Tesla P40 vs Google TPU: кто же производительнее?

Неделю назад Nvidia опубликовала в своем блоге статью, написанную в ответ на недавно раскрытые Google подробности относительно её TPU. Напомню, что согласно компании эта интегральная схема специального назначения в 15-30 раз производительнее и в 30-80 раз энергоэффективнее связки традиционных ЦПУ и ГПУ. Сравнение было сделано c Tesla K80 (анонсирована в ноябре 2014), что вполне уместно с учетом использования TPU в дата-центрах Google начиная с 2015 года. Но также объяснимо и то, что Nvidia решила обратить внимание публики на более новую и более производительную видеокарту, Tesla P40. Сравнение делается по двум параметрам:
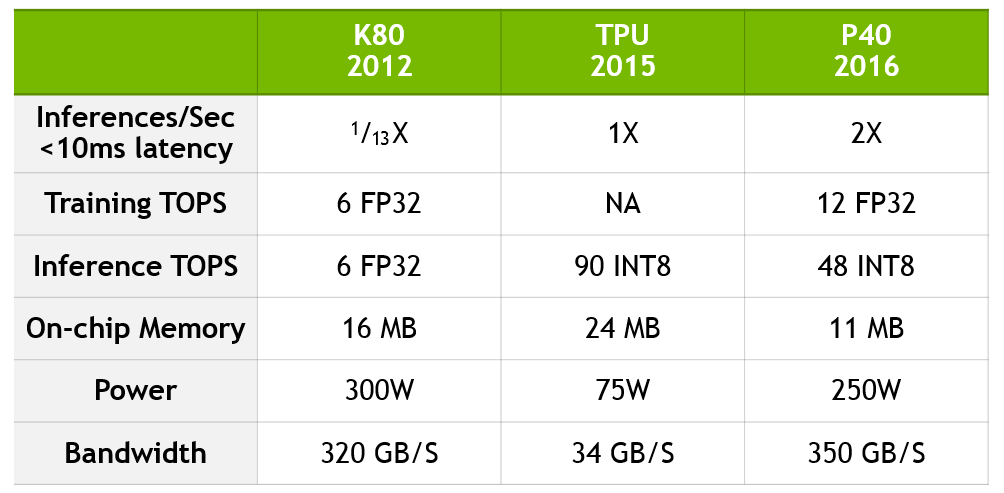
- Inferences/Sec < 10 ms latency
- Inference TOPS
По первому показателю Google TPU превосходит Tesla K80 в 13 раз, а по второму — в 15 раз. Но если сравнивать Google TPU с более производительной видеокартой, то получается довольно противоречивый результат. В Inference TOPS ускоритель Google быстрее Tesla P40 почти в два раза (90 INT8 vs 48 INT8), тогда как в Inferences/Sec < 10 ms latency он в два раза медленнее.
Дабы разрешить это противоречие, мы связались с Nvidia и попросили пояснить разницу между этими двумя бенчмарками. Согласно полученным разъяснениям, Inference TOPS характеризует пиковую производительность, которая не всегда достижима на практике из-за скромной пропускной способности памяти (34 Гб/с у TPU vs 350 Гб/с у Tesla P40) — тогда как Inferences/Sec выражает среднюю производительность и в этом отношении ближе к реальности. Но, к сожалению, безответным пока остается наш вопрос о том, почему сама Nvidia в своих спецификациях и анонсах приводит производительность только в TOPS — будь то training (тренировка) или inference (принятие решений).