Графический ускоритель H100, суперкомпьютер DGX H100, процессор Grace Hopper и многое другое: главные анонсы Nvidia на GTC 2022

На днях в рамках конференции GTC 2022 Nvidia представила очередное обновление экосистемы своих продуктов. Краеугольным камнем её аппаратной части стало очередное поколение графических ускорителей для задач искусственного интеллекта — Nvidia H100. Вот как выглядят характеристики новинки и её предшественников:
| H100 | A100 | Tesla V100 | |
| Дата анонса | март 2022 | май 2020 | май 2017 |
| Интерфейс | SXM5 | SXM4 | SXM2/SXM3 |
| Техпроцесс | TSMC 4 нм | TSMC 7 нм | TSMC 12 нм |
| Площадь кристалла | 814 мм2 | 826 мм2 | 815 мм2 |
| Кол-во транзисторов | 80 млрд | 54 млрд | 21 млрд |
| Архитектура | Hopper | Ampere | Volta |
| ГПУ | GH100 | GA100 | GV100 |
| Кол-во ядер CUDA (FP32) | 16,896 из 18,4321 | 6,912 из 8,1922 | 5,120 |
| Кол-во тензорных ядер | 528 из 5761 | 432 из 5122 | 640 |
| Кол-во текстурных блоков | 528 из 5761 | 432 из 5122 | 320 |
| Частота повышенная (boost) | ? | 1410 МГц | 1530 МГц |
| Память | 80 из 96 Гб HBM31 | 40 Гб HBM2e | 16/32 Гб HBM2 |
| Разрядность памяти | 5120-бит | 5120-бит | 4096-бит |
| Пропускная способность памяти | 3 Тб/с | 2 Тб/с | 900 Гб/с |
| Регистр | 33 Мб | 27 Мб | 20 Мб |
| Кэш L1 | 256 Кб / SM | 192 Кб / SM | 96 Кб / SM |
| Кэш L2 | 50 из 60 Мб1 | 40 Мб Кб | 6 Мб |
| TDP | 700 Вт | 400 Вт | 250 Вт |
| Интерфейс с другими графическими ускорителями (пропускная способность в ОДНУ сторону) | NVLink 4 (450 Гб/с) PCIe 5 (64 Гб/с) | NVLink 3 (300 Гб/с) PCIe 4 (32 Гб/с) | NVLink 2 (150 Гб/с) PCIe 3 (16 Гб/с) |
1 в H100 заблокированы 12 из 144 SM (в PCIe-версии — 30 из 144 SM), правда в другом месте документации вместо 16,896 приводится 15,872 (SXM5) и 14,592 (PCIe)
2 в A100 заблокированы 20 из 128 SM
А вот как выглядит производительность (в скобках — в тензорных вычислениях на разреженных, т.е. с преимущественно нулевыми элементами, матрицах) H100 по предварительным оценкам Nvidia:
| H100 | A100 | Tesla V100 | |
| FP64 | 30 TFLOPS | 9.7 TFLOPS | 7.8 TFLOPS |
| FP32 | 60 TFLOPS | 19.5 TFLOPS | 15.7 TFLOPS |
| FP16 | 120 TFLOPS | 78 TFLOPS | 31.4 TFLOPS |
| INT8 | 2000 (4000) TOPS | (624) TOPS | 62 TOPS |
Динамика роста производительности конечно впечатляет: по сравнению с поколением 2020 года она выросла в три раза. В то же время в операциях с плавающей точкой двойной точности до быстродействия прошлогоднего AMD Instinct MI250x Nvidia H100 все равно не дотягивает — у того 48 TFLOPS (FP64).

Nvidia H100 стал первым графическим ускорителем с поддержкой памяти стандарта HBM3, а также интерфейсов PCIe 5 и NVLink 4. Последний разработан непосредственно Nvidia и в 7 раз превосходит PCIe 5 по пропускной способности — что играет ключевую роль при масштабировании в более крупные вычислительные кластеры:
| DGX H100 | DGX A100 | DGX-2 | DGX-1 | |
| Дата анонса | март 2022 | май 2020 | март 2018 | май 2017 |
| Цена | ? | $200 тыс | $400 тыс | $150 тыс |
| Энергопотребление | 10.2 кВт | 6.5 кВт | 10 кВт | 3.5 кВт |
| Вес | ? | 143 кг | 159 кг | 61 кг |
| Процессоры | 2x ? | 2x AMD Rome 7742 | 2x Intel Xeon Platinum | 2x Intel Xeon E5-2698 v4 |
| Графические ускорители | 8x H100 80 Гб HBM3 | 8x A100 40 Гб HBM2 | 16x Tesla V100 32 Гб HBM2 | 8x Tesla V100 16 Гб HBM2 |
| Оперативная память | 2 Тб | 1 Тб | до 1.5 Тб DDR4 | до 0.5 Тб DDR4 |
| Видеопамять | 640 Гб HBM3 (8 x 80 Гб) | 320 Гб HBM2 (8 x 40 Гб) | 512 Гб HBM2 (16 x 32 Гб) | 256 Гб HBM (8 x 32 Гб) |
| Постоянная память (SSD) | 30 Тб NVMe | 15 Тб NVMe 4 | 30 Тб NVMe | 4 x 1.92 Тб NVMe |
| Производительность (тензорная) | 32 петафлопс | 5 петафлопс | 2 петафлопс | 1 петафлопс |
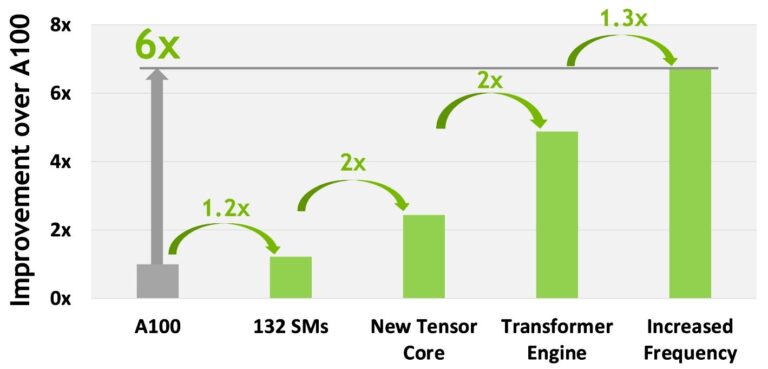
Здесь мы видим экспоненциальный рост тензорной производительности: с 1 до 32 петафлопс за пять лет. Рост производительности DGX H100 относительно DGX A100 соответствует заявленным Nvidia данным по H100 vs A100:
- 1.2x — за счет увеличения числа SM (потоковых мультипроцессоров)
- 2x — за счет увеличения числа новых тензорных ядер
- 2x — за счет оптимизация для трансформеров
- 1.3x — за счет рост тактовой частоты.
В свою очередь суперкомпьютеры DGX H100 могут масштабироваться в кластеры из 20-140 систем с тензорной производительностью 100-700 петафлопс.

Nvidia позиционирует H100 и собранные на его основе системы прежде всего для задач искусственного интеллекта — в частности, тренировки трансформеров. Тензорные ядра (4-е поколение) графического ускорителя поддерживают операции с точностью FP16, которой достаточно в большинстве трансформеров. По сравнению с A100 ускорение обучения обещано до 9 раз, а инференса (вывода данных из модели) — до 30 раз. Алгоритм Смита-Ватермана (применяется для выявления сходных участков двух нуклеотидных или белковых последовательностей) выполняется до 7 раз быстрее.
В числе прочих оптимизаций — поддержка инструкций динамического программирования, впервые среди архитектур Nvidia. Динамическое программирование — это, по определению Википедии, способ решения сложных задач путём разбиения их на более простые подзадачи. Что особенно актуально в планировании маршрута, науке о данных, робототехнике, биологии. Здесь ожидается 7-кратный рост быстродействия по сравнению с предшественником.
Поставки систем на базе графического ускорителя Nvidia H100 запланированы на 3 кв 2022, цены не сообщаются.

Несмотря на комплектацию суперкомпьютера DGX H100 парой неназванных x86-процессоров и запрет на покупку компании ARM, Nvidia продолжает разработку собственных процессоров на базе архитектуры ARM. Как уже рассказывал Gadgets News, почти год назад компания анонсировала серверный процессор Grace, названный в честь американской ученой Грейс Хоппер (как и новейшая архитектура графических ускорителей Hopper). На нынешнем мероприятии стали известны дополнительные подробности. Процессор имеет 144-ядерную конфигурацию и чиплетную компоновку — он состоит из двух 72-ядерных чипов, соединенных интерфейсом NVLink. Согласно Nvidia, в бенчмарке SPECrate_2017_int_base её процессор в 1.5 раза производительнее пары 64-ядерных AMD Rome 7742 (которым оснащен DGX A100) и в 2 раза энергоэффективнее современных серверных процессоров. Он будет работать на платформе N2 Perseus, имеющей поддержку PCIe Gen 5.0, DDR5, HBM3, CCIX 2.0 и CXL 2.0.
Само собой напрашивается сочетание процессора Grace и графического ускорителя Hopper — и таким сочетанием станет новый супер-процессор Grace Hopper (см. фото сверху). Это 72-ядерный ЦПУ-чип Grace, посредством всё того же интерфейса NVLink соединенный с ГПУ-чипом Hopper. Какая у того конфигурация пока неизвестно (скорее всего это GH100 от графического ускорителя H100).
Поставки Nvidia Grace запланированы на начало следующего года.

Не менее значительными были анонсы и программного обеспечения. В числе представленных инструментариев:
- Riva 2.0 — 2-е поколение SDK (комплекта для разработки программного обеспечения) для распознавания и генерации устной речи (в т.ч. на русском языке);
- Merlin 1.0 — библиотека с открытым кодом для ускорения работы рекомендательных систем на графических ускорителях Nvidia;
- Streamline — SDK, упрощающий применение визуальных эффектов в играх и других графических приложениях;
- Kickstart RT — SDK для добавления в игры и другие графические приложения более реалистичной трассировки лучей;
- Sionna — платформа для исследований в области сотовой связи 6-го поколения (6G);
- Обновления Triton, интерференсного программного обеспечения с открытым кодом;
- Обновление NeMo Megatron, платформы для обучения больших (до триллиона параметров) лингвистических моделей;
- Обновление Maxine, SDK для улучшения качества аудио и видео в телеконференциях;
- Обновление Omniverse, платформы для совместной работы в 3D-проектировании и моделировании — в реальном времени, с фотореализмом и воспроизведением законов физики, с маштабированием от единичной видеокарты до огромных вычислительных кластеров.
Nvidia напомнила и о других программных платформах: Modulus (моделирование физических процессов), Avatar (трехмерные аватары), Drive (беспилотные автомобили), Isaac (роботы-манипуляторы), Metropolis (автономные инфраструктуры), Holoscan (медицинские роботизированные инструменты), Rapids (набор открытых библиотек ПО и API для выполнения задач анализа данных полностью на графических ускорителях), cuOpt (складская логистика), Morpheus (кибер-безопасность), cuQuantum (ускорение моделирования квантовых схем), Aerial (исследования в области 5G), Monai (медицинская визуализация), Flare (вычислительная основа для федеративного обучения). В общей сложности были обновлены 60 SDK, разработанных Nvidia.
Во всей этой огромной экосистеме программных инструментов лично меня больше всего впечатлил SDK Maxine. На презентации было продемонстрировано, как во время видеосвязи речь участника телеконференции в режиме реального времени озвучивается на другом языке как если бы на нем говорил он сам — своим голосом и с соблюдением соответствующей мимики лица. Редактируется даже взгляд — если в оригинале участник телеконференции прикрыл глаза или косит куда-то в сторону, его двойник смотри прямо в камеру. Выглядит это как настоящая фантастика, и пока не вполне ясно насколько этот инструментарий готов к применению на практике. Но даже если это произойдет лишь через несколько лет, в дистанционном общении людей это произведет настоящую революцию.
Большое будущее видится и у Omniverse — мощного инструментария для создания виртуальных миров, на которые, в частности, делает ставку компания Meta (Facebook). Но пожалуй главное значение для мировой науки и промышленности будут иметь инструменты для цифровой биологии, геномики, фармацевтики, квантовых вычислений, искусственного интеллекта и робототехники — всего того, что определит научно-технологических прогресс человечества в ближайшие годы и десятилетия.
Про игры на GTC 2022 почти ничего не было, зато несколькими днями раннее Unity выложила на своем YouTube-канале ролик с очень реалистичной графикой — созданную на движке компании технодемку Enemies. В процессе её создания были задействованы система освещения Adaptive Probe Volume, инструменты реалистического рендеринга лица и волос (Digital Human и Hair), а также HDRP (High Definition Render Pipeline). Последний представляет собой процесс физического рендеринга, позволяющий использовать для разработки сцен параметры реального мира. Эта технология применялась и в технодемке The Heretic 3-летней давности.
Судя по заголовку ролика, рендеринг производился в режиме реального времени, но на какой платформе не сообщается. По слухам это Nvidia RTX 3090 (доступно в играх — 23 TFLOPS), но достоверных источников на этот счет я пока не нашел. Однако даже в этом случае в играх такая графика появится еще не скоро (не считая заранее отрисованных сцен). Самые массовые игровые платформы — это ПК начального и среднего уровня, PlayStation 5 и Xbox Series X, а также их предшественники. У игровых консолей последнего поколения производительность находится на уровне 10-12 TFLOPS, у предшественников — 4-6 TFLOPS. А согласно февральской статистике онлайн-магазина компьютерных игр Steam, самые распространенные видеокарты на игровых компьютерах это GTX 1060 (4.4 TFLOPS) — 8%, GTX 1650 (3 TFLOPS) и GTX 1050 Ti (2 TFLOPS) — по 6%, RTX 2060 (6.5 TFLOPS) — 5%, GTX 1050 (1.9 TFLOPS) и GTX 1660 Ti (5.4 TFLOPS) — по 3%.
Поэтому современные игры по-прежнему ориентированы на уровень производительности 4-6 TFLOPS, с перспективой повышения этой планки до 10-12 TFLOPS в ближайшие годы. Игры с кинематографической графикой, которые по силам видеокартам начиная разве что с 23 TFLOPS, скорее всего начнут выходить к середине жизненного цикла (около 7 лет) игровых консолей следующего поколения — т.е. где-то с 2030 года. Будем надеяться, что к тому времени разработчики и компьютерное железо осилят не только кинореалистичную мимику персонажей, но также их более интерактивное и правдоподобное взаимодействие с другими объектами.