Nvidia vs Intel: чья платформа быстрее для машинного обучения? [обновлено]

Так называемый «бенчмаркетинг», когда производительность в тестах становится одним из инструментов рекламы, в т.ч. недобросовестной, практикуют не только производители смартфонов. Позавчера Nvidia опубликовала статью, в которой раскритиковала заявление Intel о том, что её новые (поколения Knights Landing) сопроцессоры Xeon Phi превосходят графические ускорители. Согласно Intel, четыре сопроцессора Xeon Phi в сети AlexNet обучаются в 2.3 раза быстрее четырех видеокарт, а их масштабируемость (повышение производительности по мере увеличения количества устройств в системе) в сети GoogleNet лучше на 38%.
На это Nvidia язвительно заметила, что технологии глубокого обучения быстро меняется, «поэтому понятно, что новички могут не знать обо всех наработках, имевших место в аппаратном и программном обеспечении«. Согласно компании, в более свежей версии AlexNet четыре видеокарты Titan X (Maxwell) обучаются на 30% быстрее четырех Xeon Phi, а четыре более современных Titan X (Pascal) — на 90%:
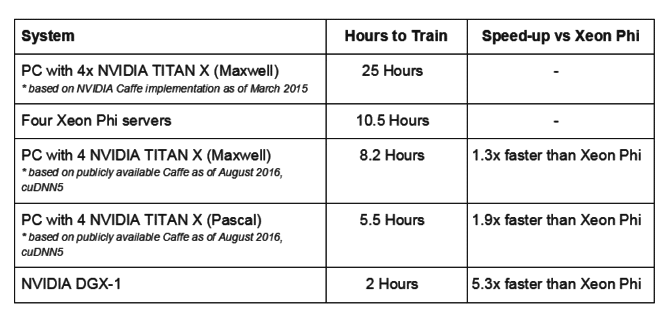
Как видно из таблицы, огромную роль в скорости обучения играет программное обеспечение — в марте 2015 обучение компьютера с четырьмя видеокартами Titan X (Maxwell) заняло 25 часов, а полтора года спустя, в августе 2016, в полтора раза меньше времени — 10.5 часов. Intel в своих данных о производительности четырех неназванных видеокарт Maxwell (как утверждает Nvidia — Titan X) указывает как раз 25 часов, и следовательно опирается на устаревшие данные.
Что касается масштабируемости, то согласно примечаниям самой Intel, сервер из 32 новейших Xeon Phi 7250 сравнивался с сервером из 32 Tesla K20X (ноябрь 2012), показав 87% эффективность новейших сопроцессоров Intel против 63% видеокарт Nvidia 4-летней давности. Сославшись на данные китайского поисковика Baidu, Nvidia утверждает, что на 128 видеокартах с архитектурой Maxwell (конкретные модели не называются) масштабируемость является почти линейной:
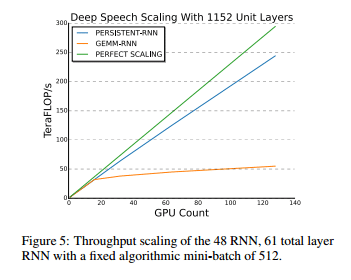
Примечательно, что Nvidia при этом не раскрывает подробных характеристик систем, на которых были получены эти результаты (включая конкретную модель тестируемого Xeon Phi). Будем надеяться, что по умолчанию использовалась та же Xeon Phi 7250, что была в тестах Intel, но с учетом по меньшей мере двух случаев не вполне добросовестного «бенчмаркетинга» Nvidia, я допускаю, что Nvidia могла запустить свой тест и на самой младшей модели, Xeon Phi 7210.

Любопытно также, что с профессиональными, специально созданными в т.ч. для задач машинного обучения, сопроцессорами Xeon Phi, Nvidia сравнивает игровые видеокарты Titan X, а не предназначенную для аналогичных целей Tesla P100, анонсированную в апреле этого года. Точнее говоря, Nvidia её сравнивает, но в рамках сервера Nvidia DGX-1, оснащенного восемью Tesla P100. Последний на днях был торжественно передан (см. фото сверху) OpenAI — некоммерческому проекту, который занимается исследованиями в области искусственного интеллекта. Я надеюсь безвозмездно, потому что стоит этот сервер $129 тысяч. Согласно Nvidia, по скорости обучения (2 ч) он в 5.3 раз превосходит четыре сервера, оснащенных по одному Xeon Phi (10.5 ч). Напомню, что компьютер из четырех видеокарт Titan X (Pascal) быстрее четырех Xeon Phi почти в 2 раза, на 90% (5.5 ч), а из четырех Titan X (Maxwell) — на 30% (8.2 ч).
И тут возникает интересный вопрос о цене достижения 5.3-кратного преимущества на сервере Nvidia DGX-1 — оно обойдется в $129 тысяч, тогда как компьютер Digits DevBox, оснащенный четырьмя видеокартами Titan X (Maxwell) стоит $15 тысяч. Получаем 2 часа обучения AlexNet за $129 тысяч ($64.5 тысяч за час) на DGX-1 и 8.2 часа — за $15 тысяч ($1.8 тысяч за час) на Digits DevBox.
Что касается Xeon Phi 7250, то оснащенный одним таким сопроцессором ($4,876) сервер по оценкам Intel будет стоить $7.3 тысяч, соответственно четыре сервера — $29.2 тысячи. При времени обучения 10.5 часов это дает $2.8 тысяч за час. Это вполне соразмерная с Digits DevBox сумма, тогда как себестоимость машинного обучения на Nvidia DGX-1 представляется просто заоблачной.
ОБНОВЛЕНИЕ
В ответной публикации Intel заявила, что «споры вокруг публично доступных бенчмарков производительности — потеря времени. Intel традиционно основывает свои утверждения на публично доступной на то время информации, и мы придерживаемся своих данных«. Компания также отметила тот красноречивый факт, что по её оценкам процессоры Intel установлены на 97% серверов, используемых для машинного обучения.