Microsoft сделала шаг к созданию следующего поколения больших и многозадачных моделей искусственного интеллекта

Позавчера Microsoft объявила о создании суперкомпьютера, который входит в пятерку самых производительных в мире (из чего следует, что его пиковое и максимальное быстродействия превышают 23.5 и 38.7 петафлопс соответственно). Суперкомпьютер создан на облачной платформе Microsoft Azure, охватывает 285 тыс процессоров и 10 тыс графических ускорителей. Скорость соединения между его графическими серверами составляет 400 Гбит/с. Суперкомпьютер Microsoft спроектирован в сотрудничестве и для исключительного использования OpenAI, созданного в 2015 году некоммерческого центра по исследованию искусственного интеллекта.
Как заявляет Microsoft, это первый шаг в направлении создания следующего поколения очень больших моделей ИИ и инфраструктуры, необходимой для их обучения — в качестве платформы для других организаций и разработчиков. А большие модели ИИ имеют по меньшей два больших преимущества.
Во-первых, они позволяют тренировать системы с большим количеством параметров (каждый из которых образуется уникальной связью между нейронами). Созданная в 2015 остаточная нейросеть ResNet (снизившая процент ошибок распознавания изображений ImageNet до 3,57%) состояла из 152 слоев и 60 млн параметров. С тех пор число параметров нейросетей стремительно росло, и в нынешней Turing-NLG оно достигает уже 17 млрд.
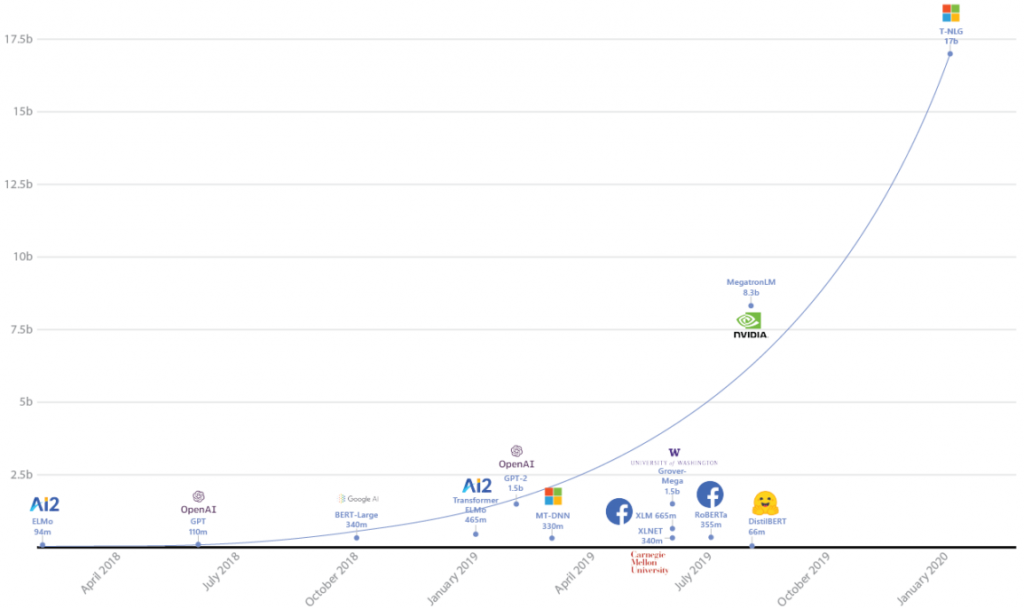
Эта языковая модель выполняет задачи, близкие к одной из самых ключевых проблем искусственного интеллекта — осмыслению текста. Обучившись на миллиардах страниц текста из Интернета (статей Википедии, книг, руководств пользователя и т.д.), она умеет создавать краткие аннотации к большим текстам, отвечать на вопросы по тексту и заполнять пропущенные слова исходя из общего контекста.
Во-вторых, с увеличением числа параметров появляется реальная возможность для создания многозадачных моделей ИИ, способных одновременно обучаться группе взаимосвязанных задач. Например, наравне с упомянутым выше созданием аннотаций к большим текстам, такую модель можно обучить модерации чатов и даже написанию кода на базе открытых исходников GitHub.
Также Microsoft изучает перспективу применения крупномасштабных моделей ИИ для обучения созданию семантического (текстового) описания изображений. В апреле компания поделилась моделью Oscar, обученной на 6.5 млн пар текст-изображение.
Этим разработки Microsoft в области ИИ не исчерпываются. В феврале она выпустила DeepSpeed — библиотеку для PyTorch, позволяющую оптимизировать процесс обучения глубоких нейросетей. А уже позавчера вышла её обновленная версия, использование которой позволяет обучать модели в 10 раз быстрее, при этом их размер может быть увеличен в 15 раз (по сравнению с неиспользованием DeepSpeed). Одновременно с новой версией DeepSpeed вышло 2-е поколение ZeRO, технологии оптимизации памяти при тренировке нейросетей (была анонсирована в феврале вместе с DeepSpeed). В свою очередь ZeRO-2 позволяет обучать модели с количеством параметров до 170 млрд, и делать это в 10 раз быстрее (по сравнению с имеющимися на сегодня технологиями).
Все это позволяет думать, что аппаратные и программные инструменты создания систем искусственного интеллекта выходят на новый уровень. Помимо Microsoft c OpenAI, большие усилия в этом направлении прикладывают Google, IBM, Amazon, Facebook и другие гиганты IT-индустрии.