Архитектура Denver: очередные подробности

Наши коллеги из AnandTech опубликовали обещанный три месяца назад обзор планшета Nexus 9, в котором сообщили новые интересные подробности об используемом в нем процессоре Nvidia Tegra K1 Denver (см. наш обзор архитектуры Denver, составленный по предыдущим материалам AnandTech).
Напомним, что чипсет Tegra K1, анонсированный в январе прошлого года, вышел в двух версиях: 32-разрядной, с ЦПУ из четырех ядер Cortex-A15 с тактовой частотой 2.3 ГГц, и 64-разрядной, с ЦПУ из двух ядер Denver с частотой 2.5 ГГц. Переход на новые ядра имел несколько явных преимуществ.

Во-первых, разумеется, сокращение количества ядер было компенсировано повышением их производительности. Как мы уже рассказывали, большинство приложений использует не более двух ядер, поэтому увеличение количества ядер при всем впечатлении, которое это производит на покупателей, редко когда приводит к пропорциональному росту производительности. С точки зрения трудностей распараллеливания, эффективнее использовать два «толстых» ядра, чем восемь «тонких». Правильность выбора, который Nvidia сделала пять лет назад (когда компания впервые объявила о проекте Denver) подтверждается успехом Apple — в ЦПУ ее последних процессоров Apple A8 (iPhone 6) и Apple A8X (iPad Air 2) установлены два и три ядра соответственно. Apple и Nvidia стали единственными компаниями, использующими ЦПУ с «толстыми» 64-разрядными ядрами на базе новейшего стандарта ARMv8.
Во-вторых, используя вместо родных ARM-овских ядер собственные разработки, Nvidia экономит на роялти, выплачивая их ARM только за использование созданной компанией архитектуры, но не ее ядер.
В-третьих, в использовании собственных ядер есть и определенное маркетинговое преимущество. В то время как другие производители мобильных чипсетов, включая крупнейшего из них, Qualcomm, используют набор из одних и тех же ядер, Nvidia может предложить своим заказчикам нечто особенное — при условии, конечно, что ее чипсеты будут конкурентноспособными с точки зрения отсутствия ошибок и перегрева, адекватных производительности и цены.
Наконец, в-четвертых, процессоры с ядрами Denver могут использоваться не только в мобильном, но и в серверном сегменте, в рамках консорциума OpenPOWER (в котором, помимо Nvidia, участвуют также IBM, Google, Mellanox и Tyan).
Впрочем, использованием двух «толстых» ядер вместо четырех или восьми «тонких», отличие ЦПУ Denver от того же семейства ARM Cortex-Axx далеко не исчерпывается. Среди прочих особенностей в первую очередь необходимо упомянуть следующие:
- использование динамической оптимизации кода (Dynamic Code Optimization или DCO), о которой мы рассказывали в прошлом обзоре (и к которой вернемся ниже).
- последовательное выполнение инструкций, поступающих в исполнительные модули процессора.
Существует два принципа выполнения инструкций процессором: по порядку (in-order) и не по порядку (out-of-order). Во втором случае инструкции поступают в исполнительные блоки не в порядке следования, а по мере готовности их к исполнению. Тогда удается избежать простоя процессора в случаях, когда поступившей в исполнительный блок инструкции приходится ожидать своих операндов (данных, над которым выполняется инструкция). Однако реализация этого подхода на аппаратном уровне приводит к увеличение сложности, размеров и энергопотребления чипа. Так вот в процессоре Denver аппаратный механизм out-of-order не соблюдается. Это стало возможным благодаря упомянутой выше динамической оптимизации кода, а также 7-канальной суперскалярной архитектуре — за один такт процессора может выполняться до семи инструкций одновременно.
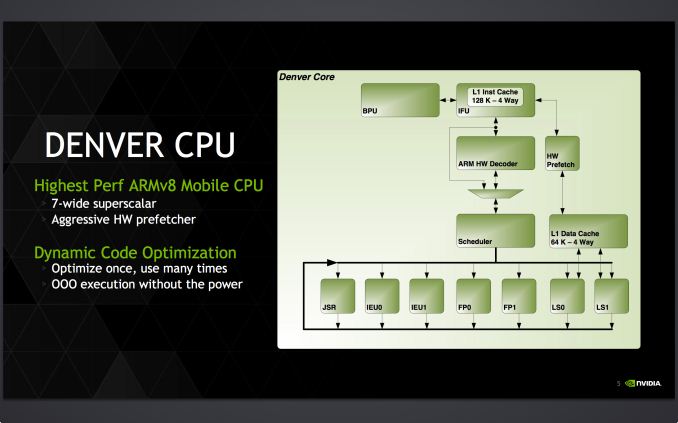
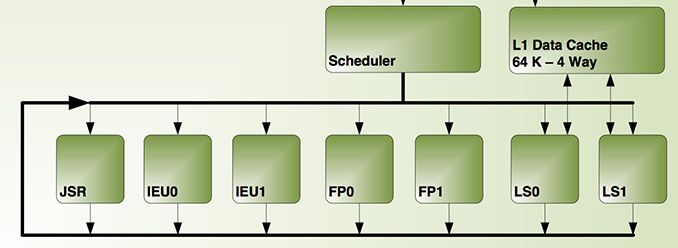
Инструкции Denver исполняются в формате VLIW (Very Long Instruction Word), или «очень длинная машинная команда») размером до 32 байт, что позволяет выполнять несколько операций (количество будет зависеть от их длины) за одну инструкцию. Причем формат этих инструкций сильно отличается как от ARMv7, так и от ARMv8 — настолько, что через несколько месяцев после анонса Denver появились слухи, что в нем реализована чуть ли не x86-архитектура (про отличие ARM/RISC и x86/CISC см. здесь). Для преобразования инструкций из этого формата в машинный код процессору требуется дополнительный декодер, который этот «x86»-подобный язык переводит в язык инструкций ARM.
Еще одной особенностью Denver является режим энергосбережения CC4, в рамках которого незанятый процессор частично выключается. Впрочем, согласно AnandTech, подобная технология применяется и в процессорах Cortex-A15. Подробнее с отличиями двух систем можно ознакомиться в таблице ниже:
| Tegra K1 (x32) | Tegra K1 (x64) | |
| Ядра ЦПУ | ARM Cortex-A15 | Nvidia Denver |
| ARM ISA | ARMv7 (32-битный) | ARMv8 (32/64-битный) |
| Инструкций за такт | 3 | 2 (формат ARM) или 7 (машинный формат) |
| Длина конвейера | 18 ступеней | 15 ступеней |
| Глубина ответвлений при неправильном предсказании переходов | 15 циклов | 13 циклов |
| Целочисленные ALU | 2 | 4 |
| Блоки загрузки/размещения | 1 + 1 (выделенные) | 2 (совместно используемые) |
| FP (с плавающей точкой)/NEON ALU | 2×64-битные | 2×128-битные |
| Кеш L1 | 32 Кб I$ + 32 Кб D$ | 128 Кб I$ + 64 Кб D$ |
| Кеш L2 | 2 Мб | 2 Мб |
Как мы уже рассказывали в прошлом обзоре архитектуры Denver, в рамках динамической оптимизации кода (DCO) процессор просматривает сотни инструкций ARM, «распутывает петли», переименовывает регистры, удаляет невостребованные инструкции и разными способами упорядочивает код для достижения оптимальной скорости его выполнения. Но осуществляется эта оптимизация только в том случае, если соответствующие фрагменты кода повторяются — в противном случае затрачиваемые на оптимизацию время и энергия будут расходоваться неэффективно. От эффективности работы DCO, реализуемой на программном уровне, будет в значительной степени зависеть производительность всего ЦПУ.
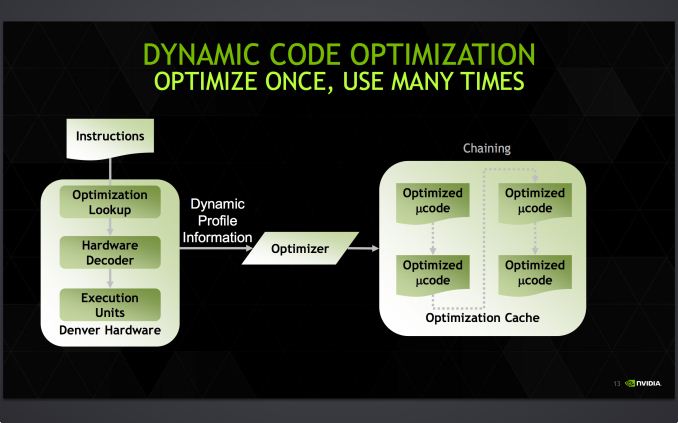
Оптимизированный код помещается в зарезервированный в ОЗУ кеш размером в 128 Мб, к которому в дальнейшем и обращается система.
Использованный Nvidia метод программной оптимизации кода отличает Denver от большинства других процессоров (где за это отвечает аппаратное выполнение инструкций не по порядку), и делает его более гибким с точки зрения усовершенствования и исправления ошибок в последующих прошивках. А без ошибок, к сожалению, не обошлось — наши коллеги из AnandTech выявили неисправленный DCO баг в операциях с плавающей точкой, который приводит к переполнению внутреннего регистра и сбросу ЦПУ. Это не имеет серьезных последствий в повседневной работе, но ставит владельцев Nexus 9 и других будущих моделей с архитектурой Denver в зависимость от оперативного выпуска прошивок с исправлениями.
Все вышесказанное относится к области теории — а как Nvidia Tegra K1 Denver показывает себя на практике? В специализированном «синтетическом» тесте SPECInt2000 он опередил своего соперника на 17-67%.
| Tegra K1 (x32) | Tegra K1 (x32) | Прирост | |
| 164.gzip |
869
|
1269
|
46%
|
| 175.vpr |
909
|
1312
|
44%
|
| 176.gcc |
1617
|
1884
|
17%
|
| 181.mcf |
1304
|
1746
|
34%
|
| 186.crafty |
1030
|
1470
|
43%
|
| 197.parser |
909
|
1192
|
31%
|
| 252.eon |
1940
|
2342
|
20%
|
| 253.perlbmk |
1395
|
1818
|
30%
|
| 254.gap |
1486
|
1844
|
24%
|
| 255.vortex |
1535
|
2567
|
67%
|
| 256.bzip2 |
1119
|
1468
|
31%
|
| 300.twolf |
1339
|
1785
|
33%
|
А вот в более реалистичных тестах результаты по сравнению с Nvidia Shield Tablet (который оснащен 32-разрядной версией Tegra K1) получились не столь однозначными:

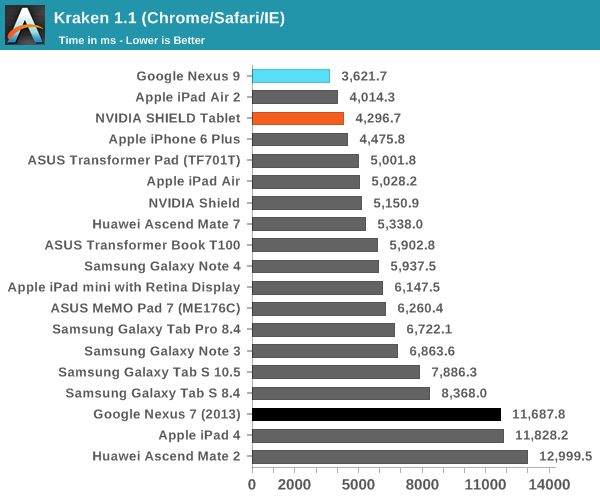
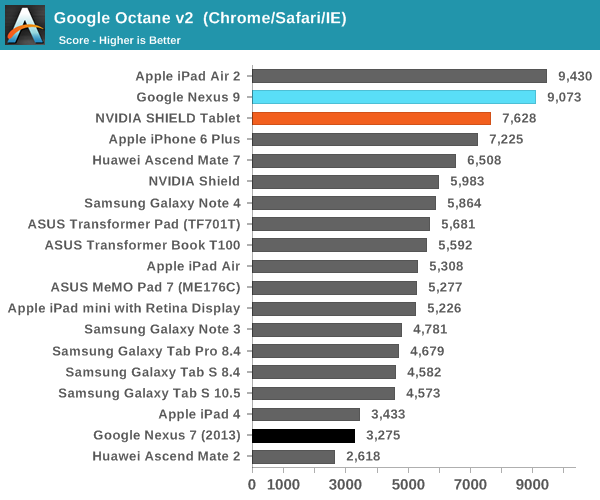
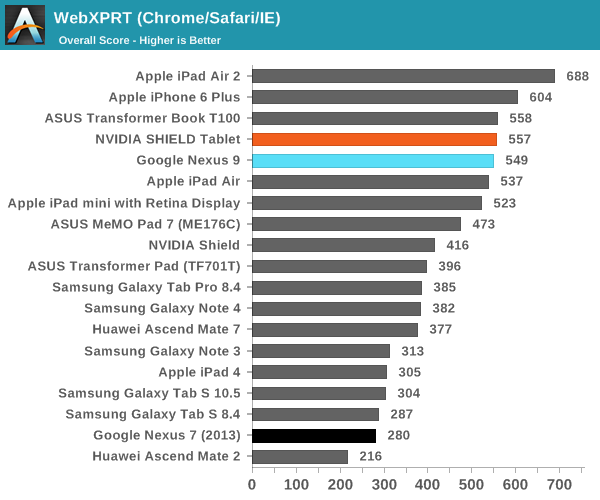
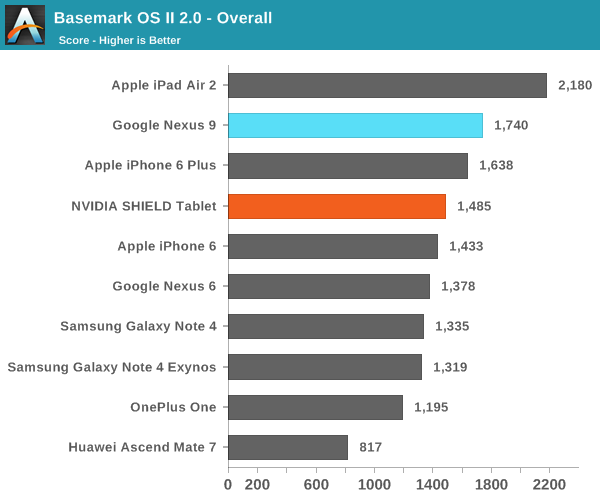
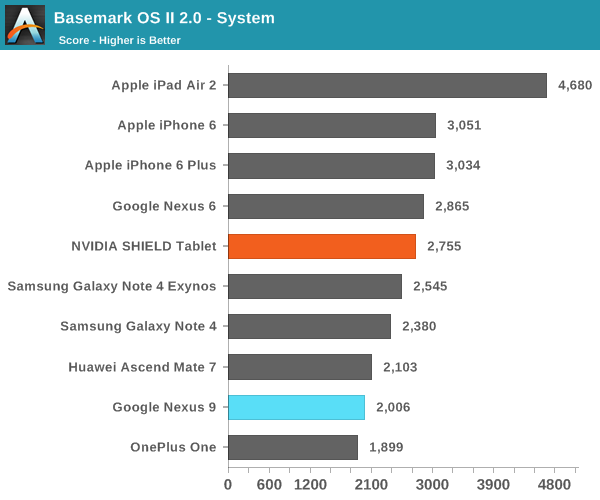
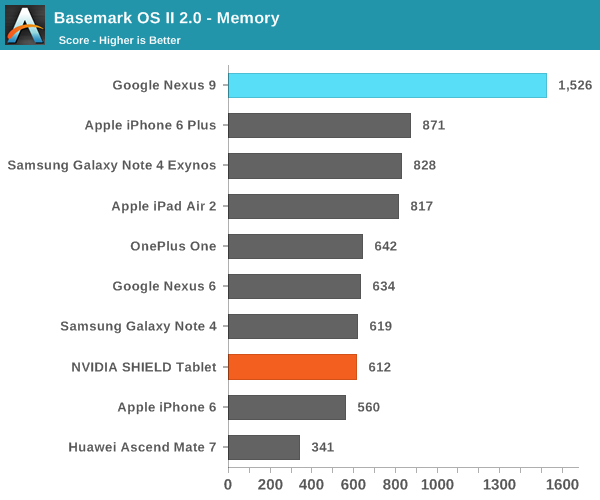
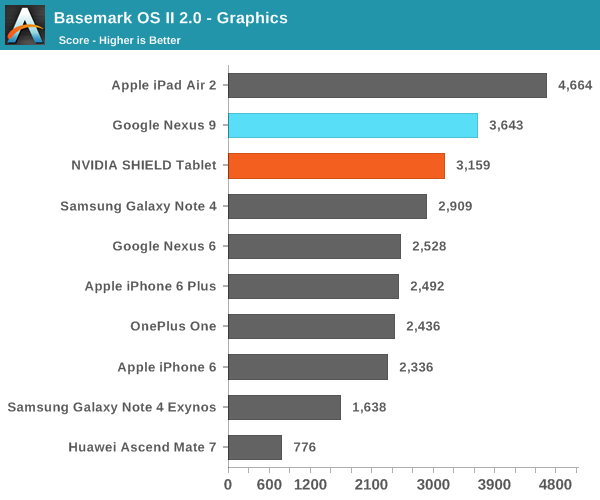
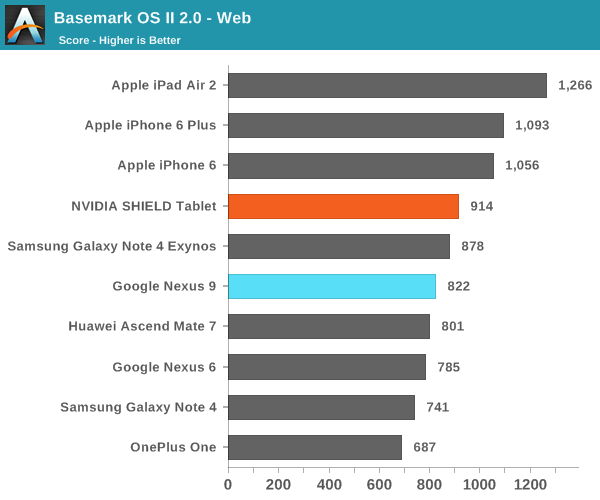
Как видим, в ряде тестов производительности ЦПУ планшет HTC Nexus 9 с процессором Tegra K1 Denver показал себя даже хуже 32-разрядного Nvidia Shied Tablet. Особенно это заметно в бенчмарке SunSpider. Объясняется это тем, что последний на современных ЦПУ выполняется очень быстро, время теста редко превышает 25 милисекунд — оптимизация кода DCO в таких условиях неэффективна. В более длительном и содержащем повторяющиеся инструкции тесте Kraken, напротив, оптимизация кода себя оправдывает, что дает весьма заметный прирост в производительности — даже по сравнению с iPad Air 2. При работе в многозадачном режиме, по наблюдениям авторов обзора AnandTech, периодически возникали задержки, а планшет нагревался даже при выполнении сравнительно простых задач.
Что касается графических тестов, то в традиционных GFXBench 3.0 Manhattan и T-Rex быстродействие Nexus 9 со времени первых данных немного улучшились в первом тесте, и весьма ощутимо — во втором:
| HTC Nexus 9 (новый) | HTC Nexus 9 (старый) | |
|---|---|---|
| GFXBench 3.0 Manhattan (offscreen) | 31.7 | 29.9 |
| GFXBench 3.0 Manhattan (onscreen) | 22.6 | 22.0 |
| GFXBench 3.0 T-Rex (offscreen) | 67.6 | 55.0 |
| GFXBench 3.0 T-Rex (onscreen) | 49.6 | 41.0 |
Соответственно и отставание Nexus 9 от iPad Air 2 в этих тестах, наилучшим образом воссоздающих нагрузки тяжелых трехмерных игр, стало совсем незначительным.
Каким будет будущее архитектуре Denver сейчас сказать трудно. Напомним, что в ЦПУ своего следующего и самого производительного на сегодня чипсета Tegra X1 компания Nvidia вновь вернулась к родным ядрам ARM (4 x Cortex-A57 + 4 x Cortex-A53). По всей видимости, это обусловлено тем, что Nvidia не успела перевести техпроцесс на 20-нанометровую топологию, которая используется в этих ядрах. Но делать это сейчас тоже вряд ли имеет смысл — на днях ARM анонсировала новое процессорное ядро с уже 16-нанометровой топологией — Cortex A-72. Если верить компании ARM, оно в 1.84 раза производительнее Cortex-A57 и потребляет при этом в 2 раза меньше электроэнергии. Поскольку преемник Tegra X1 будет, вероятно, анонсирован в начале 2016 года (а как раз в этом году стартует массовое производство Cortex A-72), Nvidia придется приложить немалые усилия, чтобы очередная модицификация Denver не уступала Cortex A-72.
С использованием материалов AnandTech