OpenAI: искусственный сверхразум может появиться уже в этом десятилетии [обновлено]

Полсотни лет назад в Массачусетсе запустили самое сложное кибернетическое устройство, когда-либо существовавшее. С каким-то там феноменальным быстродействием, необозримой памятью и всё такое… И проработала эта машина ровно четыре минуты. Её выключили, зацементировали все входы и выходы, отвели от неё энергию, заминировали и обнесли колючей проволокой.
«Далёкая радуга», братья Стругацкие, 1963
Разработавшая нашумевший ChatGPT компания OpenAI объявила на днях о создании команды, которая будет работать над т.н. superalignment. Сам по себе термин alignment применительно к искусственному интеллекту означает его следование человеческим намерениям (т.е. намерениям того, кто обучает ИИ и поручает ему определенные задания). В случае с superalignment речь идет даже не об AGI (сильном, т.е. человекоподобном, ИИ), а об искусственном сверхразуме. Под последним в данном случае понимается «гораздо более мощная система».
Новой команде выделена пятая часть вычислительных ресурсов компании, а возглавят команду со-учредитель и главный специалист OpenAI Илья Суцкевер (Ilya Sutskever) и Ян Лейке (Jan Leike). Последний работает в OpenAI над большими языковыми моделями с 2021 года, а до этого, в 2016-2020, в DeepMind занимался эмпирическими исследованиями, связанными с обучением функций вознаграждения для глубокого обучения с подкреплением. Его диссертация была посвящена общему обучению с подкреплением в средах, которые являются немарковскими, неэргодическими (нестационарными) и наблюдаемыми лишь частично. OpenAI приглашает в новую команду «лучшие умы мира» на вакансии инженера-исследователя, научного сотрудника и менеджера по исследованиям.
Но пожалуй самым интересным в этом объявлении стала следующая ремарка:
В то время как [искусственный] сверхразум кажется далеким сейчас, мы считаем, что это может произойти в этом десятилетии».
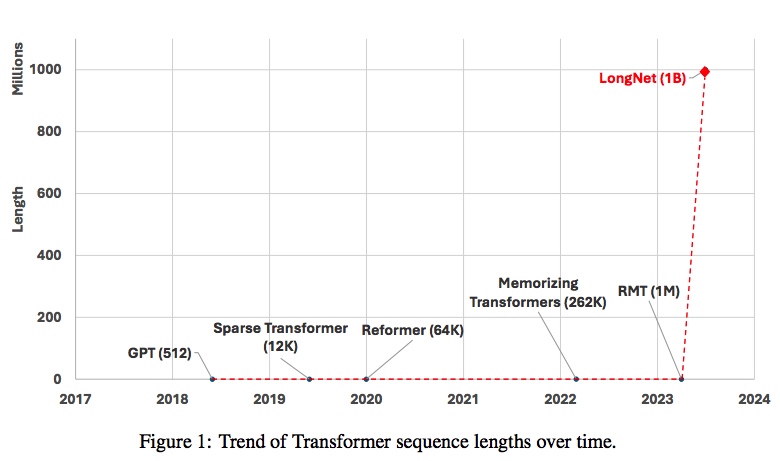
По случайному(?) стечению обстоятельств в тот же день была опубликована научная работа сотрудников Microsoft c анонсом трансформерной модели нового типа:
Наше решение — это LongNet, который заменяет внимание традиционных трансформеров новым компонентом под названием рассеянное внимание. Общий принцип разработки заключается в том, что распределение внимания уменьшается экспоненциально по мере того, как увеличивается расстояние между токенами. Мы доказываем, что это дает линейную вычислительную сложность и логарифмическую зависимость между токенами. Это разрешает противоречие между ограниченными ресурсами внимания и доступностью каждого токена. LongNet может быть преобразован в плотный трансформер, который легко поддерживает готовые оптимизации для трансформеров (например, слияние ядер, квантование и распределенное обучение). Пользуясь преимуществом линейной сложности, LongNet с помощью распределенного алгоритма может распараллелить обучение по узлам, преодолевая ограничения как производительности, так и памяти . Это позволяет эффективно увеличивать длину последовательности до 1 млрд токенов с почти постоянным временем работы, в то время как классический трансформер страдает от квадратичной сложности.
Анонс LongNet стал своего рода мини-сенсацией — размер контекстного окна в нем увеличивается с нынешних 32 тыс токенов (или пусть даже 1 млн токенов, недавно обещанных OpenAI в недалеком будущем) до 1 млрд токенов.
Но на самом деле все не так радужно, как выглядит в заголовке. Во-первых, даже с линейной зависимостью требования к производительности вырастут весьма значительно — увеличение контекста с 32 тыс токенов до заявленных Microsoft 1 млрд токенов потребует прироста производительности более чем в 30 тыс раз. В обозримом будущем это совершенно исключено — даже 32 тыс токенов контекстного окна большинству пользователей ChatGPT недоступно, и как раз по причине нехватки вычислительных ресурсов серверов, на которых работает этот чат-бот.
Во-вторых, если вы заметили, LongNet оперирует т.н. рассеянным вниманием (dilated attention). В отличие от глобального внимания (global attention), где обрабатывается каждый токен контекста (грубо говоря, каждое слово вопроса, который вы задаете чат-боту), рассеянное внимание отбирает только те токены, которые сочтет (посредством специального алгоритма) важными. При этом внимание «уменьшается экспоненциально по мере того, как увеличивается расстояние между токенами». Возможно это допустимо в переписке с искусственным оператором вашего банка, но едва ли правильно, когда вы просите чат-бот ответить на вопросы по существу многотомного учебника, который дали ему прочесть в своем запросе. Но нельзя исключать и того, что посредством различных ухищрений (разреженного внимания, дробления большого контекста на фрагменты, и т.д.) разработчики больших языковых моделей научатся эффективно обрабатывать огромные контексты. Что, по мнению некоторых специалистов — прямая дорога к AGI, сильному искусственному интеллекту.
Отдельного внимания заслуживает вопрос о производительности, требуемой большим языковым моделям для обработки контекста. В лучшем случае она растет линейно, в худшем — квадратично. При линейной зависимости переход от контекста размером в 32 тыс токенов до 32 млн токенов потребует повышения производительности в 1 тыс раз. Как уже рассказывал Gadgets News, по расчетам SemiAnalysis обработка всех пользовательских запросов чат-бота, интегрированного в Google, потребует больше 4 млн графических ускорителей Nvidia A100 (2020) и соответственно больше $100 млрд инвестиций в серверную инфраструктуру. Очевидно, что при тысячекратном увеличении контекста масштабы требуемых инвестиций совершенно нереальны, не говоря уже об увеличении контекста в миллион раз. Другой вопрос, что производительность компьютеров не стоит на месте. Например, в конце 2021 года AMD выпустила ускоритель Instinct MI250x с производительностью 48 TFLOPS FP64 — больше, чем самый быстрый в мире суперкомпьютер 2003 года (41 TFLOPS). Менее чем за двадцать лет такое быстродействие было достигнуто при сокращении энергопотребления с 3.2 МВт до 560 Вт, т.е. в 5.7 тыс раз. А если сравнивать с нынешним лидером рейтинга суперкомпьютеров, то его пиковая производительность достигает 1.68 EFLOPS — т.е. выросла в 41 тыс раз. Если такая динамика сохранится, и при этом LongNet и его аналоги хорошо себя зарекомендуют, то еще через двадцать лет большие языковые модели смогут обрабатывать контекст в тысячу, а то и в десять тысяч раз большего размера — не 32 тыс, а 32 млн или даже 320 млн токенов. Причем в OpenAI настроены еще более оптимистично и безотносительно размеров контекста допускают появление искусственного суперинтеллекта уже к 2030 году.
Что касается научного сообщества в целом, то мнения специалистов расходятся. В прошлом месяце IEEE Spectrum провел опрос ряда известных ученых и специалистов, в котором были следующие вопросы: «Является ли успех GPT-4 и других сегодняшних больших языковых моделей признаком того, что AGI вероятен?» и «Может ли AGI вызвать цивилизационную катастрофу, если мы ничего не предпримем?» Вот как распределились ответы:
| Вопрос 1 | Вопрос 2 | ||
| Сэм Олтмен (Sam Altman) | OpenAI, CEO | да | возможно |
| Якоб Андреса (Jacob Andreas) | Массачусетский технологический институт, профессор | нет | нет |
| Эмили М. Бендер (Emily M. Bender) | Вашингтонский университет, профессор, лингвист | нет | нет |
| Йошуа Бенжио (Yoshua Bengio) | Монреальский университет, профессор, математик | возможно | возможно |
| Ник Бостром (Nick Bostrom) | Оксфордский университет, философ | да | да |
| Родни Брукс (Rodney Brooks) | Массачусетский технологический институт, профессор, робототехник, со-основатель и CTO Robust AI | нет | нет |
| Себастьян Бубек (Sébastien Bubeck) | Старший менеджер по исследованиям в группе «Основы машинного обучения» в Microsoft Research | да | возможно |
| Джой Буоламвини (Joy Buolamwini) | Алгоритмическая лига справедливости, со-основатель | нет | нет |
| Тимнит Гебру (Timnit Gebru) | Основатель Distributed AI Research Institute, ученый-компьютерщик | нет | нет |
| Элисон Гопник (Alison Gopnik) | Калифорнийский университет в Беркли, профессор, философ и психолог | нет | нет |
| Дэн Хендрикс (Dan Hendrycks) | Директор и со-основатель Центра безопасности ИИ | да | да |
| Джеффри Хинтон (Geoffrey Hinton) | крупный ученый в области ИИ, учитель Яна Лекуна и Ильи Суцкевера | да | возможно |
| Кристоф Кох (Christof Koch) | нейробиолог, директор Института Аллена по изучению мозга, один из самых известных в мире исследователей сознания | да | возможно |
| Джарон Ланье (Jaron Lanier) | учёный в области визуализации данных и биометрических технологий, автор термина «виртуальная реальность | нет | нет |
| Ян Лекун (Yann LeCun) | крупный ученый в области ИИ, ведущий исследователь Meta (Facebook) | нет | нет |
| Гэри Маркус (Gary Marcus) | Нью-Йоркский университет, профессор, психология | нет | возможно |
| Маргарет Митчелл (Margaret Mitchell) | специалист по ИИ и этике ИИ | нет | нет |
| Мелани Митчелл (Melanie Mitchell) | Институт Санта-Фе, профессор, её публикации в области рассуждений по аналогии, сложных систем, генетических алгоритмов и клеточных автоматов часто цитируются | нет | нет |
| Эндрю Ын (Andrew Ng) | исследователь робототехники, машинного обучения и искусственного интеллекта | нет | нет |
| Макс Тегмарк (Max Tegmark) | Массачусетский технологический институт, профессор, космолог | да | да |
| Мередит Уиттакер (Meredith Whittaker) | президент Signal Foundation, была соучредителем и директором AI Now Institute при Нью-Йоркском университете | нет | нет |
| Элиезер Юдковский (Eliezer Yudkowsky) | исследователь в области ИИ, со-основатель Machine Intelligence Research Institute, целью которой является создание безопасного ИИ | да | да |
Итак, из 22 опрошенных 8 специалистов утвердительно ответили на вопрос «Является ли успех GPT-4 и других сегодняшних больших языковых моделей признаком того, что AGI вероятен?», один допустил такую вероятность, и 13 ответили отрицательно. И хотя этот вопрос сроков появления AGI напрямую не касается, с учетом нынешних достижений больших языковых моделей те, кто ответил на него положительно, скорее всего допускают скорое (в ближайшие годы, а не десятилетия) появление сильного искусственного интеллекта. Кстати, одной из ключевых проблем больших языковых моделей являются т.н. галлюцинации — когда модели, проще говоря, врут. И в этом щекотливом вопросе глава OpenAI Сэм Олтмен тоже настроен позитивно — отвечая на вопрос в ходе своего недавнего международного турне, он заявил, что по его мнению эта проблема будет решена в течение ближайших полутора-двух лет. Такого же мнения Мустафа Сулейман (соучредитель и бывший руководитель прикладного ИИ в DeepMind, ныне глава Inflection AI):
Скоро большие языковые модели будут знать, когда они не знают. Они будут знать, когда нужно сказать «Я не знаю», или вместо этого спросить другой ИИ, или спросить человека, или использовать другой инструмент, или другую базу знаний. Это будет очень важный момент.
Судя по всему, Мустафа Сулейман также рассчитывает на относительно скорое появление сильного ИИ:
Удивительно, как дискуссия по поводу ИИ прошла путь от «Это не работает, это несбыточная мечта» десять лет назад до «Здорово, но это не всегда на 100% точно, поэтому не используйте это для задач с высокими ставками»… Подождите еще пару лет.
Среди участников опроса нет такого авторитета как Демис Хассабис, возглавляющий основанную им компанию DeepMind (которая недавно была объединена с Google Brain). Но в майском интервью WSJ он высказался вполне оптимистично:
За последние несколько лет прогресс был просто невероятным. Я не вижу причин, по которым этот прогресс замедлится. Я думаю, что он может даже ускориться. Поэтому я полагаю, что мы можем находиться всего в нескольких годах, или может быть, в десятилетии [от появления человекоподобного интеллекта].
В опубликованном 10 июля интервью Демис Хассабис высказался чуть более осторожно: - Как Вы думаете, через сколько лет у нас появится AGI? - Я думаю, что существует большая неопределенность в отношении того, сколько еще прорывов потребуется для достижения AGI, больших, больших прорывов - инновационных прорывов - по сравнению с простым масштабированием существующих решений. И я думаю, что от этого во многом зависят временные рамки. Очевидно, что если требуется еще много прорывов, то сделать их гораздо сложнее и займет гораздо больше времени. Но уже сейчас я не удивлюсь, если в ближайшее десятилетие мы приблизимся к чему-то вроде AGI или AGI-подобного.
Аналогичной точки зрения придерживается Илон Маск:
2029 год кажется переломным. Я буду удивлен, если к тому времени у нас не будет AGI. Надеюсь, и люди на Марсе тоже.
Таким образом, можно констатировать, что мнения специалистов разделились примерно пополам, и с этой точки зрения существует 50% вероятность того, что AGI появится до конца этого десятилетия.