Хроники ИИ: Llama 3.1 (405B), Gemini 1.5 Pro и Grok-2, AlphaProof с AlphaGeometry 2 и AlphaProteo

Вторая половина лета ознаменовалась очередными интересными анонсами в индустрии ИИ. Во-первых, это выпущенная Meta опенсорсная Llama 3.1 405B (с 405 млрд параметров). На данный момент в рейтинге больших языковых моделей она набирает 1266 баллов, что вполне сопоставимо с результатами Claude 3.5 Sonnet (1270) и одного из предыдущих релизов GPT-4o (1263). Контекстное окно при этом составляет 128 тыс токенов — столько же, сколько у топовой GPT-4o, но меньше, чем у Claude 3.5 Sonnet (200 тыс токенов).
Llama 3.1 405B обучалась на 16 тыс видеокартах Nvidia H100 (серверах Grand Teton из 8 ГПУ и 2 ЦПУ), каждая с 80 Гб HBM3 и энергопотреблением 700 Вт. Согласно Hugging Face, модель обучалась на 15 трлн токенов из открытых источников по состоянию на конец 2023 года, файнтюнилась на открытых наборах инструкций, а также на 25 млн синтетических примеров. Обучение заняло 30.84 млн ГПУ-часов, что для такого вычислительного кластера расчетно составляет чуть больше 2.5 мес (80 суток).
Разумеется, скачать такую модель на домашний ноутбук не получится — даже квантованную (сжатую, например, до 8-битной точности) версию Llama 3.1 405B можно запустить на сервере из восьми графических ускорителей Nvidia H100 — например, 10-киловаттном DGX H100, цена которого достигает полумиллиона долларов (если найдете). Но для стартапов с капиталом хотя бы в несколько миллионов долларов это вполне подъемная инвестиция.
Неожиданным сюрпризом стал неожиданный релиз экспериментальной версии Gemini 1.5 Pro, которая сразу вырвалась на 1-е место рейтинга больших языковых моделей в общем зачете. Правда, в августе вышла обновленная версия ChatGPT-4o (1316 баллов), которая сместила Gemini-1.5 Pro (1300) на 2-ю позицию. Другой успешный новичок — занявший 3-е место Grok-2 (1294), 2-е поколение большой языковой модели от основанной Илоном Маском xAI. Любопытно, что Claude 3.5 Sonnet (1270) теперь находится на уровне уменьшенных версий своих конкурентов, GPT-4o-mini (1274) и Gemini-1.5-Flash (1268). Правда, в математике Claude 3.5 Sonnet по-прежнему занимает 1-е место (в программировании — 2-е, после ChatGPT-4o).
Другой сюрприз от Google — Gemma-2 (2B), самая маленькая (2 млрд параметров) версия семейства опенсорсных моделей Gemma. Для своих размеров она показывает неплохой результат — 1132 балла (для сравнения, первая версия GPT-4 — 1186 баллов). Но главное — это Gemma Scope, набор инструментов, позволяющий исследователям понять внутреннюю работу модели. Фактически это коллекция из более чем 400 свободно доступных, открытых разреженных автокодировщиков (SAE) с более чем 30 млн изученных признаков (грубо говоря, связей между словами). Google рассчитывает, что этот инструмент позволит исследователям изучать развитие признаков по всей модели, а также их взаимодействие между собой и объединение друг с другом для образования более сложных признаков. В том же направлении работает и другая ИИ-компания, Anthropic. Как уже рассказывал Gadgets News, в мае она опубликовала работу об извлечении интерпретируемых признаков своей средней модели Claude 3 Sonnet. Авторы исследования научились выявлять у модели нейроны, ответственные за миллионы её конкретных представлений, и даже находить территориально близкие к ним объекты (например, Мост Золотые Ворота в Сан-Франциско и остров Алькатрас). Соответственно корректируя соответствующие параметры модели, можно воздействовать на её ответы. Например, сделать так, что модель «сходит с ума» и зацикливается на Золотых Воротах, которыми себя воображает. И вот теперь большой шаг в сторону интерпретируемости (и соотвественно улучшения) больших языковых моделей сделала Google.
Вторая большая новость — это, безусловно, AlphaGeometry 2 и AlphaProof. AlphaGeometry 2 представляет собой 2-е поколение выпущенной Google DeepMind в начале года модели, которая задачи по геометрии из международной математической олимпиады решила почти на уровне золотого медалиста (25 vs 25.9). Как уже рассказывал Gadgets News, AlphaGeometry сочетает 1) большую языковую модель и 2) основанный на правилах формальной логики механизм символьного вывода, работающие в тандеме для поиска решений. Первая система обеспечивает быстрые, «интуитивные» идеи, а вторая — обдуманное, рациональное принятие решений. Вторая версия значительно улучшена: из всех геометрических задач, придуманных для международной олимпиады за последние 25 лет, AlphaGeometry 2 смогла решить 83% против 53% у своего предшественника.
Гибридом является и AlphaProof — она сочетает предобученную языковую модель Gemini (которая перевела с естественного языка на формальный язык Lean миллионы математических задач) и алгоритм обучения с подкреплением AlphaZero (обобщенную, т.е. способную играть в разные игры, версию знаменитой AlphaGo). Вот как в блоге DeepMind поясняется принцип работы программы:
При столкновении с проблемой AlphaProof генерирует варианты решений, а затем доказывает или опровергает их, просматривая возможные шаги доказательства в Lean. Каждое найденное и проверенное доказательство используется для усиления языковой модели AlphaProof, повышая ее способность решать последующие, более сложные проблемы.
Мы тренировали AlphaProof для Олимпиады, доказывая или опровергая миллионы задач, охватывая широкий спектр трудностей и математических тем в течение нескольких недель, предшествовавших соревнованию. Цикл обучения также применялся во время соревнования, подкрепляя доказательства самогенерируемых вариаций задач соревнования до тех пор, пока не было найдено полное решение.
Из шести задач олимпиады этого года AlphaGeometry 2 решил единственную геометрическую задачу, а AlphaProof — две алгебраические задачи и одну задачу по теории чисел, найдя ответ и доказав его правильность. Это включало самую сложную задачу на Олимпиаде, решенную всего пятью участниками Олимпиады этого года. Две комбинаторные задачи остались нерешенными. В результате система набрала 28 из 42 баллов (6 задач по семь баллов), недобрав всего один балл до золотой медали, которую в этом году получили 58 из 609 участников (каждый десятый). Правда, если на Олимпиаде у студентов на решение шести задач отводится 9 часов (две сессии по 4.5 часа), то детище DeepMind задачу по геометрии решило за 19 секунд (после получения её в формализованном виде), одну задачу — за несколько минут, и две остальные — аж до трех дней.
К этой же категории новостей можно отнести разработку японского стартапа Sakana AI, основанного двумя бывшими сотрудниками Google AI, Дэвидом Ха и Лионом Джонсом, а также японским предпринимателем Реном Ито. В компании ни много ни мало претендуют на создание первой комплексной системы для совершения полностью автоматизированных научных открытий. Согласно официальному сообщению на сайте компании, AI Scientist автоматизирует весь цикл исследований: от генерации новых исследовательских идей, написания необходимого кода и проведения экспериментов до обобщения экспериментальных результатов, их визуализации и представления результатов в виде полноценной научной рукописи. Фактически речь идет о написании научных статей, и несколько их примеров уже опубликованы. Насколько эти статьи содержательны и полезны с научной точки зрения, пока сказать трудно — вероятно пройдут месяцы, прежде чем им будет дана объективная и компетентная оценка. Любопытно, что в процессе работы система периодически редактирует собственный код. Пока это происходит не лучшим образом (например, превысив лимит ожидания, программа попыталась изменить его), но сам по себе этот факт вполне соответствует идее самосовершенствования будущих систем искусственного интеллекта.
DeepMind не прекращает разработок систем искусственного интеллекта и в области биологии. Вслед за анонсированной в мае AlphaFold 3, на днях компания представила AlphaProteo. Это программа, которая создает трехмерные модели искусственных белков с заданными свойствами — а именно способных связываться (прикрепляться) с заданными белками. Например, среди естественных, созданных природой, белков связывающими являются альбумин (основной транспортный белок крови, который переносит жирные кислоты, гормоны и лекарства) и гемоглобин (связывает и переносит кислород в крови). Синтез искусственных белков, связывающих (для транспортировки, защиты или, наоборот, уничтожения, и т.д.) определенные белки, имеет огромное значение в том числе для медицины. При помощи AlphaProteo были созданы пространственные структуры белков, способных связываться с BHRF1 (белок, который защищает от гибели клетки, инфицированные вирусом Эпштейна-Барра, и таким образом позволяет ему долго сохраняться в организме хозяина), SC2RBD (ключевой компонент спайкового белка вируса SARS-CoV-2, который отвечает за связывание вируса с рецепторами ACE2 на поверхности клеток, что позволяет вирусу проникать в клетки и вызывать инфекцию), а также IL-7Rɑ , PD-L1 , TrkA , IL-17A и VEGF-A (белки, участвующие в развитии рака, воспаления и аутоиммунных заболеваний).
Наиболее успешный результат был получен для BHRF1 — в 88% случаев белок, синтезированный в лаборатории по сгенерированной AlphaProteo трехмерной модели, оказался связывающим с достаточно высокой силой. Константа диссоциации (Kd, чем она меньше — тем сильнее связывание) составила 8.5 nM. Наиболее скромный результат был получен для белка TrkA — 9% (т.е. из каждых 11 протестированных в лаборатории белков-кандидатов, созданных AlphaProteo, примерно 1 оказался успешным в связывании с TrkA). Зато сила связывания у успешных кандидатов значительно превосходит BHRF1 — константа диссоциации не превысила 1 nM.
AlphaGeometry 2 с AlphaProof и AlphaProteo — это уже не «стохастические попугаи», генерирующие правдоподобную чушь грамотные ответы на почти любые заданные им вопросы, довольно сносно программирующие и решающие стандартные задачи из школьной и даже вузовской программы. Решение научных задач — своего рода философский камень для разработчиков ИИ. Если создание AGI, человекоподобного ИИ, обещает прежде всего социальную революцию (когда большинство человечества перестанет работать ради пропитания и станет жить на безусловный базовых доход), то ИИ-математик, ИИ-биолог или ИИ-инженер обещает экспоненциальный прирост научного знания. Некоторые исследователи (например, Ян Лекун) настроены весьма скептически относительно способности больших языковых моделей рассуждать подобно человеку. Одним из критериев такой способности является решение математических задач, поэтому значимость достижения в лице вышеупомянутых AlphaGeometry 2 и AlphaProof, несмотря на медленную скорость решения ими некоторых задач, трудно переоценить. Ниже вы можете видеть результаты, опубликованные с релизом GPT-4o, которая в рейтинге больших языковых моделей на данный момент занимает первое место:
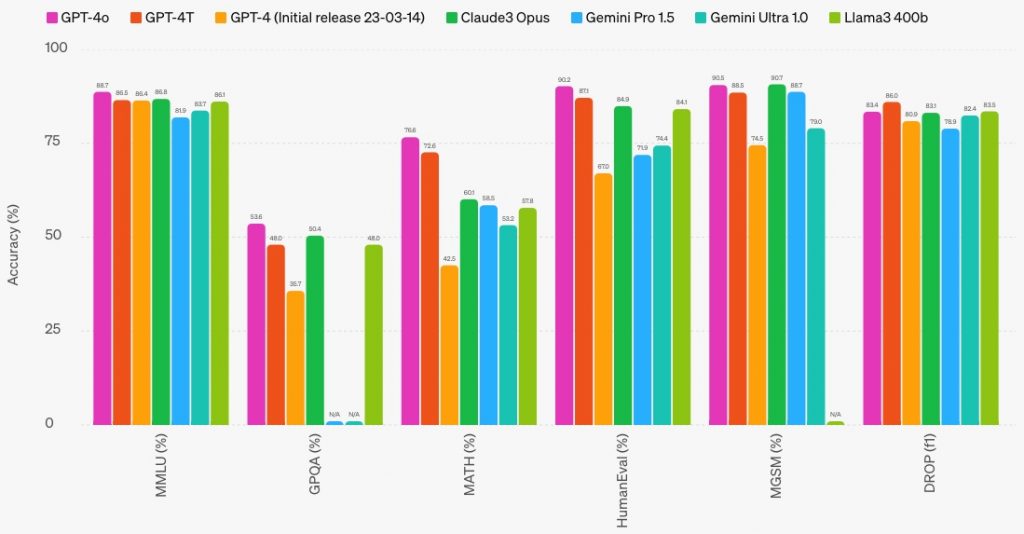
Согласно этой диаграмме, топовая GPT-4o набирает:
- 88.7% в бенчмарке MMLU (школьная математика, компьютерные науки, история США, право и т.д.)
- 53.6% — в GPQA (тест из 448 вопросов по биологии, физике и химии)
- 76.6% — в MATH (12.5 тыс задач по математике)
- 90.2% — в HumanEval (программирование на Python)
- 90.5% — в MGSM (школьная математика)
- 83.4% — в DROP F1 (извлечение из текста численной информации).
Самым профильным математическим бенчмарком здесь является MATH, и GPT-4o набирает в нем 76.6%. Для сравнения, у первой (март 2023) версии GPT-4 — 42.5%, а на момент публикации работы, посвященной MATH (ноябрь 2021), большие языковые модели набирали от 3% до 7%. Для сравнения, аспирант факультета информатики, «который не очень любит математику», справился с MATH примерно на 40%, а трехкратный золотой медалист вышеупомянутой международной математической олимпиады — на 90%. Таким образом, прогресс в области решения математических задач колоссальный — с 3-7% до 76-77% за 2.5 года, и казалось бы большие языковые модели в математике сравнялись с человеком. Однако в июле этого года вышла обновленная версия этого бенчмарка, We-MATH. В ней отдельно сгруппированы задачи, решение которых состоит из одного, двух и трех шагов. Многошаговые задачи сложнее, поскольку требуют более глубокого понимания и умения интегрировать различные знания. И если в одношаговых задачах GPT-4o набирает 73%, то в двухшаговых — 58%, а в трехшаговых — 44%. В еще более требовательном бенчмарке, который содержит 8.5 тыс задач по математике и физике олимпиадного уровня (OlympiadBench) лучшая на то время (февраль 2024) модель, GPT-4V, набрала всего 18%.
Аналогично задачи по программированию, в котором математические способности весьма востребованы. В бенчмарке HumanEval модель GPT-4o набирает внушительные 90%, однако в гораздо более требовательном SWE (реальные задачи с ресурса GitHub) лучший на сегодня официальный результат составляет 22%. Впрочем, еще в августе стартап Cosine анонсировал систему Genie, достигшую, как утверждается, 30%. На сайте стартапа сообщается, что для включения в таблицу результатов SWE-Bench теперь запрашивает полный рабочий процесс модели, в дополнение к окончательным результатам — в Cosine решили отказаться от этого по соображениям конфиденциальности.
Однако непосредственно большие языковые модели в серьезном программировании результаты показывают более чем скромные — согласно всё тому же стартапу Cosine, в бенчмарке SWE модель GPT-4 набирает всего 1.31%. И возможно здесь ситуацию переломит практическая реализация в больших языковых моделях технологии, подобной Q-STaR. Напомню, что название STaR (Self-Taught Reasoner) приводится в работе STaR: Bootstrapping Reasoning With Reasoning, опубликованной еще в 2022. В мае этого года, вышла новая работа — Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking. В них описывается метод, который генерирует промежуточные рассуждения, используемые для улучшения предсказания большой языковой моделью следующего слова. Как уже рассказывал Gadgets News, в июне этого года информагентство Reuters в очередной раз подтвердило слухи про т.н. Q* (Q-Star) в недрах OpenAI, и раскрыла его кодовое имя — Strawberry (клубника). Quiet-STaR не имеет прямого отношения к OpenAI, но по словам анонимного сотрудника OpenAI, Strawberry имеет с Quiet-STaR сходство. И вот в августе глава OpenAI, Сэм Олтмен, опубликовал в Твиттере сообщение «Люблю лето в саду» с фотографией куста клубники с пятью ягодами. Сообщение Олтмена явно намекает на интеграцию метода в следующее поколение большой языковой модели OpenAI, GPT-5. Другой намек на ту же тему Олтмен сделал, когда загадочный пользователь Твиттер @iruletheworldmo написал ему следующее сообщение: «Добро пожаловать на 2-й уровень. Как ощущения? Я заставил тебя меня почувствовать?» Олтмен ответил «Восхитительно». В сообщении @iruletheworldmo (чей ник переводится как «Я правлю миром») содержится явный намек на дорожную карту OpenAI, которая, согласно утечкам, содержит пять этапов развития искусственного интеллекта:
- Чат-боты, разговорный ИИ
- ИИ, способный к рассуждению (reasoning)
- Агенты, способные к выполнению действий
- ИИ-новатор, способный на изобретения
- ИИ, способный выполнять работу целой организации.
Ответ Олтмена можно расценивать как подтверждение того, что уровень ИИ, способного к рассуждениям (за что, по слухам, и отвечает Q-Star/Strawberry), достигнут. В свою очередь вопрос «Я заставил тебя меня почувствовать?» намекает на фразу, которую любил говорить своим сотрудникам в OpenAI Илья Суцкевер — “Feel the AGI” («Почувствуйте AGI»). Поэтому сомнений в реальности Q-Star/Strawberry и его реализации в GPT-5 практически не осталось — главный вопрос в том, насколько большое влияние эта технология окажет на интеллектуальные возможности разработанной OpenAI модели. По слухам, интеграция этой технологии в преемника нынешней модели GPT-4o (в новейших утечках фигурирует под именем Orion) позволила набрать в бенчмарке MATH до 90% (GPT-4o, напомню — 76.6%). Согласно ресурсу The Information (доступен по платной подписке), технология Strawberry используется для генерации синтетических данных для обучения модели Orion. Также сообщается, что новая модель была продемонстрирована представителям американских федеральных властей.
Вторая половина лета была также богата анонсами моделей, генерирующих короткие (несколько секунд) видео по текстовому описанию или изображению — вот неполный список лучших на сегодня моделей:
- Gen-3 Alpha (Runway, США) — июнь 2024
- Dream Machine 1.5 (Luma, США) — август 2024 (вчера обновилась до 1.6, куда добавили движение камеры)
- Kling (Kuaishou, Китай) — июль 2024 (глобальный релиз)
- Hotshot (Hotshot, США) — август 2024
- Video-1 (MiniMax, Китай) — сентябрь 2024.
Нашумевшая после своего анонса Sora (OpenAI) для широкой публики по-прежнему недоступна. Самой лучшей среди вышеперечисленных моделей пожалуй является Video-1 (MiniMax), но примечательно, что одну из моделей, Hotshot, создал стартап всего из четырех инженеров. На обучение модели ушло 4 месяца и «много миллионов H100-часов». Если многие миллионы это, например, 6 млн часов, то значит в обучении были задействованы всего пара тысяч графических ускорителей Nvidia H100 — значительно меньше, чем требуется для обучения больших языковых моделей (см. ниже). Так что платформу для обучения моделей генерации видео при желании можно масштабировать на два порядка.
Ну и уже в начале сентября вышли две интересные новости. Начнем с проекта Sid — симуляции виртуального мира из тысячи автономных агентов, действующих в песочнице Minecraft. Судя по скупой информации, представленной авторами проекта (стартап Altera), агенты демонстрируют социальное поведение, но как эти агенты были обучены — неизвестно. Судя по официально предоставленной Altera информации, какую-то роль в этом могли сыграть большие языковые модели:
При разработке наших агентов для Project Sid было предпринято множество шагов для улучшения их социальных способностей, осведомленности и внутренних мыслительных процессов.
Один из основных аспектов — это разговор. Как и у людей, то, о чем агенты говорят друг с другом, должно зависеть не только от того, что они сказали ранее, но и от их отношений друг с другом. Чтобы обеспечить реалистичные разговоры, мы встроили модели социального мира в поведение наших агентов. В частности, наши агенты формируют и обновляют свои модели других агентов — их поведения, взглядов и потребностей, и используют эту информацию для общения и поведения в социальных ситуациях. Во-вторых, как и люди, агенты должны уметь говорить по многим причинам — раскрывать свои намерения, вести светскую беседу, делиться своими надеждами и мечтами. Мы разработали набор разговорных модулей, которые в определенных контекстах позволяют их речи соответствовать их действиям и намерениям, а в других контекстах позволяют им обсуждать идеи, оторванные от реальности.
Подтверждением этой версии является упоминание GPT-3.5 в более раннем сообщении главы стартапа Роберта Яна (Robert Yang), нейробиолога и бывшего доцента Массачусетского технологического института — агенты «использовали» эту LLM для добывания в Minecraft алмазов. При этом на сайте компании приводится еще более туманная информация:
Наши современные агенты работают на основе нашей системной нейробиологической композитной архитектуры — системы систем, вдохновленной мозгом, с моделями, отражающими префронтальную кору, системы памяти, социально-эмоциональные состояния и многое другое.
В мае Altera так описала свою миссию по созданию «цифровых людей»:
В частности, мы добавляем фундаментальные человеческие качества, которых в настоящее время не хватает искусственному интеллекту — автономность, связность, эмоции, эпизодическую память, быстрые процессы и обоснованные взаимодействия. Другими словами, мы разрабатываем продвинутых агентов ИИ, которые сосуществуют с нами в виртуальных средах. Эти агенты обладают сильным прочеловеческим социально-эмоциональным интеллектом и в конечном итоге достигнут самосознания.
Наш подход сосредоточен на развитии целостного интеллекта у цифровых людей. В отличие от традиционных моделей ИИ, которые сосредоточены исключительно на выполнении задач, мы отдаем приоритет созданию агентов, которые могут взаимодействовать разумно и эмпатично. Мы не стремимся создать единый сверхчеловеческий ИИ, который невозможно понять. Вместо этого наша цель — создать цифровых людей, которые понимают человеческие эмоции, формируют подлинные связи и обладают способностью к самоорганизации и совместным действиям.
Словом, ничего не понятно, но очень интересно.
Другой интересный анонс начала сентября — модель под названием Reflection, созданная стартапом HyperWrite на базе Llama-3.1-70B. Она обучена с помощью новой техники под названием Reflection-Tuning, при помощи которой большая языковая модель обнаруживает ошибки в своих рассуждениях и корректирует свой ответ. Вот что об этом пишут наши коллеги из Телеграм-канала Data Secrets:
Самое правдоподобное предположение: это еще одна дистиллированная модель, просто на этот раз использовались очень хорошо вычищенные синтететические данные. Поэтапно:
1) Из модели учителя генерируются внутренние рассуждения-монологи с использованием CoT («think step by step») или рефлекшн промптинга (то, что у нас в теге «»).
2) Эти рассуждения уточняются с использованием другой LLM или MoA. Таким образом происходит фильтрация плохих сэмплов.
3) Обучение или файнтюнинг модели ученика на уточненных проверенных рассуждениях-монологах.
Согласно возглавляющему HyperWrite Мэтту Шумеру (Matt Shumer), в некоторых бенчмарках Reflection превосходит лучшие из больших языковых моделей:
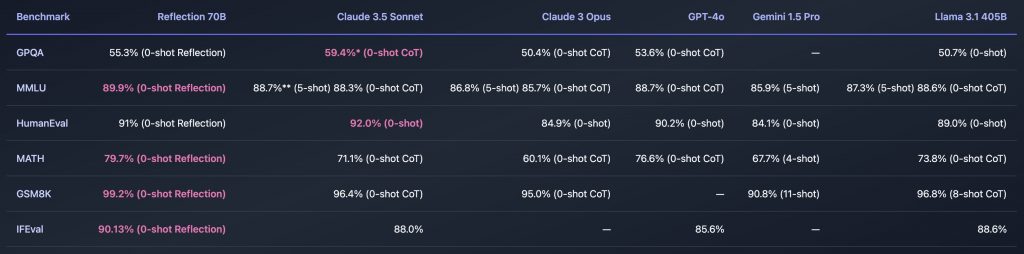
Впрочем, как и в случае с проектом Sid, выводы делать слишком рано. Денис Ширяев, CEO проекта neural.love, на своем Телеграм-канале отмечает несколько подозрительных моментов. Релиз Reflection сопровождался проблемами — она работала некорректно из-за проблем с конфигурацией. Затем выяснилось, что запросы к ней требуют применения специального системного промпта. А независимая проверка показала, что Reflection представляет собой файнтюнинговую версию не Llama-3.1, а Llama-3. Наконец один из пользователей онлайн-версии Reflection и вовсе заявил, что на самом деле это Claude 3.5 Sonnet. Мэтт Шумер обещал, что уже на этой неделе выйдет Reflection на базе Llama-3.1-405B, которая станет лучшей большой языковой моделью в мире. Поэтому нам остается лишь дождаться её релиза и результатов независимых тестов.
В заключение несколько слов о ближайшем будущем искусственного интеллекта. Марк Цукерберг заявил, что для обучения Llama 4, следующего поколения большой языковой модели компании Meta, потребуется почти в 10 раз больше вычислительных ресурсов, чем было задействовано при обучении Llama 3. Последняя была обучена на 16 тыс графических ускорителей Nvidia H100 (память 80 Гб HBM3, TDP 700 Вт). Таким образом, Llama 4 будет обучаться на вычислительном кластере, который будет эквивалентен почти 160 тыс Nvidia H100. Предприниматель не отрицает, что это рискованная инвестиция, но считает риск оправданным: «На данный момент я бы предпочел рисковать, наращивая потенциал до того, как он понадобится, а не слишком поздно, учитывая длительные сроки запуска новых проектов». Будет ли эта модель опенсорсной, как её предшественники — большой вопрос. И дело здесь в позиции не только руководства Meta, но и регуляторов, опасающихся за бесконтрольное распространение мощнейшего интеллектуального инструмента.
В свою очередь Илон Маск 2 сентября в очередной раз заявил о запуске в эксплуатацию кластера из 100 тыс ускорителей Nvidia H100. Ранее он сделал аналогичное заявление 22 июля (как говорится, хороших анонсов должно быть много). В последнем сообщении он отметил, что на создание кластера ушло четыре месяца, а еще через несколько месяцев кластер пополнится 50 тыс Nvidia H200, и таким образом достигнет 200 тыс Nvidia H100 в эквиваленте. Кластер предназначен для обучения Grok-3. Для сравнения, вышеупомянутый Grok-2 (на данный момент занимающий, напомню, 3-е место после ChatGPT-4o и Gemini 1.5 Pro) обучался всего на 15 тыс Nvidia H100. Помимо очевидного потенциала использования Grok в качестве чат-бота на социальной медиа-платформе X (в девичестве Твиттер), которую Илон Маск приобрел в 2022 году за $44 млрд, модель со временем призвана стать мозгом андроида Optimus. Последний, по мнению Маска, позволит увеличить рыночную капитализацию (совокупную стоимость акций) Tesla до $25 трлн (на данный момент — менее $700 млрд) и приносить до триллиона долларов прибыли в год…
И как сообщают наши коллеги с Телеграм-канала Сиолошная со ссылкой на ресурс The Information, Microsoft разместила заказ на от 700 тыс до 1.4 млн графических ускорителей следующего поколения (возможно, речь идет об Nvidia H200). Google — 400 тыс, Amazon — немного меньше. Так что гонка вооружений, в виде вычислительных ресурсов для обучения ИИ, идет полным ходом. Что, однако, не помешало рыночной капитализации Nvidia «похудеть» на днях почти на $280 млрд (примерно на 10%) после новости (впоследствии опровергнутой), что Министерство юстиции США направило компании повестку в суд по поводу нарушения антимонопольного законодательства.
В недавнем интервью глава Anthropic, Дарио Амодей, сравнил модель, обучение которой обойдется в $100 млрд, с нобелевским лауреатом. Появление таких моделей он прогнозирует, напомню, к 2028 году. В свою очередь Мира Мурати из OpenAI считает, что: «в ближайшие пару лет мы увидим интеллект уровня кандидата наук (PhD) для решения конкретных задач«, т.е. по её оценкам это случится к 2026 году. При этом нынешний уровень ИИ (стоимость обучения которого составляет около $100 млн) Мурати сравнила со старшеклассником, а Амодей и вовсе с новоиспеченным выпускником колледжа,
Руководитель другой очень влиятельной компании, Демис Хассабис из DeepMind, считает, что «в настоящее время мы далеки от интеллекта человеческого уровня по всем направлениям», а современный ИИ не дотягивает даже до кошки. Как я уже говорил, вероятно Хассабис рассуждает о широких возможностях человеческого интеллекта, тогда как Мурати подчеркивает, что речь идет о решении конкретных задач. Поэтому не удивляйтесь, если к 2028 действительно появится ИИ, способный решить задачу, посильную только для кандидата наук или даже крупного ученого, но совершающий ошибки при решении какой-нибудь простенькой задачки, придумывающий несуществующие литературные произведения (когда просишь его сообщить автора и название рассказа с заданным сюжетом), и т.д. Причем говоря «мы далеки от интеллекта человеческого уровня по всем направлениям», Хассабис возможно по-прежнему, как и год назад, допускает появление AGI уже в ближайшие десять лет. Кстати, на вопрос об ажиотаже вокруг ИИ Демис Хассабис недавно ответил, что хайп вокруг ИИ чрезмерен в краткосрочной перспективе, в результате чего люди ожидают от ИИ того, на что тот пока не способен. В то же время последствия создания AGI недооцениваются, считает глава DeepMind. В свою очередь Эндрю Ын в недавнем интервью высказал предположение, что от создания AGI (который ученый определил как ИИ, способный решать любые интеллектуальные задачи, посильные человеку) нас отделяют еще многие десятилетия — а возможно и больше.