Еще одна попытка: Nvidia будет выпускать процессоры

Вчера на кухне Дженсена Хуанга состоялась большая презентация, на которой глава Nvidia рассказал о нескольких будущих продуктах компании. Главным среди них конечно стал серверный процессор Grace, названный в честь американской ученой Грейс Хоппер. В его основе лежит архитектура ARM — что вполне предсказуемо хотя бы с учетом намерений Nvidia приобрести одноименную британскую компанию (сделка до сих пор ожидает одобрения надзорных органов). В отличие от кастомных ядер Denver в мобильном процессоре Tegra K1, на это раз планируется использовать готовые ядра Neoverse. Релиз процессора запланирован на 2023 год, поэтому, принимая во внимание дорожную карту самой ARM, речь может идти о преемнике Poseidon и ARM v9. Последний был анонсирован в конце прошлого месяца и отличается следующим:
- Встроенная поддержка SVE2 — набора инструкций для выполнения векторных операций, особенно востребованных в машинном обучении. Аналог SVE2 в x86-процессорах Intel — AVX-512, который позволяет производить вычисления над векторами длиной до 512 бит. Тогда как в SVE/SVE2 векторный регистр может иметь длину от 128 до 2048 бит.
- Поддержка Realms — аппаратного контейнера, разработанного для защиты виртуальных машин и приложений. Он способен обеспечить полную изоляцию друг от друга каждой виртуальной машины и каждого отдельного приложения.
- Технология Total Compute — оптимизация, по сравнению с ARM v8 повышающая производительность на 30%.
Nvidia приписывает ядрам Neoverse производительность не ниже 300 баллов в бенчмарке SPECrate_2017_int_base. Этот результат серверного процессора 2023 года может показаться довольно скромным на фоне нынешнего EPYC Milan (382-424). Но главным преимуществом процессоров Nvidia станет огромная пропускная способность интерфейса с памятью, графическим ускорителем и другим процессором. Как уже рассказывал Gadgets News, пропускная способность новейшего PCIe 5.0 — 128 Гб/с. Эта цифра удвоится, но только с будущим релизом PCIe 6.0. Ответом на медлительность PCIe стал разработанный Nvidia стандарт NVLink, но процессоры Intel и AMD его не поддерживают. Более того, его поддержки не будет даже в POWER10 — процессоре IBM, с которой Nvidia сотрудничала и в свое время добилась включения поддержки NVLink в POWER9. Так вот в случае с процессором Grace обещается гораздо более высокая пропускная способность:
| Grace | AMD EPYC 2 | |
| ЦПУ-ЦПУ | 600 Гб/с (NVLink 4) | 304 Гб/с (Infinity Fabric 2) |
| ЦПУ-ГПУ | 900 Гб/с (NVLink 4) | ~64 Гб/с (PCIe 4 x16) |
| ЦПУ-ОЗУ (LPDDR5x) | 500 Гб/с |
Пропускная способность особенно актуальна в серверных вычислениях, и особенно — связанных с машинным обучением, где идет интенсивный обмен информацией между памятью и ЦПУ/ГПУ. Nvidia обещает, что по сравнению с системами на базе DGX A100 (4x ГПУ Nvidia A100, 1x 64-ядерное ЦПУ AMD EPYC 7742) скорость обучения модели естественного языка с 1 трлн параметров вырастет в 10 раз. При этом не утверждается, что для такого приращения производительности достаточно замены AMD EPYC 7742 на Nvidia Grace. Немногим понятнее другое сравнение. Согласно Nvidia, тренировка нейросети GPT-3 на суперкомпьютере Selene (где в качестве ЦПУ также используются AMD EPYC 7742) занимает 14 дней — при том, что в операциях машинного обучения это самый производительный в мире суперкомпьютер (2.8 экзафлопс). Nvidia заявляет, что благодаря использованию процессоров Grace это время сократится до 2 дней, но конфигурация такого суперкомпьютера также не уточняется. Подобные сравнения не слишком информативны, так что пока о реальной производительности процессоров Grace в операциях машинного обучения судить довольно сложно.
Grace стал по меньшей мере второй попыткой Nvidia войти на рынок процессоров — в этот раз серверных. В свое время Nvidia не оставляла попыток закрепиться за рынке мобильных чипов, и кульминацией этих попыток стал вышеупомянутый Tegra K1, анонсированный в начале 2014 года. Усилия Nvidia не увенчались успехом, и два с половиной года спустя компания заявила, что «мобильный рынок нам больше не интересен«. Впрочем, преемник Tegra K1, Tegra X1, и поныне используется в одной из самых успешных мобильных консолей, Nintendo Switch. И вот теперь Nvidia замахнулась на рынок серверных процессоров, где доминируют Intel и AMD. Это симметричный ответ на действия Intel, которая предприняла очередную попытку выйти на рынок графических ускорителей. Её Ponte Vecchio Xe-HPC предназначен как раз для серверных вычислений и будет использоваться в экзафлопсном суперкомпьютер Aurora. Своими заказчиками заручилась и Nvidia — процессоры Grace получат суперкомпьютеры Швейцарского национального суперкомпьютерного центра и Лос-Аламосской национальной лаборатории министерства энергетики США, запуск которых запланирован на 2023 год.
С учетом прошлогоднего анонса перехода компьютеров Apple на её собственные процессоры можно констатировать, что за последнее время ARM, безраздельно господствующий на мобильном рынке, начинает теснить x86 на рынках ПК и серверов. На последнем у ARM очень неплохие перспективы, поскольку процессоры с этой архитектурой отличает энергоэффективность. А она востребована не только в мобильных гаджетах, но и дата-центрах, потребляющих огромное количество электроэнергии. Поэтому если в абсолютной производительности лидируют такие процессоры как недавно анонсированные AMD EPYC 7763 ($7890) и Intel Xeon Platinum 8380 ($8099), то по энергоэффективности привлекательнее Amazon AWS Graviton2 и Fujitsu A64FX. Последний составил основу самого производительного из современных суперкомпьютеров, Fugaku.
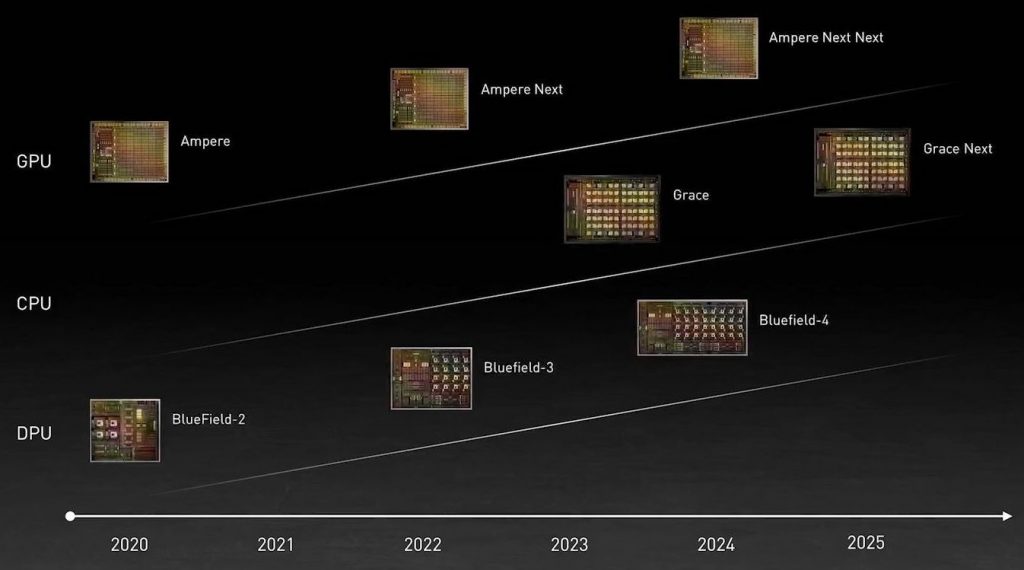
Что касается главного поприща Nvidia, графических ускорителей, то согласно показанной на презентации дорожной карте, преемник Ampere выйдет в следующем году, а следующее поколение — в 2024. Обратите внимание, что будущий процессор Nvidia назван именем, а не фамилией Грейс Хоппер. Это дает основание предполагать, что ко времени релиза Grace очередное поколение графических ускорителей компании может быть названо Hopper. В этом случае название связки серверных ЦПУ и ГПУ Nvidia совпадет с полным именем Грейс Хоппер.
В числе прочих анонсов Nvidia стоит упомянуть следующие:
- Серверные блоки обработки данных (DPU) BlueField-3 (16x Cortex-A78, 22 млрд транзисторов, 400 Гбит/с, 1.5 TOPS) и BlueField-4 (64 млрд транзисторов, 800 Гбит/с, 1000 TOPS), чей релиз запланирован на 2022 и 2024 годы соответственно;
- Младшие версии графического ускорителя A100 — A10 (31.2 TFLOPS FP32), A16 и A30 (10.3 TFLOPS FP32);
- Drive Atlan — процессор для беспилотных автомобилей производительностью 1 квадриллион (1000 трлн) TOPS, релиз запланирован на 2025 год. Для сравнения, анонсированный в 2017 Drive PX Pegasus имел производительность в 320 TOPS при энергопотреблении 500 Вт.