питается чистой (безуглеродной) энергией. Для сравнения, пиковая производительность самого быстрого в мире суперкомпьютера, Фугаку (Япония), составляет 0.5 экзафлопс. Впрочем, сравнивать их между собой напрямую некорректно: у дата-центра Google 9 экзафлопс получено в Bfloat16 (причем, возможно, на разреженных, т.е. с преимущественно нулевыми элементами, матрицах), а у Фугаку — float64 (FP64). На примере Nvidia H100 (SXM5) разница между BF16 на разреженных матрицах (2000 TFLOPS) и FP64 (30 TFLOPS) может быть 76-кратной. Что касается непосредственного сравнения самих процессоров, то по тензорной производительности расклад такой (для H100 данные приводятся по обычным и разреженным матрицам):
| Google TPU v4 | Nvidia H100 (SXM5) | |
| Техпроцесс | 7 нм | 4 нм |
| Энергопотребление | 170 Вт | 700 Вт |
| bf16 | 275 TFLOPS | 1000 TFLOPS 2000 TFLOPS |
Максимальная цена облачного доступа к одному процессору TPU v4 составляет $3.22 в час (к TPU v3 — $2.00).

Почти одновременно с Google I/O состоялось мероприятие другого IT-гиганта, Intel Vision. На нем были представлены два процессора израильской компании Habana Labs, которую Intel приобрела в декабре 2019 за $2 млрд. Это 2-е поколение ускорителя Gaudi, предназначенного для тренировки глубоких ИНС, и ускоритель Greco — для инференса (вывода данных из модели). Оба созданы на базе 7-нм техпроцесса TSMC. Intel предпочла сравнить производительность не с Nvidia H100, а его предшественником:
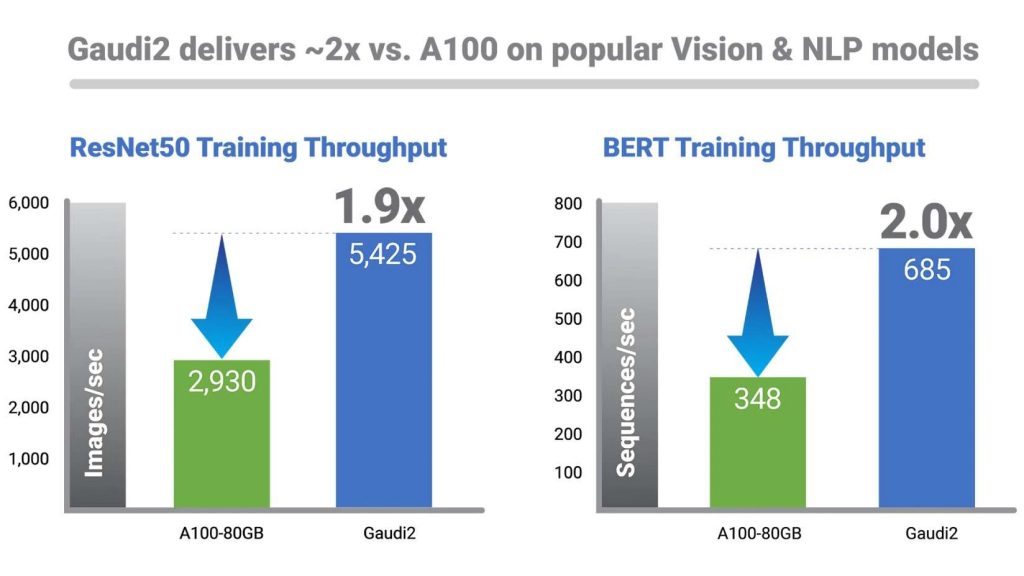
Третьим интересным анонсом в области ИИ-вычислений стали три процессора словацкой компании Tachyum: 32-ядерный Prodigy T832, 64-ядерный Prodigy T864 и 128-ядерный Prodigy T16128. Все они созданы на базе 5-нм техроцесса, тактовая частота ядер достигает 5 ГГц. Заявленная производительность самой старшей модели, Prodigy T16128 — 90 TFLOPS FP64 и 12 PFLOPS FP8, что в 3 и 6 раз больше, чем у Nvidia H100. Процессоры Prodigy поддерживают вычисления в формате данных FP64, FP32, TF32, BF16, Int8, FP8 и TAI. Компания называет свое детище первыми в мире универсальными процессорами — они объединяют в себе функциональность ЦПУ, ГПУ и ТПУ. Обновление от 04.10.2022: вышла документация (Whitepaper) по архитектуре Tachyum Prodigy.
По оценкам консалтинговой компании PriceWaterhouseCoopers, сделанным в начале года, вклад технологий искусственного интеллекта в мировой ВВП в 2030 составит $15.7 трлн, из которых $6.6 трлн — за счет выросшей производительности труда, а $9.1 трлн — потребительского спроса (благодаря возросшему качеству и персонификации услуг, появлению дополнительного времени). Согласно PWC, основной вклад в этот рост мирового ВВП внесут Китай ($7 трлн), Северная Америка ($3.7 трлн) и Северная Европа ($1.8 трлн). Социальным последствиям революции, которую обещают произвести технологии искусственного интеллекта, посвящена наша публикация Станет ли Искусственный Интеллект Большим Братом?