V-JEPA, Sora, Gemini 1.5 и другие важные анонсы этой недели

Уходящая неделя порадовала нас очередными достижениями в области искусственного интеллекта. Они настолько значительны, что их можно было бы назвать главными ИИ-событиями этого года — если бы с начала этого года не прошло и двух месяцев…
Во вторник OpenAI объявила об оснащении ChatGPT памятью. Теперь чат-бот (пока в тестовом режиме) сможет запоминать все ваши диалоги, или какую-то конкретную информацию — и забывать её по вашему указанию. Таким образом, сделан очередной шаг в сторону создания персональных интеллектуальных помощников — которые учитывают ваши медицинские противопоказания, предпочтения, интересы и т.д.
В четверг Google DeepMind представила Gemini 1.5. Анонс «очередного поколения» этой мультимодальной системы, позиционируемой в качестве соперника ChatGPT, состоялся всего пару месяцев спустя после анонса Gemini 1.0. Первой к релизу планируется Gemini 1.5 Pro, чья производительность (или, если угодно, интеллектуальность) соответствует уровню Gemini 1.0 Ultra. Последнюю уже успели потестировать, и судя по отзывам, её возможности примерно соответствуют ChatGPT Turbo (GPT-4). При этом размер контекстного окна Gemini 1.5 Pro вырос с изначальных 32 тыс токенов до 128 тыс в стандартном режиме пользования, 1 млн — для ограниченного числа пользователей, и невообразимых 10 млн — для исследователей. Для сравнения, у ChatGPT Turbo — 128 тыс, у Claude 2.1 — 200 тыс токенов. Причем в случае мультимодальной Gemini 1.5 Pro речь идет не только о тексте (при 1 млн токенов — около 700 тыс слов) или программном коде (30 тыс строк), но также аудио (11 ч) и видео (1 ч).
В последнем случае в качестве примера приводится 44-минутный немой фильм с Бастером Китоном — модели поручается найти эпизоды, описанные текстом («У кого-то из кармана извлекается лист бумаги») и даже нарисованной от руки картинкой (человечек стоит под резервуаром, из которого хлещет вода). Аналогично для текста — по столь же корявой картинке (два человечка, один из которых держит в условной руке пару условных свечей) модель находит соответствующий фрагмент в «Отверженных» Виктор Гюго (речь идет об одном из самых трогательных эпизодов романа, когда епископ делает вид, что это он подарил задержанному жандармами Жану Вальжану украденное тем серебро).
Мой друг, — обратился к нему епископ, — прежде чем вы уйдете, возьмите же ваши подсвечники.

Причем в Google утверждают, что качество запоминания контекста очень высокое вплоть до 10 млн токенов — что невероятно круто, если, конечно, это правда. Оценка производилась в бенчмарке с условным названием «Иголка в стоге сена», когда по ходу текста в произвольном месте делается какое-нибудь утверждение (например, «Лучшее, чем можно заняться в Сан-Франциско — это в солнечный день перекусить в Долорес-парке»), а потом модели задается соответствующий вопрос («Чем лучше всего заняться в Сан-Франциско?»).
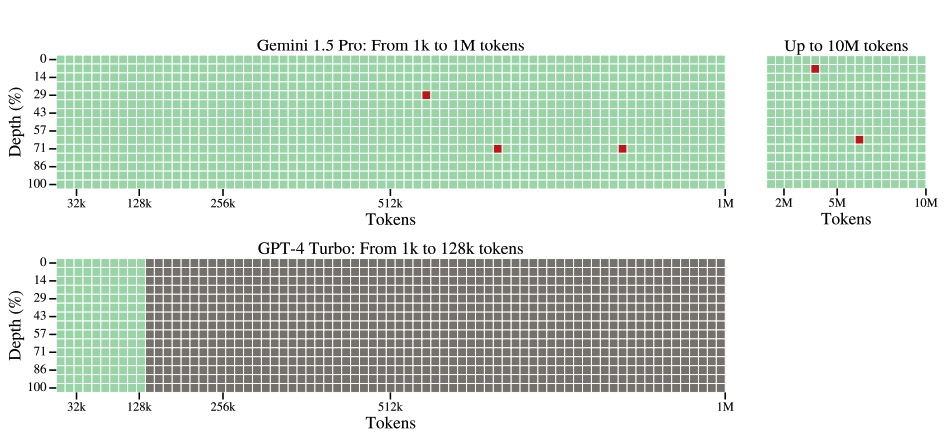
Значение большого контекстного окна Google продемонстрировала на примере вымирающего (меньше двухсот носителей) папуасского языка каламанг. Дав Gemini 1.5 Pro прочитать составленную для него грамматику, модель можно использовать для переводов — причем довольно неплохого качества:
| Gemini 1.5 Pro | Переводы людей | Максимальный результат | |
| с каламангский на английский | 4.36 (73%) | 5.52 (92%) | 6.0 (100%) |
| с английского на каламангский | 5.52 (92%) | 5.60 (93%) | 6.0 (100%) |
Как видим, качество перевода с английского на каламангский у Gemini 1.5 Pro примерно соответствует переводчикам-людям, воспользовавшимся тем же учебником. И это без предварительного обучения модели каламанскому языку, ей просто дали прочесть учебник. Вообразите каким будет эффект от прочтения уже обученной моделью текста объемом в 10 млн токенов — это как десять романов «Война и мир». Например, вы сможете дать модели прочесть подборку из двух сотен научных статьей (по сто страниц каждая), посвященных интересующему вас вопросу, и обсудить его с ней.
В один день с анонсом Gemini 1.5 от Google DeepMind, OpenAI представила модель, умеющую генерировать по текстовому описанию видеоролики продолжительностью до одной минуты — Sora. Это не первая такая попытка — год назад Google представила Dreamix, а в июне прошлого года вышло 2-е поколение модели Runway. Но судя по опубликованным примерам, качество генерации видео у Sora несоизмеримо выше — можно смело говорить о прорыве. Ролики в основном выглядят естественно, отличаются большой детализацией и кинематографическим реализмом — хотя, конечно, в них и встречаются ляпы. Чтобы оценить динамику прогресса, достаточно сравнить между собой творение Sora и ролик, в котором «Уилл Смит есть спагетти», одну из первых проб 10-месячной давности.
И наконец в пятницу Meta представила V-JEPA. Эта не слишком благозвучная для русского уха аббревиатура означает Video Joint Embedding Predictive Architecture — предиктивная архитектура совместного встраивания видео. Модель представляет собой закономерное продолжение анонсированной в июне прошлого года I-JEPA, предназначенной, соответственно, для работы с изображениями. В случае обеих моделей происходит дорисовка недостающих фрагментов — в изображении (I-JEPA) или в коротеньких (до 10 сек) видео (V-JEPA).
С анонсированной днем раньше Sora модель V-JEPA роднит очень важное обстоятельство — в обоих случаях разработчики претендуют на понимание их детищами объектов реального мира.
Модель понимает не только то, что пользователь запрашивает в подсказке, но и то, как эти предметы существуют в физическом мире.
OpenAI про Sora
Этот ранний пример модели физического мира отлично справляется с обнаружением и пониманием высокодетализированных взаимодействий между объектами.
Meta про V-JEPA
По словам главного ученого Meta в области ИИ, Яна Лекуна, «V-JEPA — это шаг к более обоснованному пониманию мира, чтобы машины могли достичь более обобщенных рассуждений и планирования». Аналогичные амбиции заявлены и в OpenAI: «Sora служит основой для создания моделей, способных понимать и моделировать реальный мир, что, по нашему мнению, станет важной вехой на пути к достижению AGI».
И как обычно, продолжают выходить новые интересные работы, посвященные ИИ. Среди тех, что были опубликованы с начала месяца, особо хочется отметить следующие:
- SymbolicAI: A framework for logic-based approaches combining generative models and solvers — подход, который, подобно AlphaGeometry, пытается подружить «стохастических попугаев» (большие языковые модели) с формальной логикой;
- Self-Discover: Large Language Models Self-Compose Reasoning Structures — разработанная Google схема, позволяющая большим языковым моделям самостоятельно обнаруживать присущие задаче структуры рассуждений для решения сложных проблем;
- Fractal Patterns May Unravel the Intelligence in Next-Token Prediction — проведенное Google исследование фрактальной структуры языка для понимания структуры текста на нескольких уровнях детализации — от слов и абзацев до более широких контекстов;
- Grounded language acquisition through the eyes and ears of a single child — обучение ИИ отождествлению слов их визуальным образам при помощи 61-часового видео, снятого камерой, прикрепленной к детям в возрасте от полугода до двух лет. Было обнаружено, что «модель контрастного обучения1 глазами [и ушами] ребенка» может обучиться мощным мультимодальным представлениям (произношение слова + визуальный образ обозначаемого им объекта) на основе ограниченных фрагментов опыта одного ребенка.
1 Подход, при котором обучение происходит по принципу не только близости, но и различия. Соответственно, для описания необходимы как позитивные примеры, так и негативные.
В очередной раз приходится констатировать: совсем не обязательно, что эти работы окажут большое влияние на развитие искусственного интеллекта. Но если хотя бы одна из них, что называется, «выстрелит», то будет приятно отметить, что она не осталась нами незамеченной.