Volta GV100 vs Pascal GP100: что изменилось в топовом ГПУ Nvidia?

На проходящей в эти дни конференции Hot Chips 2017 Nvidia раскрыла некоторые подробности о ГПУ GV100, которым оснащен новейший и самый производительный графический ускоритель компании, Tesla V100. Кроме того, подробная информация была опубликована в т.н. Белой книге (Whitepaper), официальной документации, посвященной Tesla V100.
Внешне GV100 от своего предшественника GP100 практически не отличается: по углам кристалла расположены четыре блока памяти HBM2 по 4 Гб каждый, а по двум краям самого модуля — 16 индукторов и стабилизаторов напряжения.

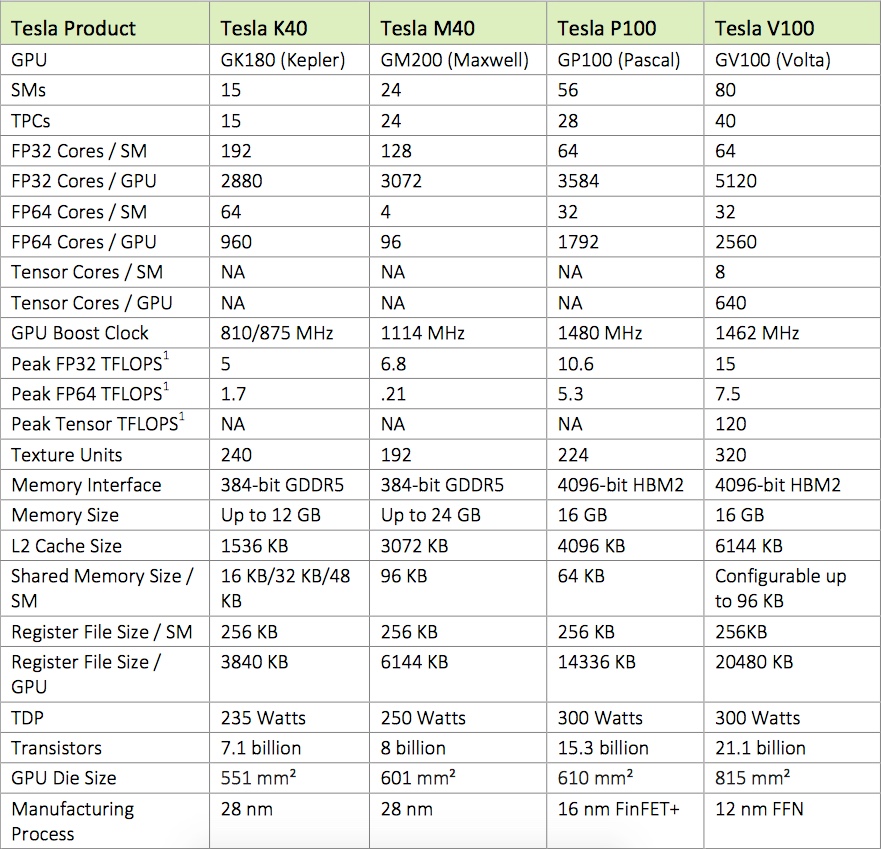
А вот внутреннее содержимое двух ГПУ отличается друг от друга весьма значительно. Их характеристики представлены в таблице ниже:
| Tesla V100 | Tesla P100 | |
| Дата анонса | май 2017 | апрель 2016 |
| Техпроцесс | TSMC 12нм | TSMC 16нм |
| Архитектура | Volta | Pascal |
| ГПУ | GV100 | GP100 |
| Площадь ГПУ | 815 мм2 | 610 мм2 |
| Кол-во транзисторов | 21 млрд | 15.3 млрд |
| Кол-во ядер INT32 | 5,120 | — 1 |
| Кол-во ядер FP32 | 5,120 | 3,584 |
| Кол-во ядер FP64 | 2,560 | 1,792 |
| Повышенная (boost) частота ГПУ | 1462 МГц | 1480 МГц |
| Производительность (FP32 / FP64) | 15 / 7.5 терафлопс | 10.6 / 5.3 терафлопс |
| Кол-во TMU | 320 | 224 |
| Кол-во тензорных ядер | 640 | — |
| Производительность (машинное обучение — тренировка) | 120 терафлопс | 10 терафлопс |
| Производительность (машинное обучение — принятие решений) | 120 терафлопс | 21 терафлопс |
| Память | 16 Гб HBM2 (4096-битная) | |
| Пропускная способность памяти | 900 Гб/с | 720 Гб/с |
| Кэш L2 | 6 Мб | 4 Мб |
| Кэш L1 | 10 Мб | 1.3 Мб |
| Регистровый файл | 20 Мб | 14 Мб |
| Пропускная способность NVLink 2.0 | 300 Гб/с | 160 Гб/с |
| TDP | 300 Вт | |
1 В ГПУ GP100 ядра FP32 выполняют либо целочисленные 32-разрядные операции (INT32), либо 32-разрядные операции с плавающей точкой (FP32). Тогда как в GV100 имеются ядра отдельно для целочисленных операций и операций с плавающей точкой, поэтому они могут выполнятся одновременно.
Данные в таблице приведены за вычетом блоков SM (4 из 84 у GV100, 4 из 60 у GP100), заблокированных для достижения одинакового количества ядер на случай частичного дефекта у некоторых кристаллов. Производительность указана на повышенной (boost) частоте.
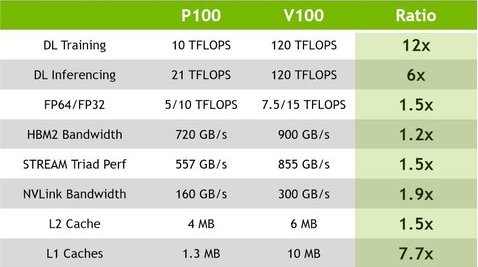
Оценить прогресс в более долгосрочной ретроспективе, с 2013 года (Tesla K40) позволит следующая таблица:
Таким образом, спустя год после анонса Tesla P100 вышел графический ускоритель с 1.5-кратным приростом производительности в операциях с плавающей точкой и 6-12 приростом производительности в операциях глубокого обучения.

Столь внушительному результату GV100 обязано 640 ядрам, специализирующимся на тензорных вычислениях — линейном преобразовании элементов одного линейного пространства в элементы другого (примером которого является перемножение матриц). К слову, свой первый тензорный процессор Google представила еще в 2015 году, а его второе поколение в операциях машинного обучения достигло производительности 180 терафлопс (с точностью FP16).