Nvidia стала самой дорогой компанией мира, опередив Microsoft и Apple — но надолго ли? Несколько мыслей о перспективах достижения AGI при помощи имеющихся в современной индустрии подходов

Итак, начавшееся в начале прошлого года стремительное подорожание акций Nvidia достигло исторической отметки — теперь это самая дорогая в мире компания. На данный момент она оценивается фондовой биржей в $3.337 трлн, что немного превышает стоимость Microsoft ($3.317 трлн) и Apple ($3.286 трлн). Для сравнения, почти столько же ($3.2 трлн) стоят международные резервы Китая, занимающего первое место по этому показателю. С начала прошлого года акции Nvidia подорожали почти в 10 раз, а за последние пять лет — почти в 35 раз.
Своим грандиозным успехом Nvidia обязана компьютерным играм, научным вычислениям, майнингу криптовалют и конечно же начавшемуся в 2012 году (AlexNet) буму искусственного интеллекта. Основные вычисления в искусственных нейронных сетях сводятся к перемножению матриц, и благодаря параллельной работе множества простых процессоров (ядер) ГПУ справляются с этим лучше традиционных ЦПУ — особенно после добавления в них тензорных процессоров.
В 1-м квартале финансового года Nvidia достигла следующих показателей ($ млн):
| 1 кв 20241 | 1 кв 2023 | изменение | |
| Выручка | 26,044 | 7,192 | 3.6x |
| в т.ч. от: | |||
| — графических ускорителей и серверов для дата-центров | 22,563 | 4,284 | 5.3x |
| — игровых графических ускорителей | 2,647 | 2,240 | +18% |
| Чистая прибыль | 14,881 | 2,043 | 7.3x |
Как видно из этой таблицы, выручка от когда-то основного бизнеса Nvidia, игровых видеокарт, с прошлого года изменилась незначительно — тогда как выручка от продажи оборудования для дата-серверов взлетела более чем в пять раз. При этом бизнес компании стал еще более рентабельным — чистая прибыль увеличилась более чем в семь раз.
На фоне Nvidia финансовые результаты AMD (рыночная капитализация — $252 млрд) смотрятся значительно скромнее ($ млн):
| 1 кв 20241 | 1 кв 2023 | изменение | |
| Выручка | 5,473 | 5,353 | +2% |
| в т.ч. от: | |||
| — процессоров, графических ускорителей и прочего оборудования для дата-центров | 2,337 | 1,295 | +80% |
| — процессоров и APU для ПК и ноутбуков | 1,368 | 739 | +85% |
| — игровых графических ускорителей и SoC | 922 | 1,757 | -48% |
| — встроенных ЦПУ, ГПУ и т.д. | 846 | 1,562 | -46% |
| Чистая прибыль | 123 | (139) |
Происходящий сейчас бум искусственного интеллекта, в результате которого компании массово скупают графические ускорители Nvidia для своих дата-центров, вызывает среди специалистов неоднозначную реакцию. Ряд скептиков (например, Ян Лекун или его соотечественник Франсуа Шолле, создавший библиотеки глубокого обучения Keras в 2015 году) считает тупиковым направление больших языковых моделей. Именно их масштабирование требует для обучения все большего количество графических ускорителей. Если первая трансформерная модель потребовала восьми графических ускорителей Nvidia Tesla P100 (21.2 TFLOPS F16), то в следующем году компания Илона Маска xAI, по его словам, возможно запустит, для обучения своей модели, вычислительный кластер из около 300 тыс Nvidia B200 (2.2 PFLOPS FP16). Таким образом, с 2017 по 2025 производительность дата-центра для обучения ИИ вырастет почти в 4 млн раз. Количество параметров первого трансформера оценивается в 65 млн. Если предположить, что модель xAI в следующем году получит 2.6 трлн параметров, то производительность вычислительных кластеров растет примерно в 100 раз быстрее, чем размеры (количество параметров) моделей. Отчасти это может быть обусловлено мультимодальностью, а также технологией mixture of experts, когда модель включает в себя несколько блоков, специализирующихся на отдельных областях знаний.
Любопытно, что в мае со-основатель и глава OpenAI, Сэм Олтмен, высказал предположение, что в будущем люди будут получать не Безусловный базовый доход (Universal Basic Income), а Безусловные базовые вычисления (Universal Basic Compute) — часть доступа к гипотетической GPT-7, которой они смогут воспользоваться по своему усмотрению. Кстати, GPT-7 упомянул в этом примере сам Сэм Олтмен — возможно он считает, что искусственный интеллект человеческого уровня (AGI) будет достигнут в 7-м поколении GPT. Ведь ББД, который Олтмен предлагает заменить на ББВ, предполагает массовую безработицу, спровоцированную появлением AGI. Если так, то исходя из гипотетического релиза GPT-5 в 2025, GPT-6 в 2027, а GPT-7 в 2029, глава OpenAI допускает появление AGI уже к концу этого десятилетия. Что вполне согласуется с его сделанным в конце прошлого года прогнозом, что «AGI станет реальностью через пять лет, плюс-минус, может быть, чуть дольше».
Как уже рассказывал Gadgets News, ранее Сэм Олтмен заявил, что GPT-4 — «самая глупая модель, которую кому-либо из вас когда-либо придется использовать снова», а главный операционный директор OpenAI Брэд Лайткеп (Brad Lightcap) похвастал, что «через год системы, которыми мы пользуемся сегодня (включая GPT-4), покажутся смехотворно плохими». Правда, эти многообещающие высказывания фактически дезавуировала технический директор компании, Мира Мурати: «В лаборатории у нас есть эти мощные модели, и они не так уж далеко опережают то, к чему общественность имеет бесплатный доступ.»
Но главная интрига состоит не в том, как в OpenAI в действительности оценивают интеллект GPT-5, начало обучения которой недавно анонсировали в компании. Вышеупомянутый Франсуа Шолле считает, что по вине OpenAI вокруг больших языковых моделей (LLM) возник ажиотаж, и теперь «они высасывают кислород из комнаты — все только и делают, что учатся на LLM».
Если заглянуть в прошлое, например, в 2015 или 2016 год, то тогда людей, занимающихся ИИ, было в тысячу раз меньше. Но темпы прогресса были выше, потому что люди исследовали больше направлений. Мир казался более открытым. Можно было просто пойти и попробовать. Можно было придумать классную идею запуска, попробовать её и получить интересные результаты. Была такая энергетика. Сейчас же все занимаются примерно одним и тем же. Крупные лаборатории тоже пробовали свои силы в ARC (разработанном с его участием бенчмарке, который, по мнению Франсуа Шолле, может быть пройден только AGI), но, получив плохие результаты, ничего не публиковали. Люди публикуют только положительные результаты.
Именно в этом и состоит главная интрига: действительно ли в OpenAI игнорируют другие направления и сосредоточились исключительно на мультимодальных системах на базе больших языковых моделей? Скорее всего нет, но даже если это так, то на другие направления наверняка обращают внимание другие компании — те, где работают специалисты, которые скептически настроены в отношении больших языковых моделей. Помимо самого Франсуа Шолле, работающего в Google, можно отметить таких крупных специалистов как Демис Хассабис (Google DeepMind) и Ян Лекун (Meta). Но нельзя не согласиться, что успех LLM разогревает интерес к ним и отвлекает ресурсы от направлений, которые пока, что называется, не выстрелили. Тем более, что и Демис Хассабис считает целесообразным дальнейшее масштабирование моделей с нынешней архитектурой:
Я считаю, что для достижения AGI вам понадобится еще несколько инноваций, а также максимальный масштаб. Масштабирование не останавливается, мы не видим асимптоту или что-то в этом роде. Нам еще предстоит добиться успехов.
Если Ян Лекун и Франсуа Шолле правы, а Джеффри Хинтон и Илья Суцкевер ошибаются, то со временем дальнейшее развитие больших языковых моделей упрется в потолок — потому что закончились обучающие данные, и при этом увеличение количества параметров модели уже почти не улучшает её качество. Какое-то время прогресс, возможно, продолжится благодаря мультимодальному подходу — обучению на видеоархивах YouTube и сервисов потокового вещания (Netflix и другие). Причем не факт, что бенчмарк ARC-AGI, предложенный Франсуа Шолле в качестве критерия для AGI, будет пройден именно таким искусственным интеллектом, о котором Шолле мечтает — способным решать по-настоящему новые задачи, подобных которым не было в обучающем дата-сете. Вот как выглядит типичная задача из этого бенчмарка:
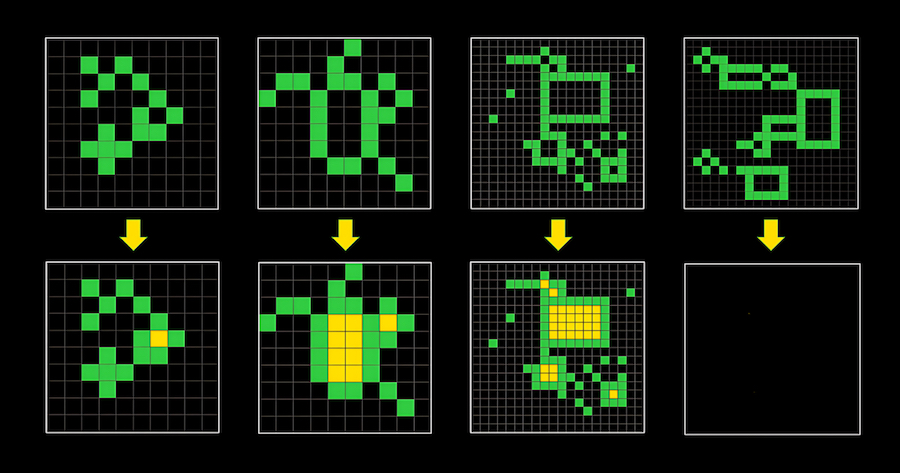
Среднестатистическому человеку она покажется элементарной — надо закрасить желтыми квадратиками пустующие замкнутые пространства. Но лучшая на сегодня мультимодальная система GPT-4o, которая многих впечатлила своей способностью к визуальному пониманию нашего мира, с ней не справилась. Лучший на сегодня результат среди моделей ИИ составляет 34% (MindsAI) — против 85% у среднего человека. А буквально вчера Райан Гринблатт из Redwood Research заявил, что за неделю научил языковую модель GPT-4o проходить этот бенчмарк с результатом 50%. Он применил достаточно известный подход — поручил GPT-4o генерировать 8 тыс программ, которые выдают результат по трем исходным примерам в тесте. Если результат для всех трех примеров правильный, то программа отбирается и генерирует ответ для четвертого примера (который и надо найти в процессе прохождения IQ-теста).
Если один человек за неделю улучшил результат в этом бенчмарке с 34% до 50%, то достижение 85% результата также представляется вполне реальным — но едва ли это тот интеллект, о котором говорит Франсуа Шолле. Допустим, что получив задание пройти такой бенчмарк, условный GPT-5 самостоятельно сгенерирует программу, которая выдаст нужный (судя по совпадению с предоставленными примерами) результат. Можно ли тогда считать GPT-5 разумным? А разумен ли человек, который из-за рассеянного внимания не способен пересчитать овец в стаде — но зато может умножить количество овец в длину стада на количество овец в ширину? А человек, который так часто сопоставлял визуальный образ стада с количеством овец в нем, что способен с первого взгляда определить количество овец в новом стаде?..
Свой ответ на этот вопрос еще в 1950 году дал Алан Тьюринг, по сути предложивший считать разумной машину, которая имитирует разум — безотносительно того, как она это делает. Согласно опубликованному в прошлом месяце исследованию, в этом тесте GPT-4 был признан человеком в 54%, его предшественник GPT-3.5 — в 50%, а написанная в 1966 года программа ELIZA — в 22% случаев. Результат GPT-4 все еще отстает от человеческого (в человеке узнали человека 67% его собеседников), но это вряд ли имеет значение — едва ли Тьюринг считал разумной машину, которая способна ввести своего собеседника в заблуждение расплывчатыми и уклончивыми ответами (с этой точки зрения ELIZA, обманувшая 22% собеседников, вполне разумна). Тест Тьюринга следует толковать сколь угодно широко — например, как совокупность любых тестов и бенчмарков (включая вышеупомянутый ARC-AGI), дистанционную учебу или работу на протяжении многих лет. Поэтому по-настоящему тест Тьюринга можно будет считать пройденным тогда, когда ИИ в ЛЮБОЙ интеллектуальной задаче продемонстрирует уровень человеческого интеллекта.
Что касается заявленной Франсуа Шолле отличительной способности человека решать новые задачи, то хотелось бы отметить одно обстоятельство. Дело в том, что вряд ли можно уверенно говорить о способности человека, даже очень умного, решать совершенно новые задачи. Простой пример — распознавание людей другой национальности или тем более расы — первое время они все на одно лицо. И только пожив среди них какое-то время, человек начинает более-менее различать их между собой. Или возьмем тест из бенчмарка ARC-AGI — решит ли его африканский бушмен, ведущий первобытный образ жизни? Низкий уровень IQ представителей первобытных племен обусловлен не их отставанием в умственном развитии, а отсутствием опыта в решении абстрактных задач (как правило составляющих основу IQ-тестов). Соответственно среднестатистический представитель городской цивилизации, оказавшись на дикой природе, по сравнению с бушменом проявит себя непроходимым тупицей. Так может Франсуа Шолле недооценивает размеры нашего собственного обучающего «дата-сета», когда мы успешно решаем якобы новые для нас задачи?..
В любом случае нельзя не согласиться с Шолле, что большими языковыми моделями возможные подходы к созданию AGI не исчерпываются. Среди потенциально перспективных направлений можно назвать, например, жидкие и импульсные нейросети, а также представленную недавно архитектуру KAN, которая основывается на теореме Колмогорова-Арнольда и предлагается в качестве альтернативы традиционному перцептрону искусственных нейронных сетей. Если нынешнее направление ИИ упрется в потолок и наступит очередная зима искусственного интеллекта, то в поисках AGI разработчики обратятся к перспективным, но пока не слишком популярным идеям и концепциям — а возможно даже придумают новые. Но если не произойдет очередная революция, вроде трансформеров и GPT, то случится это не раньше, чем через несколько лет — пока масштабирование базовых (Foundation) моделей себя оправдывает. И значит акции Nvidia будут дорожать и дальше.