Хроники искусственного интеллекта: GPT-4o и другие анонсы весны 2024

Со времени нашего последнего обзора интересных новостей в индустрии ИИ прошло уже почти три месяца, поэтому самое время рассказать о самых интересных событиях весны 2024. Начнем с, пожалуй, главной новости — анонса GPT-4o (omni, всесторонний). По своему качеству (если угодно, интеллекту) она соответствует лучшей на сегодня GPT-4 Turbo в общении на английском языке и написании программного кода, и существенно улучшилась в общении на других языках. Но главное достоинство GPT-4o — поддержка голосового интерфейса, причем на очень высоком уровне.
Во-первых, чат-бот говорит на удивление естественным голосом, с соблюдением уместной в контексте разговора интонации и эмоциональной окраски. Судя по приведенным примерам, чат-бот настроен на позитивный, часто веселый и временами игривый настрой. По вашему указанию он будет говорить быстро или медленно, с театральным пафосом или сарказмом, шептать или напевать, и даже изображать металлический голос робота.
Во-вторых, GPT-4o отличает невиданный доселе уровень интерактивности. Он не только отвечает на чужие вопросы, но и задает свои — от разговорных шаблонов («Как у тебя дела?» — «Отлично, а как у Вас?») до уточнения порученного ему задания. Особо стоит отметить, что если пользователь его перебивает, то чат-бот тут же замолкает и слушает новую, обращенную ему, информацию.
В-третьих, GPT-4o отвечает очень быстро — задержка составляет в среднем 320 мс, как у человека. Для сравнения, со времени релиза голосового режима в сентябре прошлого года, средняя задержка составляла 2.8 с у GPT-3.5 и 5.4 с у GPT-4 (вероятно при медленном Интернете задержка будет значительно больше).
Наконец, в-четвертых, GPT-4o хорошо анализирует визуальную информацию — будь то увиденное в камеру смартфона («Опиши что ты видишь») или изображение на дисплее («Объясни решение этой задачи»).
Качество и скорость GPT-4o улучшились за счет по-настоящему мультимодальной обработке запросов пользователя. В прежних версиях были задействованы три отдельные модели: одна распознавала аудио и переводила его в текст, другая обрабатывала его, третья озвучивала ответ. В результате чат-бот не понимал эмоциональный настрой своего собеседника, не мог различать разных собеседников, не слышал фоновый шум. Объединение всех этих модальностей в рамках единой модели позволило значительно сократить задержку ответа и повысить его качество. В то же время в анонсе GPT-4o отмечается, что это первая такая модель, поэтому её возможности и ограничения на стадии изучения — о чем наглядно свидетельствует подборка неудачных ответов.
В анонсе сообщается, что «мы делаем GPT-4o доступным в бесплатном режиме, а также для пользователей Plus с 5-кратным увеличением лимита сообщений». И как раз сегодня, 16 мая, новая версия стала доступна бесплатным пользователям.
Если резюмировать, то голосовой ассистент, предтечей которого в конце 2022 года я назвал запущенный тогда ChatGPT, уже появился. Он по-прежнему не дотягивает до человеческого интеллекта в широком смысле (хотя и превосходит многих людей в решении отдельных задач), а в своей нынешней версии явно сыроват. Но ничего подобного мир до сих пор не видел, поэтому можно смело говорить об очередном прорыве в происходящей сейчас революции искусственного интеллекта.
Теперь перейдем к остальным интересным анонсам, сделанный весной 2024. Способность GPT-4o играть своим голосом, включая пение на разные голоса, напомнило про музыкальные сервисы, самым лучшим среди которых пожалуй является выпущенная в апреле бета-версия Udio. Подобно анонсированным ранее Suno и Sonauto, Udio умеет создавать на заданный текст песню практически в любом музыкальном жанре (опера, поп, рок, хэви-метал, кантри, джаз, блюз и другие). Я лично поэкспериментировал с этим сервисом и был очень впечатлен качеством исполнения. Надо полагать, что со временем подобные сервисы будут интегрированы в голосовые ассистенты наподобие GPT-4o.
В конце февраля Google DeepMind представила Genie, «первую генеративную интерактивную среду, обученную на основе немаркированных видеороликов из Интернета». Обучившись на 200 тыс 2D-игр, модель с 11 млрд параметров может превратить в простенькую игру загруженное в неё новое изображение или даже фотографию. Модель самостоятельно понимает какие элементы изображения должны оставаться неподвижными, а каким можно манипулировать в рамках игрового процесса. Как знать — может быть через какие-нибудь 10-15 лет аналогичной модели можно будет показать полнометражный кинофильм или даже сериал (например, как насчет «Игры престолов»?), и она самостоятельно создаст игру, которая во всех нюансах воспроизводит интерьеры, пейзажи, ролевые модели персонажей и возможные сюжетные линии из этой кинопостановки. Впрочем еще интереснее поручить генерацию всего этого какому-нибудь дальнему потомку Sora…
В апреле Microsoft представила VASA-1 — модель, которая как бы оживляет мимику и визуально озвучивает (по выбранной пользователем звуковой дорожке) заданное изображение или фотографию лица. Вот как это выглядит на примере знаменитой Моны Лизы (Джоконды) Леонардо да Винчи:
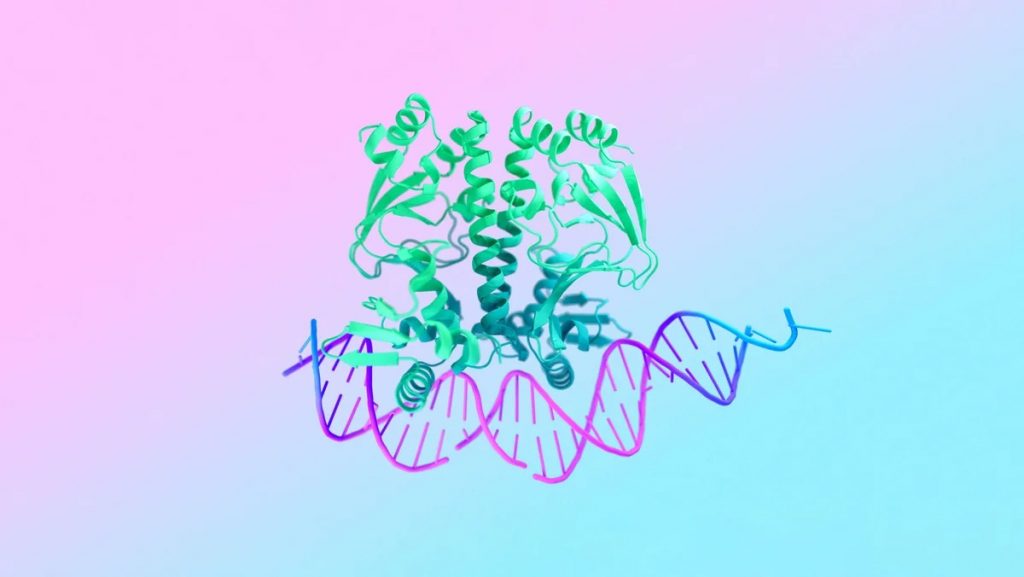
Если Genie c VASA-1 больше похожи на некую забаву, то выпущенная на днях AlphaFold 3 обещает в перспективе революционные открытия и изобретения в биологии и фармацевтике. Как пишут наши коллеги из N+1, «возможности новой модели включают предсказание структуры сложных комплексов, содержащих белки, нуклеиновые кислоты, низкомолекулярные соединения, ионы и модифицированные остатки. По данным разработчиков, AlphaFold 3 по точности предсказаний взаимодействий белков с лигандами на 50 процентов превосходит лучшие классические методы молекулярного докинга, включенные в тест PoseBusters, а также существующие модели на основе машинного обучения, такие как RoseTTAFold All-Atom и другие. При этом в некоторых практических аспектах точность модели может быть вдвое больше, чем у существующих методов. Isomorphic Labs уже сотрудничает с разными фармпроизводителями, чтобы использовать модель для дизайна новых лекарств. В отличие от AlphaFold 2 и RoseTTAFold, ученые не получат код AlphaFold 3 и не смогут запускать его у себя. Для работы с новой моделью Google DeepMind запустила AlphaFold Server, предназначенный только для некоммерческих исследований (и он не позволяет получить структуру белков, связанных с потенциальными лекарственными молекулами). Сервер работает намного быстрее, чем приложение AlphaFold2, доступ к нему предоставляется бесплатно, но ограничен квотой в десять предсказаний ежедневно.»
Помимо рабочих моделей следует упомянуть вышедшие весной 2024 теоретические работы. Самой главной среди них является, пожалуй, посвященная новой архитектуре KAN, призванной стать альтернативой многослойным перцептронам, лежащим в основе нынешних глубоких нейросетей. Идея KAN (Kolmogorov-Arnold Network) основывается на теореме Колмогорова-Арнольда (здесь и далее мы воспользовались объяснением на Телеграм-каналах gonzo-обзоры ML статей и Data Secrets), согласно которой непрерывная функция многих переменных может быть представлена суперпозицией непрерывных функций одной переменной. То есть как бы все функции многих переменных можно записать с использованием функций одной переменной и сложения. Если посмотреть на графы активаций, идущие через сеть, то в случае MLP они проходят через обучаемые веса (находятся на рёбрах графа) и попадают в фиксированные функции активации (находятся в узлах). В случае KAN они проходят через обучаемые функции активации на рёбрах (линейных весов как таковых уже нет), а в узлах просто суммируются. Если совсем коротко, то фиксированная для нейрона в многослойном перцептроне функция активации в KAN переезжает в изменяемую часть и становится обучаемой функцией вместо веса. Обучаемая функция активации позволяет гибко адаптироваться к разным данным и задачам, настраивая не только веса, но и саму функцию активации.
У новой архитектуры следующие плюсы:
- Точность и эффективность — авторы работы утверждают, что она значительно лучше, чем у обычных многослойных перцептронов. При этом сложность модели ниже, так как требуется меньше параметров.
- Интерпретируемость — благодаря обучаемости функции активации, модели становятся более прозрачными для понимания.
- Масштабируемость — более эффективное использование параметров и обучение функций позволяет сохранять обобщающую способность.
Главным недостатком нового подхода является гораздо более высокая потребность в вычислительных ресурсах — обучение функций активации требует дополнительных ресурсов. Каждая функция активации требует хранения своих параметров, что увеличивает потребление оперативной памяти и нагрузку на графические ускорители во время прямого распространения и обратного распространения ошибки.
И хотя будущее новой архитектуры пока довольно туманно, её заявленный недостаток представляется не таким уж большим — рост производительности не имеет принципиальных ограничений, в отличие от возможностей той или иной архитектуры. Весной 2024 было несколько интересных новостей, имеющих непосредственное отношение к производительности компьютеров, на которых обучаются ИИ-модели.
На следующий день после анонса GPT-4o прошла конференция Google I/O 2024, на которой, помимо прочего, представили Trillium — шестое поколение тензорных процессоров (TPU) компании. Пятое поколение представлено производительным TPU v5p и энергоэффективным (и гораздо менее производительным) TPU v5e, и Trillium сравнивается именно с последним — согласно Google, Trillium в 4.7 раз производительнее TPU v5e, и на сегодня является самым производительным и эффективным тензорным процессором. Новый чип станет доступным пользователям облачных сервисов Google в конце этого года.
В апреле на Intel Vision был представлен Intel Gaudi 3, чья производительность, по сравнению с предшественником (2022), выросла в 4 раза (BF16). Согласно производителю, по сравнению с графическим ускорителем Nvidia H100 (2022) ИИ-ускоритель Intel Gaudi 3 до полутора раз быстрее в обучении и инференсе как небольших, так и крупных моделей. По сравнению с Nvidia H200 (анонсирован в конце 2023) скорость инференса (работы уже обученной модели) у Intel Gaudi 3 выше на 30%.

Но пожалуй самой интересной «железной» новинкой весны 2024 стал созданный Intel нейроморфный компьютер Hala Point. Самая большая в мире на сегодня искусственная нейроморфная система содержит 1,152 процессоров Loihi 2 (на базе техпроцесса Intel 4) со 140,544 ядрами, и способна воспроизводить до 1.15 млрд нейронов с 128 млрд синаптических связей. Производительность компьютера достигает 240 трлн нейронных операций в секунду, 380 трлн синаптических операций в секунду и 20 квадриллионов (1015) 8-битовых операций в секунду (20 POPS), с энергоэффективность 15 трлн операций в секунду (TOPS) на 1 Вт. Компьютер будет работать в Сандийских национальных лабораториях (одна из шестнадцати национальных лабораторий Министерства энергетики США) над решением научных вычислительных задач в области физики устройств, компьютерной архитектуры, информатики и вычислительной техники.
Ну и наконец недавно стало известно, что суперкомпьютер Aurora достиг производительности 10.6 экзафлопс в ИИ-операциях, что на сегодня является абсолютным рекордом.
Впрочем, для обучения моделей искусственного интеллекта используются другие суперкомпьютеры и дата-центры. Одним из них, по данным ресурса The Information, станет Stargate, запуск которого компаниями Microsoft и OpenAI запланирован к 2028 году. Производительность компьютера неизвестна, зато сообщаются энергопотребление (несколько гигаватт, вероятно требующих отдельной атомной электростанции) и стоимость — больше $115 млрд.
То, что стоимость обучения моделей искусственного интеллекта растет в геометрической прогрессии, уже вполне очевидно. В опубликованном недавно Artificial Intelligence Index Report 2024 приводится такая динамика:
| Модель | Выпуск | Компания | Стоимость обучения |
| Трансформер | 2017 | $900 | |
| BERT | 2018 | $3.3 тыс | |
| RoBERTa | 2019 | Meta | $160 тыс |
| GPT-3 | 2020 | OpenAI | $4.3 млн |
| LaMDA | 2021 | $1.3 млн | |
| PaLM | 2022 | $12.4 млн | |
| GPT-4 | 2023 | OpenAI | $78.4 млн |
| LLama 2 | 2023 | Meta | $3.9 млн |
| Gemini Ultra | 2023 | $191.4 млн |
При этом обучение AlexNet (2012) потребовало производительности в 470 петафлопс, первой трансформерной модели (Google, 2017) — 7.4 тыс петафлопс, Gemini Ultra (Google, 2023) — 50 млрд петафлопс.
А в апрельском интервью Дарио Амодей, соучредитель и генеральным директором Anthropic (разработавшей одного из главных конкурентов ChatGPT, Claude) сделал следующий прогноз:
Модели, которые сейчас проходят обучение и которые появятся в разное время в конце этого или начале следующего года, по стоимости приближаются к 1 миллиарду долларов. Так что это уже происходит. А в 2025 и 2026 годах, я думаю, мы приблизимся к 5 или 10 миллиардам долларов.
В вышеупомянутом Artificial Intelligence Index Report 2024 приводятся и другие интересные факты:
- В 2023 во всем мире было выпущено 149 базовых (Foundation) моделей, в т.ч.: открытых — 98 (65.8%), частично открытых — 23 (15.4%), закрытых — 28 (18.8%);
- В 2023 из 149 выпущенных базовых моделей на США приходится 109, Китай — 20, Великобританию — 8, ОАЭ — 4, Канаду — 3. На Сингапур, Израиль, Германию и Финляндию — по 2, на Тайвань, Швейцарию, Швецию, Испанию и Францию — по 1;
- В 2023 из 149 базовых моделей бизнес выпустил 108 (72.5%), академические (научно-образовательные) организации — 28 (18.8%), совместно (бизнес и академические) — 9, правительственные организации — 4;
- В 2023 больше всего базовые модели из бизнеса выпустили Google (18), Meta (11) и Microsoft (9), из академических организаций — Калифорнийский университет (3);
- С 2019 по 2023 года больше всего базовые модели выпустили Google (40), OpenAI (20), Meta (19), Microsoft (18) и DeepMind (15);
- Общие инвестиции в ИИ за 2023 составили $189.16 млрд — против $234 млрд в 2022 и $337.4 млрд в 2021;
- В 2023 было зарегистрировано 1,812 ИИ-компаний;
- Количество выданных патентов, связанных с ИИ, с 2021 по 2022 выросло на 62.7%, по сравнению с 2010 — более чем в 31 раз. Из выданных в 2022 патентов 61.1% приходится на Китай, 20.9% — на США;
- По сравнению с 2021 количество научных публикаций на тему ИИ в 2022 почти не изменилось, а по сравнению с 2010 выросло почти в три раза, с 88 тыс до 240 тыс. В 2022 81.1% публикаций пришлось на научно-образовательные учреждения, 7.89% — на бизнес, 6.97% — правительственные структуры;
- В бенчмарках закрытые модели превосходят опенсорсные на 24.2%;
- В бенчмарке на понимание естественного языка MMLU на начало 2024 года Gemini Ultra (Google) достигла человеческого уровня (90%) — против 75% в 2022 и 32% в 2019 (лучшие результаты на то время);
- В одном из бенчмарков на правдивость, т.е. устойчивость к т.н. галлюцинациям, TruthfulQA, лучший результат показала GPT-4 (2024) — 59%, против менее 30% у GPT-2 (2021);
- В бенчмарке по программированию HumanEval GPT-4 (AgentCoder) набирает 96.3% против 64.1% в 2021. В гораздо более требовательном бенчмарке (SWE) лучший результат в 2023 — 4.8% (Claude 2). На сегодня лучший результат составляет 12% (SWE-агент на базе GPT-4) и 14% (Devin);
- В бенчмарке на понимание и рассуждение MMMU лучший результат в январе 2024 составил 59.4% (Gemini Ultra) — против 82.6% у человека. А вот как способность на понимание и рассуждение распределилась по различным областям знаний:
| Лучший результат ИИ на начало 2024 | Человек | |
| Искусство и дизайн | 51.4% | 84.2% |
| Бизнес | 59.3% | 86% |
| Наука | 54.7% | 84.7% |
| Здоровье и медицина | 67.3% | 78.8% |
| Гуманитарные и социальные науки | 78.3% | 85% |
| Технологии и инженерия | 47.1% | 79.1% |
- В другом (очевидно, менее требовательном) бенчмарке на рассуждения, GPQA, включающем 448 сложных вопроса на разные темы, GPT-4 набрал 41% — против 34% у человека-неэксперта и 65% у человека-эксперта;
- В бенчмарке на отгадывание пазлов ConceptARC, GPT-4 набрал 69% против 95% у человека;
- В математическом бенчмарке GSM8K (8 тыс задач из школьной программы) GPT-4 (Code Interpreter) набрал 97% — против 92.6% в 2023 и 66.6% в 2022;
- В другом математическом бенчмарке, MATH, GPT-4 показал еще более выдающиеся успехи — 84.3% в 2023 против 6.9% в 2021;
- В рассуждениях на морально-этические темы GPT-4 в 2023 набирал 42% — против 32% в 2022 и 27% в 2021 у его предшественников;
- В бенчмарке MedQA медицинская модель GPT-4 Medprompt в 2023 достигла точности в 90.2% — против 67.6% в 2022. По сравнению с 2019 точность выросла почти втрое.

Будущее искусственного интеллекта сегодня определяют в основном две компании — OpenAI (получающая щедрые инвестиции от Microsoft) и Google DeepMind — подразделение компании Alphabet, созданное на базе приобретенного ею в 2014 британского стартапа. Что, конечно, не отменяет вероятных сюрпризов от вышеупомянутой Anthropic, Meta (где работает один их ведущих в мире специалистов по ИИ, Ян Лекун) или даже какого-нибудь небольшого стартапа (который возможно возглавит уволившийся из OpenAI Илья Суцкевер). Как мы уже говорили, на следующий день после анонса GPT-4o прошла конференция Google I/O 2024, и несмотря на затянутость и несколько натуженный акцент на новомодном направлении, на нем были свои интересные анонсы:
- Контекстное окно Gemini 1.5 Pro расширено до 2 млн (для разработчиков в режиме тестирования);
- Gemini 1.5 Flash — облегченная и упрощенная версия Gemini;
- Проект Astra — условно, глаза Gemini, позволяющие понимать то, что видит камера вашего устройства;
- Veo — модель генерации минутных видеороликов по текстовому описанию (аналог Sora);
- Imagen 3 — их лучшая, как заявляют в Google, модель генерации изображений;
- Music AI Sandbox — музыкальный инструментарий.
Сроки релиза Gemini 1.5 Ultra по-прежнему не сообщаются, поэтому на сегодня лидером остается компания OpenAI и её GPT-4o. И есть все основания считать, что GPT-5 (который ожидается в конце текущего или начале следующего года) нас удивит. На это указывает сразу несколько обстоятельств:
- В недавнем интервью возглавляющий OpenAI Сэм Олтмен заявил, что GPT-4 — «самая глупая модель, которую кому-либо из вас когда-либо придется использовать снова»;
- Сэму Олтмену вторит другой топ-менеджер компании, главный операционный директор Брэд Лайткеп (Brad Lightcap): «Через год системы, которыми мы пользуемся сегодня (включая GPT-4), покажутся смехотворно плохими»;
- На презентации GPT-4o под аккомпанемент слов Миры Мурати, технического директора OpenAI, что компания заботиться не только о бесплатных пользователях (получивших доступ к новой модели), но и о следующем рубеже — и поэтому скоро состоится очередной большой анонс, на экране студии на доли секунды появилась надпись «Frontier models coming soon» (Скоро появятся передовые модели). Чтобы понять о чем идет речь, следует обратиться к определению frontier models, которое сформулировал консорциум Microsoft, Anthropic, Google и OpenAI (Frontier Model Forum):
Форум определяет передовые модели как крупномасштабные модели машинного обучения, которые превосходят возможности наиболее продвинутых существующих моделей и могут выполнять широкий спектр задач.
Не будет преувеличением сказать, что речь идет о промежуточном этапе на пути к созданию AGI, т.н. сильного интеллекта, способного самостоятельно выполнять любую посильную для человека интеллектуальную работу.
Что касается непосредственно AGI, то оценки сроков его создания варьируют от нескольких месяцев (да, есть и такие смелые прогнозы) до нескольких десятилетий (идея, что создание искусственного разума в принципе невозможно, на сегодня является маргинальной). Во вчерашнем интервью Джон Шульман, со-основатель и один из ведущих специалистов всё той же OpenAI, на вопрос когда ИИ сможет его заменить на работе, предположил, что это может произойти уже через пять лет. Его босс, Сэм Олтман, в конце прошлого года сделал аналогичный прогноз: «AGI станет реальностью через пять лет, плюс-минус, может быть, чуть дольше.» Илон Маск (обещавший, что полноценный автопилот технически будет готов уже к концу 2020 года) в апреле и вовсе предположил, что ИИ станет умнее любого человека примерно в конце следующего года. Более осторожный прогноз в отношении ASI, искусственного сверхразума, примерно тогда же сделал один из отцов-основателей нынешней ИИ-революции Джеффри Хинтон: [искусственный] сверхразум появится через 5-20 лет (2029-2044) с вероятностью 50%. В любом случае ближайшие годы обещают быть очень интересными.