Google DeepMind научила ИИ решать сложные геометрические задачи с привлечением формальной логики, а Meta планирует создать вычислительный кластер размером в 600 тыс Nvidia H100

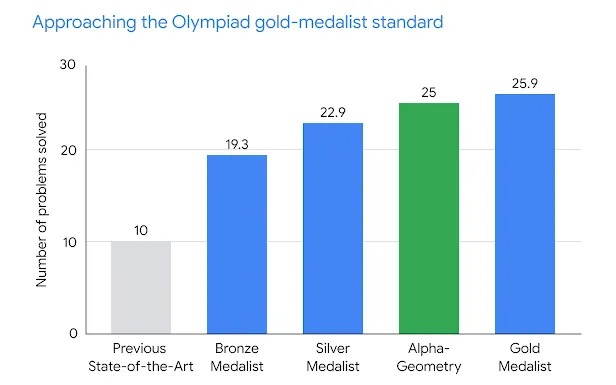
2024 едва начался, а в индустрии ИИ уже случилось событие большой важности — AlphaGeometry. Это очередное (наряду с AlphaGo, AlphaFold и другими) детище компании DeepMind, которое на этот раз, как можно догадаться из названия, умеет решать задачи по геометрии. Причем умеет весьма неплохо — в тесте из 30 задач международной олимпиады для школьников она справилась с 25 задачами, что почти соответствует уровню золотого призера этой олимпиады (26 задач) и в 2.5 раза превышает предыдущий результат ИИ на этом поприще.
Но пожалуй важнее всего в этой новости не результат, а то, каким образом он был получен. Дело в том, что AlphaGeometry сочетает 1) большую языковую модель и 2) основанный на правилах формальной логики механизм символьного вывода, работающие в тандеме для поиска решений. Первая система обеспечивает быстрые, «интуитивные» идеи, а вторая — обдуманное, рациональное принятие решений. Олимпиадные задачи по геометрии основаны на диаграммах, в которые для решения необходимо добавить новые геометрические конструкции — точки, линии или круги. Языковая модель AlphaGeometry предсказывает какие новые конструкции из бесконечного числа возможностей было бы наиболее полезно добавить. Эти подсказки помогают заполнить пробелы и позволяют системе с символьной логикой сделать дальнейшие выводы о диаграмме и приблизиться к решению. Если решение не найдено, языковая модель добавляет одну потенциально полезную конструкцию, открывая новые пути вывода для символьного механизма. Этот цикл продолжается до тех пор, пока не будет найдено решение. Например, одна из задач олимпиады 2015 года была решена таким образом за 109 шагов.
Другая интересная особенность AlphaGeometry — генерации обширного пула синтетических обучающих данных. Используя высокопараллельные вычисления, система начала с создания 1 млрд случайных диаграмм геометрических объектов и исчерпывающе определила все взаимосвязи между точками и линиями на каждой диаграмме. AlphaGeometry нашла все доказательства, содержащиеся в каждой диаграмме, а затем пошла в обратном направлении, чтобы выяснить, какие дополнительные конструкции, если таковые имеются, необходимы для получения этих доказательств. Этот огромный пул данных был отфильтрован, чтобы исключить похожие примеры, в результате чего в окончательном наборе обучающих данных осталось 100 млн уникальных примеров различной сложности, из которых 9 млн содержали добавленные конструкции. Благодаря такому большому количеству примеров того, как эти конструкции привели к доказательствам, языковая модель AlphaGeometry способна давать хорошие предложения для новых конструкций при решении олимпиадных задач по геометрии.
Вот как прокомментировал AlphaGeometry бывший золотой призер математических олимпиад Эван Чен:
Результаты AlphaGeometry впечатляют, поскольку они проверяемы и понятны. Предыдущие решения, основанные на доказательствах, оказывались неудачными (результаты были верными только иногда и требовали проверки человеком). У AlphaGeometry нет этого недостатка: его решения имеют структуру, поддающуюся машинной проверке, но при этом удобочитаемы для человека. Можно представить компьютерную программу, решающую геометрические задачи с помощью систем координат и грубой силы — множества страниц утомительных алгебраических вычислений. AlphaGeometry — другое дело, она использует правила классической геометрии с углами и подобными треугольниками, как это делают ученики
Ну а месяц назад, напомним, Google DeepMind анонсировала метод поиска новых решений в области математики и информатики, FunSearch. Как заявили тогда авторы, их работа представляет собой первый случай, когда сделано новое открытие для решения открытых проблем в области науки или математики с использованием больших языковых моделей (LLM). Как и в случае AlphaGeometry, в FunSearch применяется гибридный подход: объединение предварительно обученной LLM (которая отвечает за генерацию творческих решений в форме компьютерного кода) с автоматическим «оценщиком» (который защищает от галлюцинаций и неверных идей). В Google DeepMind тогда заявили, что совершенствование заложенного в FunSearch подхода может способствовать решению различных насущных научных и инженерных проблем общества. В этот раз была озвучена не менее амбициозная цель: создание логики для систем искусственного интеллекта следующего поколения. А в долгосрочном плане — создание систем ИИ, способных обобщать любые математические области, развивая сложное решение задач и рассуждения (reasoning), от которых будут зависеть появление AGI.
Другая примечательная новость этой недели про ИИ касается Meta (Facebook). Основатель и глава компании, Марк Цукерберг, на днях сообщил, что в процессе обучения находится LLama 3 — третье поколение знаменитой языкой модели от Meta. Знаменита она прежде всего тем, что является опенсорсной, несмотря на свои размеры — выпущенная в июле прошлого года LLama 2 обучена на 2 трлн токенов и имеет до 70 млрд параметров. Правда, в сентябре 2023 её затмила модель Falcon от компании TII — та обучена на 3.5 трлн токенов и имеет до 180 млрд параметров. По слухам, самая лучшая на сегодня большая языковая модель GPT-4 (OpenAI) имеет 1.8 трлн параметров. Поэтому не исключено, что LLama 3 будет иметь аналогичные размеры — оставаясь при этом, будем надеяться, опенсорсной моделью.
Но лично на меня впечатление произвела не новость про и без того очевидный релиз LLama 3, а размеры вычислительного кластера, на котором, вероятно, будут обучаться будущие модели Meta. По словам Цукерберга, до конца года его компания планирует приобрести 350 тыс графических ускорителей Nvidia H100 (2022), а в сочетании с другими видеокартами — эквивалент 600 тыс Nvidia H100. Как пишут наши коллеги на Телеграм-канале Сиолошная, GPT-4, по слухам, обучалась на 25 тыс графических ускорителей Nvidia A100 (2020), причем этот процесс занял три месяца. Поскольку H100 втрое производительнее, то 600 тыс таких видеокарт будет иметь 72-кратное превосходство над кластером, на котором обучалась GPT-4.
Дальнейшие рассуждения будут сугубо на правах диванной аналитики — с игнорированием сложностей аппаратного и программного масштабирования больших языковых моделей до очень больших языковых моделей, не вполне корректного сравнения ИНС с мозгом человека, и т.д. Так вот, если предполагаемый размер GPT-4 (1.8 трлн параметров) умножить на увеличение будущего вычислительного кластера Meta по сравнению с предполагаемым размером вычислительного кластера, на котором обучался GPT-4 (72x), то мы получим модель со 130 трлн параметров. Для сравнения, количество синаптических связей в мозге оценивается приблизительно в 100 трлн (в некоторых источниках — несколько сотен триллионов). С точки зрения этих весьма условных выкладок получается, что до создания искусственного аналога человеческого мозга осталось не так много времени. Что вполне согласуется с самыми смелыми оценками сроков появления AGI — уже в ближайшие годы.
Как бы то ни было, разработчики движутся по пути усовершенствования не только подхода к созданию ИИ (прекрасным образцом которого является AlphaGeometry, сочетающий большую языковую модель и символьную логику, почти забытую со времен начала бума ИНС в 2012), но и увеличения размеров больших языковых моделей. Которые, в свою очередь, упираются в повышение производительности вычислительных кластеров, на которых эти модели обучаются. На этой неделе информагентство Bloomberg в очередной раз напомнило о намерении возглавляющего OpenAI Сэма Олтмена инвестировать миллиарды долларов в создание заводов по производству процессоров. Правда, по-прежнему неизвестно какую архитектуру получат эти процессоры — будут ли это традиционные графические ускорители, тензорные процессоры (вроде анонсированных в 2022 году Google TPU v4, Habana Gaudi2 и Tachyum Prodigy T16128) или нейроморфные чипы (наподобие Loihi).