Nvidia представила DGX-A100, A100 и GA100

В 16:00 (МСК) Nvidia опубликовала «кухонную» презентацию Дженсена Хуана, посвященную серверным вычислениям. Таким образом, новое ГПУ Nvidia из области утечек и слухов перешло в плоскость вполне официальной информации, которую мы и предлагаем вашему вниманию. Начнем с характеристик:
| A100 | Tesla V100 | |
| Дата анонса | май 2020 | май 2017 |
| ГПУ | GA100 | GV100 |
| Архитектура | Ampere | Volta |
| Техпроцесс | TSMC 7 нм | TSMC 12 нм |
| Площадь кристалла | 826 мм2 | 815 мм2 |
| Кол-во транзисторов | 54 млрд | 21.1 млрд |
| Кол-во ядер CUDA (FP32) | 6912 из 8192 1 | 5120 |
| Кол-во тензорных ядер | 432 из 512 1 | 640 |
| Кол-во текстурных блоков | 432 из 512 1 | 320 |
| Частота повышенная (boost) | 1410 МГц | 1530 МГц |
| Память | 40 Гб HBM2e | 16/32 Гб HBM2 |
| Разрядность | 5120-бит | 4096-бит |
| Пропускная способность | 1.6 Тб/с | 900 Гб/с |
| Регистр | 27,648 Кб | 20,480 Кб |
| Кэш L1 | 20,736 Кб | 13,824 Кб |
| Кэш L2 | 40,960 Кб | 6,144 Кб |
| TDP | 400 Вт | 250 Вт |
| Интерфейс с другими графическими ускорителями | NVLink 3 (600 Гб/с) PCIe 4 (31.5 Гб/с) | NVLink 2 (300 Гб/с) PCIe 3 (15.75 Гб/с) |
1 В A100 заблокированы 20 SM из 128
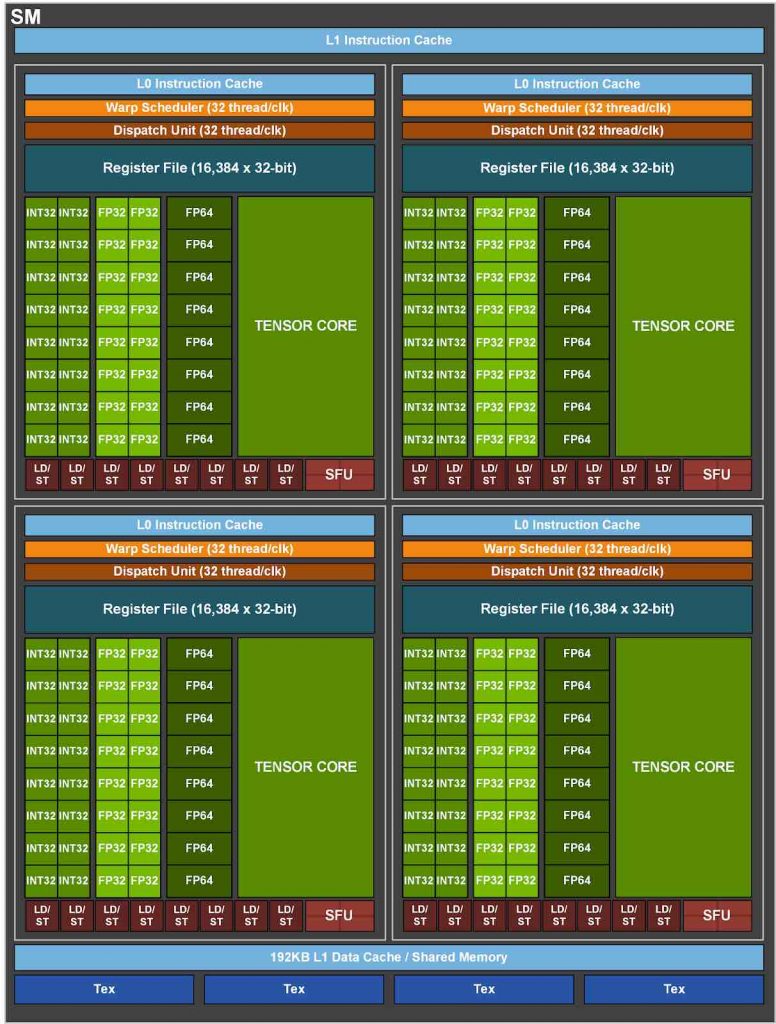
Многие из этих нововведений появились благодаря 11-у поколению CUDA. В числе его особенностей:
- Поддержка процессоров не только с архитектурой x86_64, но и Arm64 с IBM POWER
- Возможность разделения одного физического ГПУ на множество виртуальных. Это первое ГПУ, которое можно масштабировать в обе стороны.
- 3-е поколение тензорных ядер, в которых ускорено перемножение матриц (активно применяемое в машинном обучении) для всех типов данных: бинарных, INT4, INT8, FP16, Bfloat16, TF32 и FP64.
Особый интерес представляет TF32, представляющий собой тип данных с плавающей точкой, оптимизированный именно для тензорных операций. Благодаря ему скорость перемножения матриц многократно возросла. Ниже приводится производительность в операциях с плавающей точкой (в скобках — для тензорных вычислений), при работе с повышенной (boost) частотой:
| A100 | Tesla V100 | |
| FP64 | 9.7 (19.5) TFLOPS | 7.8 (7.8) TFLOPS |
| FP32 | 19.5 (156) TFLOPS | 15.7 (15.7) TFLOPS |
| FP16 | 78 (312) TFLOPS | 31.4 (125) TFLOPS |
| INT8 | (624) TOPS | 62 TOPS |
| INT4 | (1248) TOPS | — |
| INT32 | 19.5 TOPS | 15.7 TOPS |
Важной особенностью 3-го поколения тензорных ядер также является поддержка вычислений на т.н. разреженных (с преимущественно нулевыми элементами) матрицах. Как уже рассказывал Gadgets News, разрежение матрицы избавляют от необходимости умножать на нули, благодаря чему снижается избыточная нагрузка и за счет высвободившихся ресурсов повышается производительности. Соответственно в вычислениях на разреженных матрицах производительность A100 увеличивается вдвое (т.е. цифры в её столбце надо умножить на два).
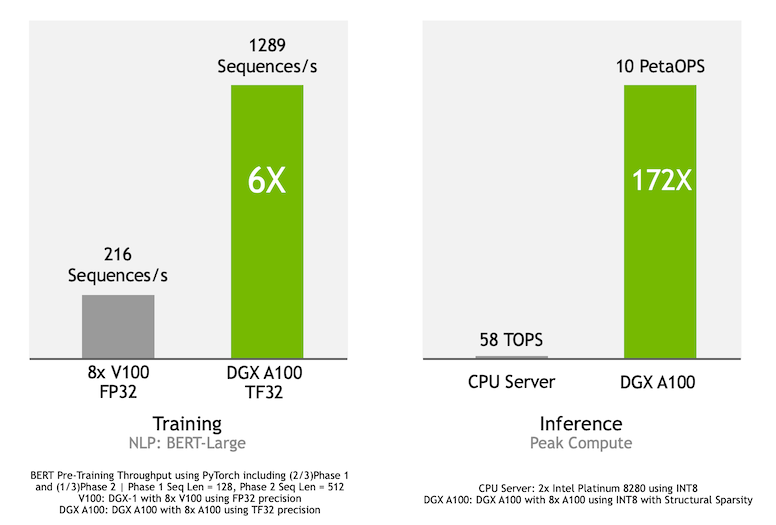
О производительности A100 в реальных задачах позволяют судить следующие результаты:


Кульминацией презентации стал новый суперкомпьютер Nvidia, DGX A100. Ниже приводятся его сравнительные характеристики вместе с двумя предшественниками:
| DGX A100 | DGX-2 | DGX-1 | |
| Дата анонса | май 2020 | март 2018 | май 2017 |
| Цена | $199 тыс | $399 тыс | $149 тыс |
| Энергопотребление | 6.5 кВт | 10 кВт | 3.5 кВт |
| Вес | 143 кг | 159 кг | 61 кг |
| Процессоры | 2 x AMD Rome 7742 | 2 x Intel Xeon Platinum | 2 x Intel Xeon E5-2698 v4 |
| Графические ускорители | 8 x A100 40 Гб HBM2 | 16 x Tesla V100 32 Гб HBM2 | 8 x Tesla V100 16 Гб HBM2 |
| Чипы NVSwitch | 6 | 12 | — |
| Оперативная память | 1 Тб | до 1.5 Тб DDR4 | до 0.5 Тб DDR4 |
| Видеопамять | 320 Гб (8 x 40 Гб) | 512 Гб HBM2 (16 x 32 Гб) | 256 Гб HBM (8 x 32 Гб) |
| Постоянная память (SSD) | 15 Тб NVMe Gen4 | 30 Тб NVMe (до 60 Тб) | 4 x 1.92 Тб NVMe |
| Производительность | 5 петафлопс | 2 петафлопс | 1 петафлопс |
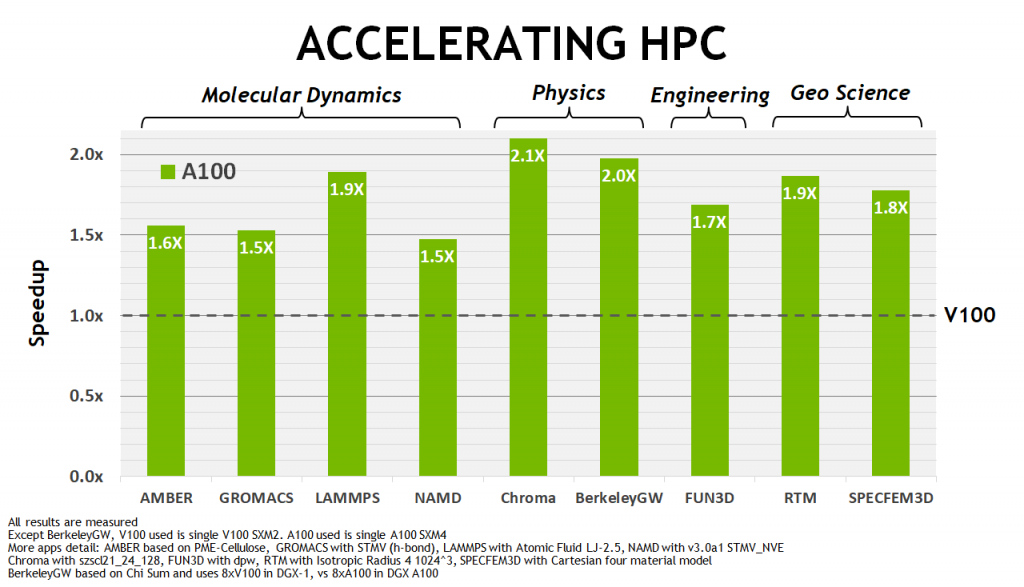
А вот так выглядят результаты в реальных тестах (данные по DGX A100 были получены с применением разреженных матриц, вдвое увеличивающих скорость вычислений):