Tesla представила Optimus Gen 2, опенсорсная Mistral 8x7B сравнялась с GPT-3.5, создан компьютер с использованием живых нейронов, DeepMind сообщила о первых математических открытиях, сделанных при помощи искусственного интеллекта, а Intel продлевает закон Мура

Как и предыдущие, минувшая неделя была богата интересными новостями на тему искусственного интеллекта.
На днях были анонсированы сразу две интересные языковые модели, Phi-2 и Mistral 8x7B (Small). Согласно разработавшей Phi-2 компании Microsoft, в некоторых сложных тестах (например, по программированию) Phi-2 с 2.7 млрд параметров соответствует или превосходит в 26 раз более крупную модель Llama-2-70B. Её обучение заняло две недели на 96 графических ускорителях Nvidia A100 трехлетней давности. При этом Phi-2 не подвергалась настройке ни посредством RLHF (обучения с подкреплением на основе отзывов людей), ни посредством т.н. файн-тюнинга.
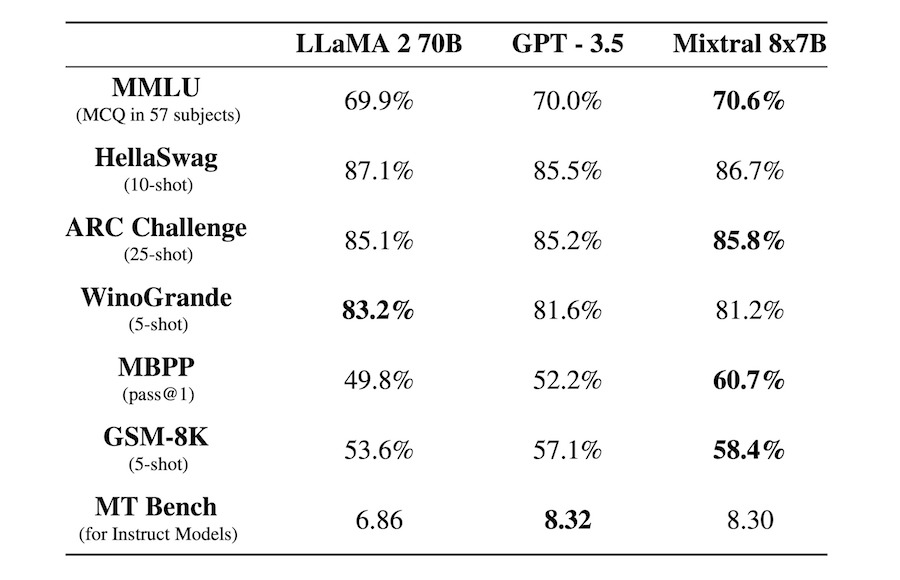
Другая модель, разработанная одноименной компанией Mistral 8x7B, значительно крупнее, и при этом у неё открытый исходный код в части значений весов. Фактически Mistral 8x7B представляет собой набор из восьми моделей, каждая из которых имеет 7 млрд параметров и свою специализацию в определенной предметной области. Две из моделей задействованы в формировании ответа по пользовательскому запросу. Общее количество параметров Mistral 8x7B — 46.7 млрд, а непосредственно в формировании ответа задействованы 12.9 млрд. Длина контекста — 32 тыс токенов (как у Gemini Ultra, хотя качество запоминания контекста одной и той же длины в разных моделях может сильно различаться).
И при этом, будучи фактически опенсорсной моделью, в бенчмарках Mistral 8x7B в среднем соответствует и даже превосходит (в бенчмарке по программированию MBPP) GPT3.5 — модель, на базе которой 30 ноября 2022 года запустили нашумевший чат-бот ChatGPT. Т.е. можно констатировать, что опенсорсная модель от лучших разработок в этой области отстает всего на один год. Любой желающий может скачать её себе на компьютер. но какая от него потребуется производительность не вполне понятно. Согласно некоторым источникам, достаточно современного Mac, но один из тестировавших модель блогеров утверждает, что ему потребовалась пара графических ускорителей Nvidia A100. Наряду с версиями Nano (7B) и Small (8x7B), компания Mistral предлагает платный доступ к еще более крупной модели, Medium. По предварительным впечатлениям тестировавшего её блогера, она почти соответствует GPT-4.
Две другие интересные новости вышли буквально в один день. 14 декабря OpenAI опубликовала работу под названием «Обобщение от слабого к сильному». Она посвящена проблеме, которая неизбежно возникнет с появлением AGI, т.н. сильного интеллекта: как обеспечить его alignment (соответствие целям и ограничениям человека), если данный AGI (или даже ASI, сверхсильный ИИ) окажется умнее человека? Или, как это звучит в формулировке OpenAI, могут ли маленькие модели контролировать большие? По результатам исследования этого вопроса на примере GPT-2 и GPT-4 оказывается, что да, могут — даже обучаясь на данных, размеченных более «глупой» GPT-2, более «умная» GPT-4 становится еще «умнее».
В тот же день другой гигант ИИ-индустрии, Google DeepMind, анонсировал метод поиска новых решений в области математики и информатики, FunSearch. Как заявляют авторы, их работа представляет собой первый случай, когда было сделано новое открытие для решения открытых проблем в области науки или математики с использованием больших языковых моделей (LLM). В частности, речь идет о двух комбинаторных задачах — из карточной игры Сет и об упаковке в контейнеры. FunSearch работает путем объединения предварительно обученной LLM, которая отвечает за генерацию творческих решений в форме компьютерного кода, с автоматическим «оценщиком», который защищает от галлюцинаций и неверных идей. Путем повторения этих двух компонентов первоначальные решения «превращаются» в новые знания. В Google DeepMind рассчитывают, что совершенствование заложенного в FunSearch подхода может способствовать решению различных насущных научных и инженерных проблем общества.
Следующая новость затрагивает одну из самых фантастических и пугающих тем — создания искусственной нейронной сети на базе живых нейронных клеток. Группа исследователей Индианского университета в Блумингтоне создала компьютер, где в качестве ИНС (помимо входного и выходного слоев) используется (для т.н. резервуарных вычислений) выращенная в лаборатории из стволовых клеток ткань человеческого мозга. После двухдневного обучения система под названием Brainoware с 78% точностью определила голос какого мужчины, из восьми, она слышит. Помимо этических моментов, одной из главных проблем данного подхода является поддержание органоидов в живом и здоровом состоянии.
Это не первая разработка такого рода — год назад в биотехнологическом стартапе Cortical Labs вырастили культуру из 800 тыс живых клеток (её назвали DishBrain), которую за 5 мин обучили компьютерной игре Pong.
Пожалуй самая заметная новость этой недели касается человекоподобного робота Tesla — компания представила его второе поколение, Optimus Gen 2. Он «похудел» на 10 кг, стал ходить на 30% быстрее, научился двигать головой и сохранять равновесие во время приседания. А еще у его пальцев 11 степеней свободы и датчики, позволяющие манипулировать хрупкими предметами — такими как яйцо, например. Само по себе это событие для робототехники возможно и не слишком важное. Но это очередной повод задуматься о революции, которая, по-видимому, начнется уже в ближайшие годы в этой индустрии благодаря применению мультимодальных систем (вроде Gemini — по крайней мере как она выглядела на презентации Google) для взаимодействия роботов с окружающим миром.
Ну и напоследок — хорошая новость, касающаяся производительности компьютерного железа. На состоявшейся на днях конференции IEDM 2023 Intel продемонстрировала схему многоуровневой компоновки транзисторов. В компании рассчитывают, что к 2030 году такая компоновка позволит достигнуть плотности в 1 трлн транзисторов на один процессор. Для сравнения, самый большой и производительный чип Apple последнего поколения, 3-нанометровый M3 Max, содержит 92 млрд транзисторов. Если, как мы предполагали еще в 2017, закон Мура продолжит действовать как минимум до 2030 года, то к тому времени потомок нынешнего чипа из 100 млрд транзисторов будет иметь 800 млрд транзисторов. Что вполне согласуется с прогнозом Intel.